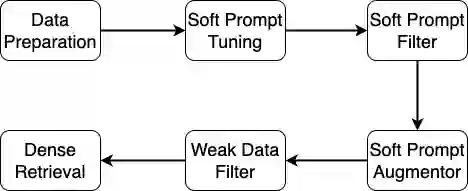
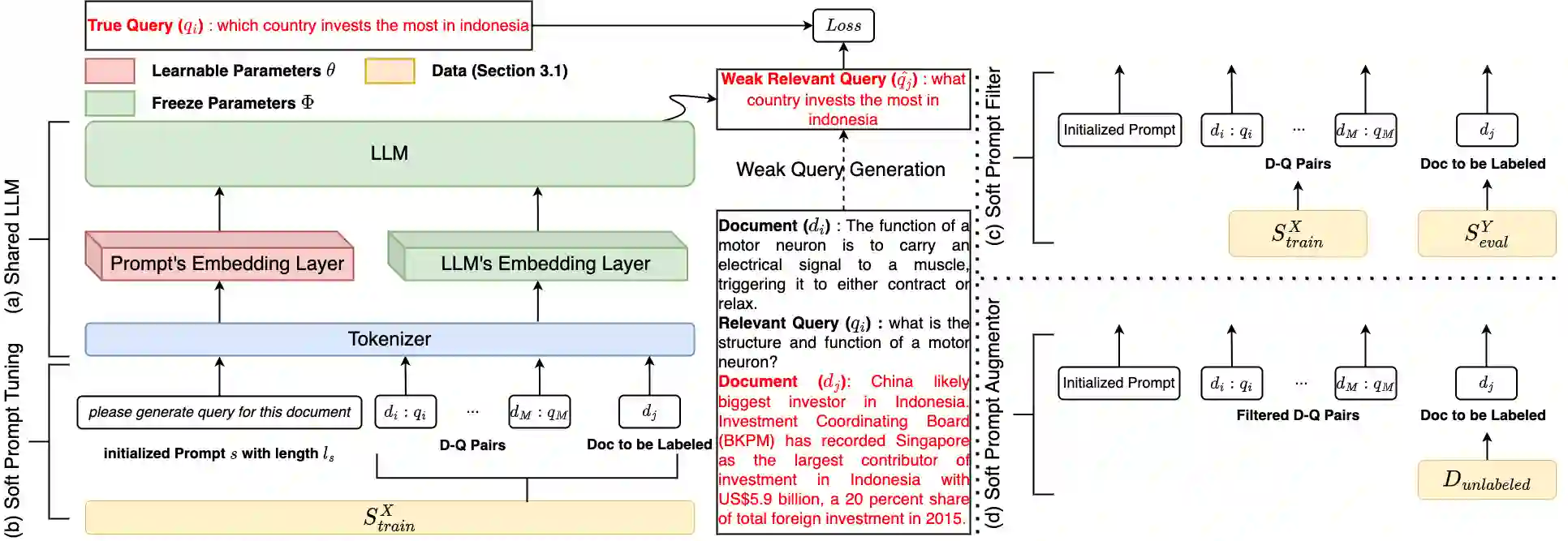
Dense retrieval (DR) converts queries and documents into dense embeddings and measures the similarity between queries and documents in vector space. One of the challenges in DR is the lack of domain-specific training data. While DR models can learn from large-scale public datasets like MS MARCO through transfer learning, evidence shows that not all DR models and domains can benefit from transfer learning equally. Recently, some researchers have resorted to large language models (LLMs) to improve the zero-shot and few-shot DR models. However, the hard prompts or human-written prompts utilized in these works cannot guarantee the good quality of generated weak queries. To tackle this, we propose soft prompt tuning for augmenting DR (SPTAR): For each task, we leverage soft prompt-tuning to optimize a task-specific soft prompt on limited ground truth data and then prompt the LLMs to tag unlabeled documents with weak queries, yielding enough weak document-query pairs to train task-specific dense retrievers. We design a filter to select high-quality example document-query pairs in the prompt to further improve the quality of weak tagged queries. To the best of our knowledge, there is no prior work utilizing soft prompt tuning to augment DR models. The experiments demonstrate that SPTAR outperforms the unsupervised baselines BM25 and the recently proposed LLMs-based augmentation method for DR.
翻译:密集检索(DR)将查询和文档转化为密集向量,并在向量空间中衡量查询与文档之间的相似性。密集检索面临的挑战之一是缺乏特定领域的训练数据。尽管密集检索模型可以通过迁移学习从MS MARCO等大规模公共数据集中学习,但证据表明,并非所有密集检索模型和领域都能平等地从迁移学习中受益。近期,一些研究人员借助大语言模型(LLMs)改进零样本和少样本密集检索模型。然而,这些工作中使用的硬提示或人工编写的提示无法保证生成的弱查询质量良好。为解决这一问题,我们提出针对密集检索增强的软提示调优(SPTAR):针对每个任务,我们在有限的真实数据上利用软提示调优优化任务特定的软提示,然后提示大语言模型用弱查询标记未标注文档,生成足够的弱文档-查询对,以训练特定任务的密集检索器。我们设计了一个过滤器,在提示中选择高质量示例文档-查询对,以进一步提高弱标记查询的质量。据我们所知,此前尚无利用软提示调优增强密集检索模型的工作。实验表明,SPTAR优于无监督基线BM25以及近期提出的基于大语言模型的密集检索增强方法。