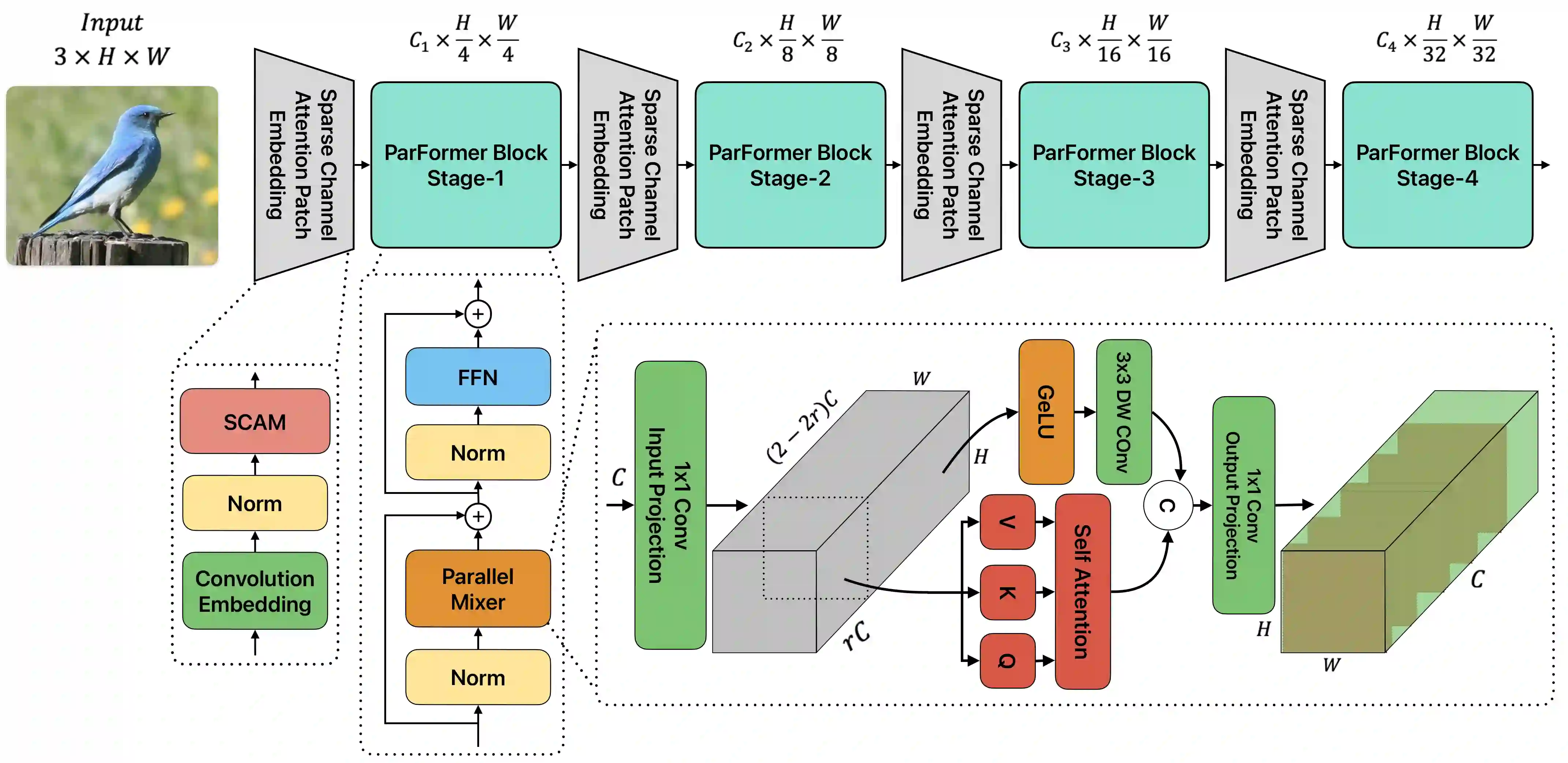
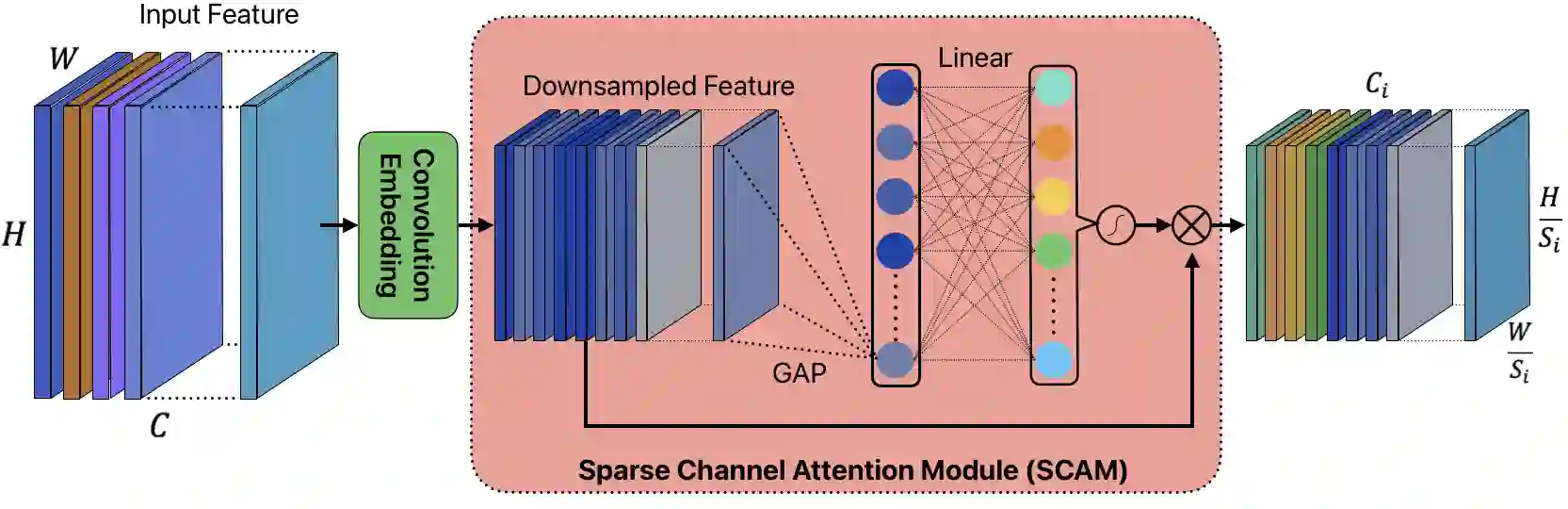
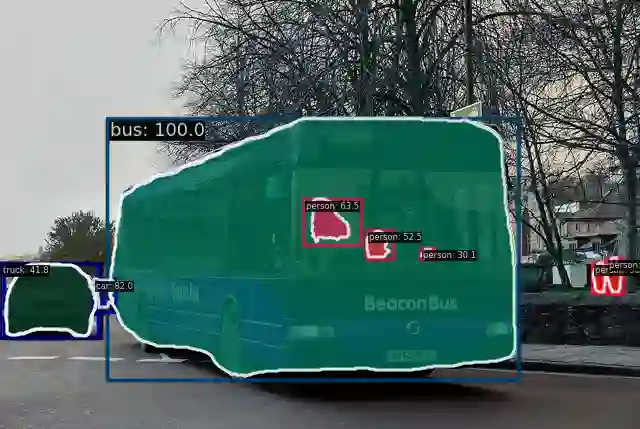
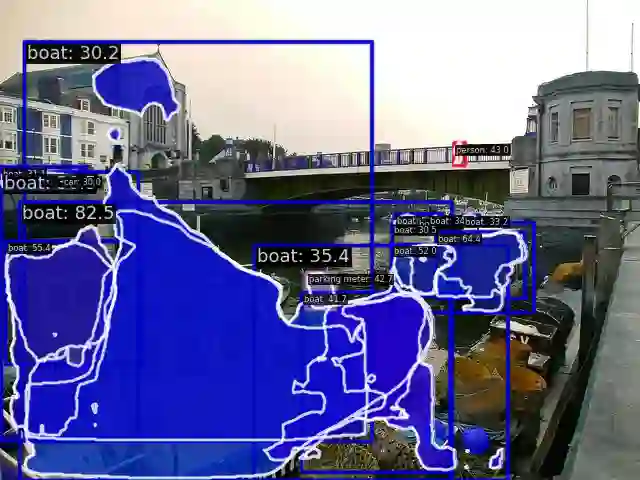
Convolutional Neural Networks (CNNs) and Transformers have achieved remarkable success in computer vision tasks. However, their deep architectures often lead to high computational redundancy, making them less suitable for resource-constrained environments, such as edge devices. This paper introduces ParFormer, a novel vision transformer that addresses this challenge by incorporating a Parallel Mixer and a Sparse Channel Attention Patch Embedding (SCAPE). By combining convolutional and attention mechanisms, ParFormer improves feature extraction. This makes spatial feature extraction more efficient and cuts down on unnecessary computation. The SCAPE module further reduces computational redundancy while preserving essential feature information during