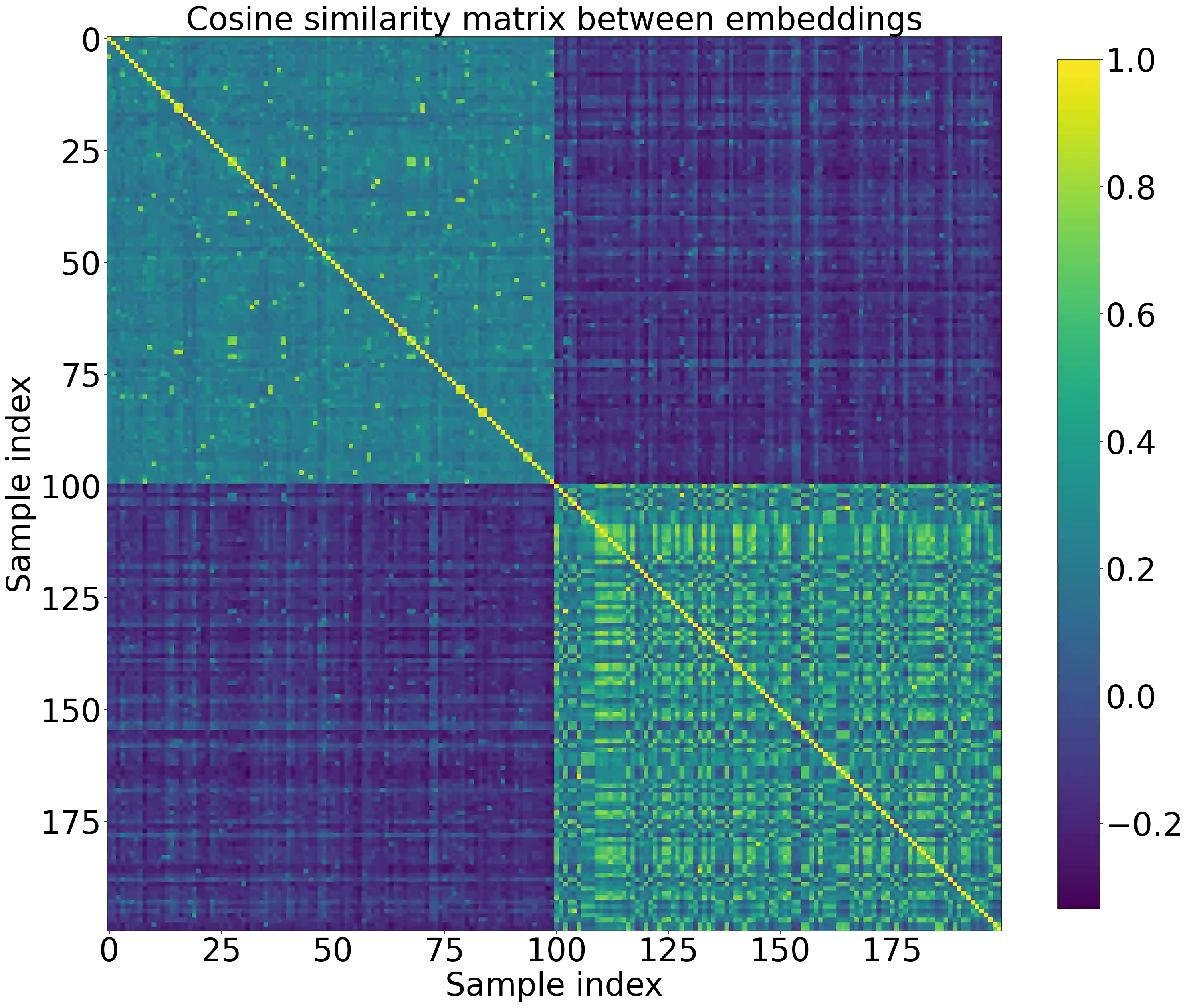
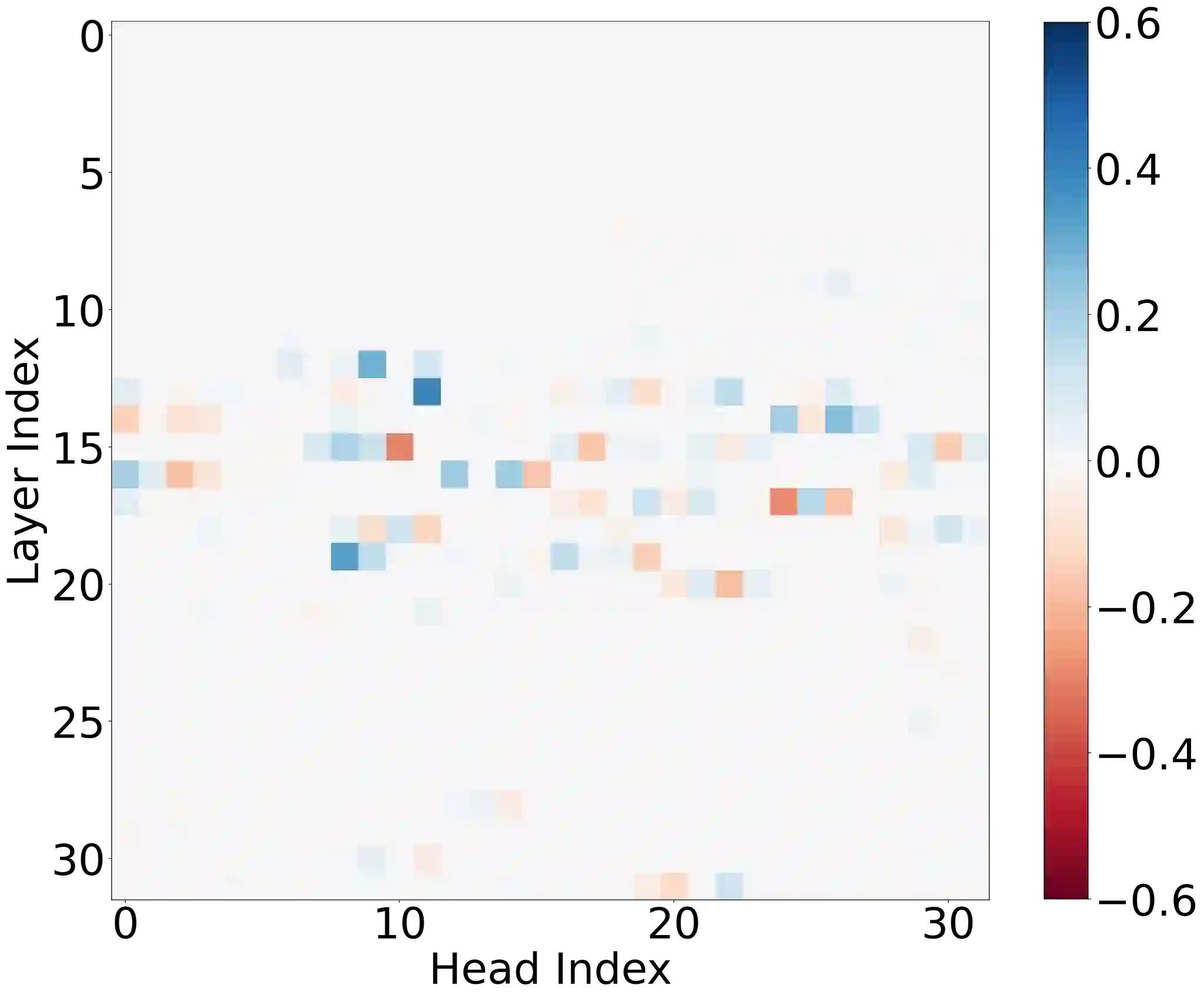Large language models (LLMs) have shown amazing performance on tasks that require planning and reasoning. Motivated by this, we investigate the internal mechanisms that underpin a network's ability to perform complex logical reasoning. We first construct a synthetic propositional logic problem that serves as a concrete test-bed for network training and evaluation. Crucially, this problem demands nontrivial planning to solve, but we can train a small transformer to achieve perfect accuracy. Building on our set-up, we then pursue an understanding of precisely how a three-layer transformer, trained from scratch, solves this problem. We are able to identify certain "planning" and "reasoning" circuits in the network that necessitate cooperation between the attention blocks to implement the desired logic. To expand our findings, we then study a larger model, Mistral 7B. Using activation patching, we characterize internal components that are critical in solving our logic problem. Overall, our work systemically uncovers novel aspects of small and large transformers, and continues the study of how they plan and reason.
翻译:大型语言模型(LLM)在需要规划和推理的任务上展现出惊人的性能。受此启发,我们研究了支撑网络执行复杂逻辑推理的内部机制。我们首先构建了一个合成的命题逻辑问题,作为网络训练和评估的具体测试平台。关键在于,该问题的解决需要非平凡的规划能力,但我们能够训练一个小型Transformer模型以达到完美准确率。基于我们的实验设置,我们进而深入探究一个从头开始训练的三层Transformer模型究竟如何解决此问题。我们成功识别出网络中某些“规划”和“推理”电路,这些电路需要注意力模块之间的协作来实现所需的逻辑。为了扩展我们的发现,我们随后研究了一个更大的模型——Mistral 7B。通过激活修补技术,我们刻画了在解决我们的逻辑问题中至关重要的内部组件。总体而言,我们的工作系统地揭示了小型和大型Transformer模型的新颖特性,并延续了关于它们如何进行规划和推理的研究。