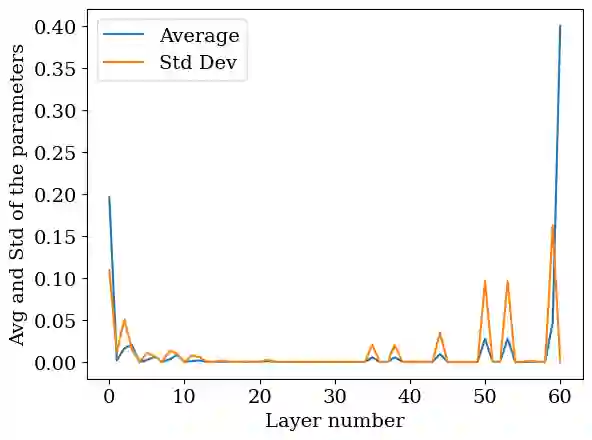
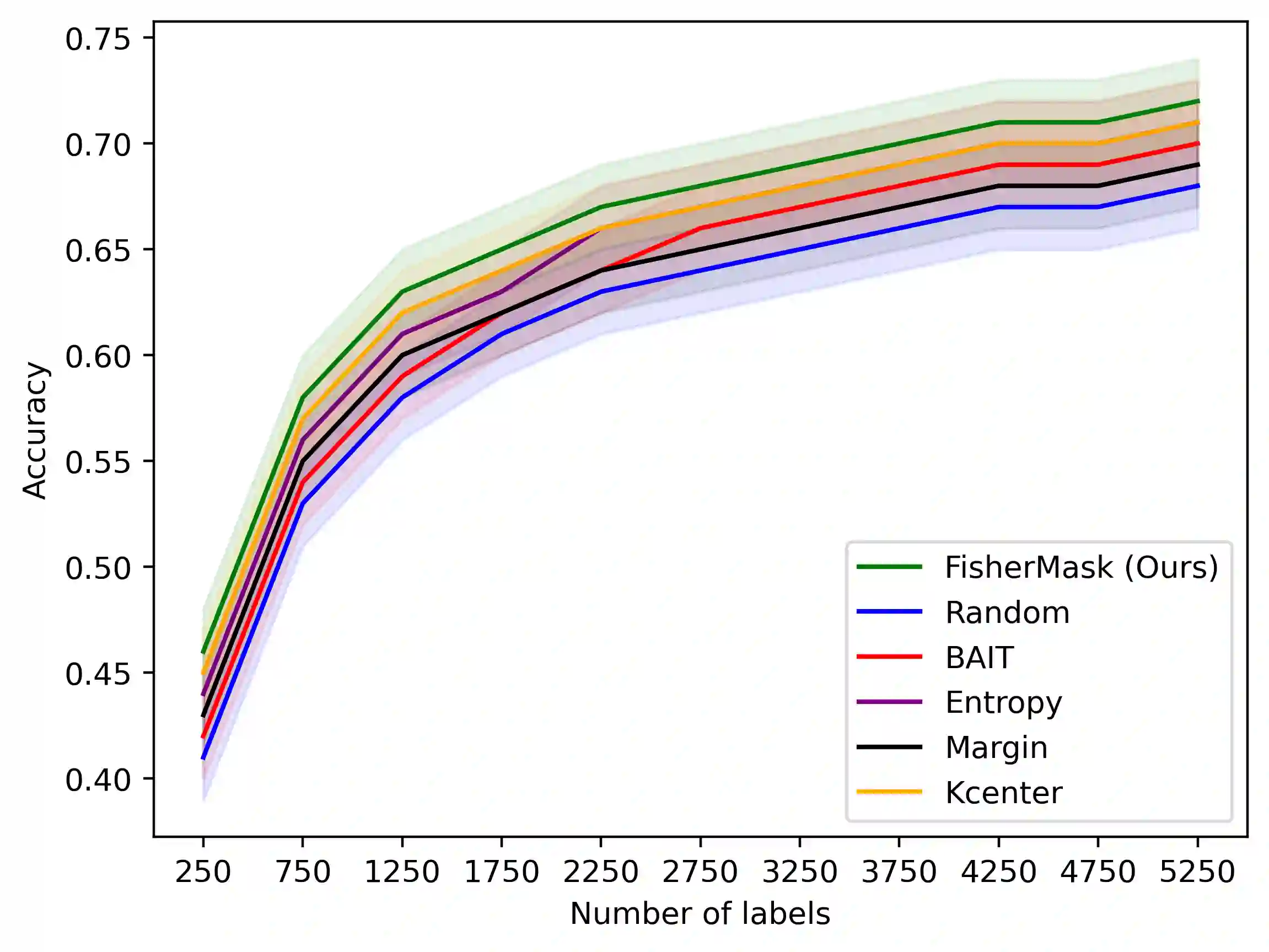
Deep learning (DL) models are popular across various domains due to their remarkable performance and efficiency. However, their effectiveness relies heavily on large amounts of labeled data, which are often time-consuming and labor-intensive to generate manually. To overcome this challenge, it is essential to develop strategies that reduce reliance on extensive labeled data while preserving model performance. In this paper, we propose FisherMask, a Fisher information-based active learning (AL) approach that identifies key network parameters by masking them based on their Fisher information values. FisherMask enhances batch AL by using Fisher information to select the most critical parameters, allowing the identification of the most impactful samples during AL training. Moreover, Fisher information possesses favorable statistical properties, offering valuable insights into model behavior and providing a better understanding of the performance characteristics within the AL pipeline. Our extensive experiments demonstrate that FisherMask significantly outperforms state-of-the-art methods on diverse datasets, including CIFAR-10 and FashionMNIST, especially under imbalanced settings. These improvements lead to substantial gains in labeling efficiency. Hence serving as an effective tool to measure the sensitivity of model parameters to data samples. Our code is available on \url{https://github.com/sgchr273/FisherMask}.
翻译:深度学习(DL)模型因其卓越的性能和效率在各个领域广受欢迎。然而,其有效性在很大程度上依赖于大量标注数据,而人工生成这些数据通常耗时且费力。为克服这一挑战,必须开发能够减少对大量标注数据依赖、同时保持模型性能的策略。本文提出FisherMask,一种基于Fisher信息的主动学习(AL)方法,该方法通过根据参数的Fisher信息值进行掩码来识别关键网络参数。FisherMask利用Fisher信息选择最关键参数,从而增强批量主动学习,使得在AL训练过程中能够识别最具影响力的样本。此外,Fisher信息具有良好的统计特性,能够为模型行为提供有价值的洞见,并帮助更好地理解AL流程中的性能特征。我们的大量实验表明,FisherMask在包括CIFAR-10和FashionMNIST在内的多种数据集上显著优于现有最先进方法,尤其是在不平衡设置下。这些改进带来了标注效率的大幅提升。因此,该方法可作为衡量模型参数对数据样本敏感性的有效工具。我们的代码发布于\url{https://github.com/sgchr273/FisherMask}。