down-sampling. Experimental results on the ImageNet-1K dataset show that ParFormer-T achieves 78.9\% Top-1 accuracy with a high throughput on a GPU that outperforms other small models with 2.56$\times$ higher throughput than MobileViT-S, 0.24\% faster than FasterNet-T2, and 1.79$\times$ higher than EdgeNeXt-S. For edge device deployment, ParFormer-T excels with a throughput of 278.1 images/sec, which is 1.38 $\times$ higher than EdgeNeXt-S and 2.36$\times$ higher than MobileViT-S, making it highly suitable for real-time applications in resource-constrained settings. The larger variant, ParFormer-L, reaches 83.5\% Top-1 accuracy, offering a balanced trade-off between accuracy and efficiency, surpassing many state-of-the-art models. In COCO object detection, ParFormer-M achieves 40.7 AP for object detection and 37.6 AP for instance segmentation, surpassing models like ResNet-50, PVT-S and PoolFormer-S24 with significantly higher efficiency. These results validate ParFormer as a highly efficient and scalable model for both high-performance and resource-constrained scenarios, making it an ideal solution for edge-based AI applications.
翻译:卷积神经网络(CNN)与Transformer在计算机视觉任务中取得了显著成功。然而,其深层架构常导致较高的计算冗余,使其难以适用于资源受限环境(如边缘设备)。本文提出ParFormer,一种新颖的视觉Transformer,通过引入并行混合器与稀疏通道注意力块嵌入(SCAPE)模块应对这一挑战。ParFormer通过融合卷积与注意力机制,改进了特征提取能力,使空间特征提取更高效并减少了不必要的计算。SCAPE模块在保持关键特征信息的同时,进一步降低了下采样过程中的计算冗余。在ImageNet-1K数据集上的实验结果表明,ParFormer-T在GPU上实现了78.9%的Top-1准确率,且吞吐量显著优于其他轻量模型:其吞吐量达到MobileViT-S的2.56倍,比FasterNet-T2快0.24%,且比EdgeNeXt-S高1.79倍。在边缘设备部署中,ParFormer-T的吞吐量达到278.1张/秒,分别是EdgeNeXt-S和MobileViT-S的1.38倍与2.36倍,表明其非常适合资源受限环境下的实时应用。更大规模的变体ParFormer-L实现了83.5%的Top-1准确率,在精度与效率间取得了良好平衡,超越了众多先进模型。在COCO目标检测任务中,ParFormer-M实现了40.7 AP的目标检测精度与37.6 AP的实例分割精度,在显著提升效率的同时超越了ResNet-50、PVT-S及PoolFormer-S24等模型。这些结果验证了ParFormer在高性能与资源受限场景下均具备高效性与可扩展性,是边缘AI应用的理想解决方案。