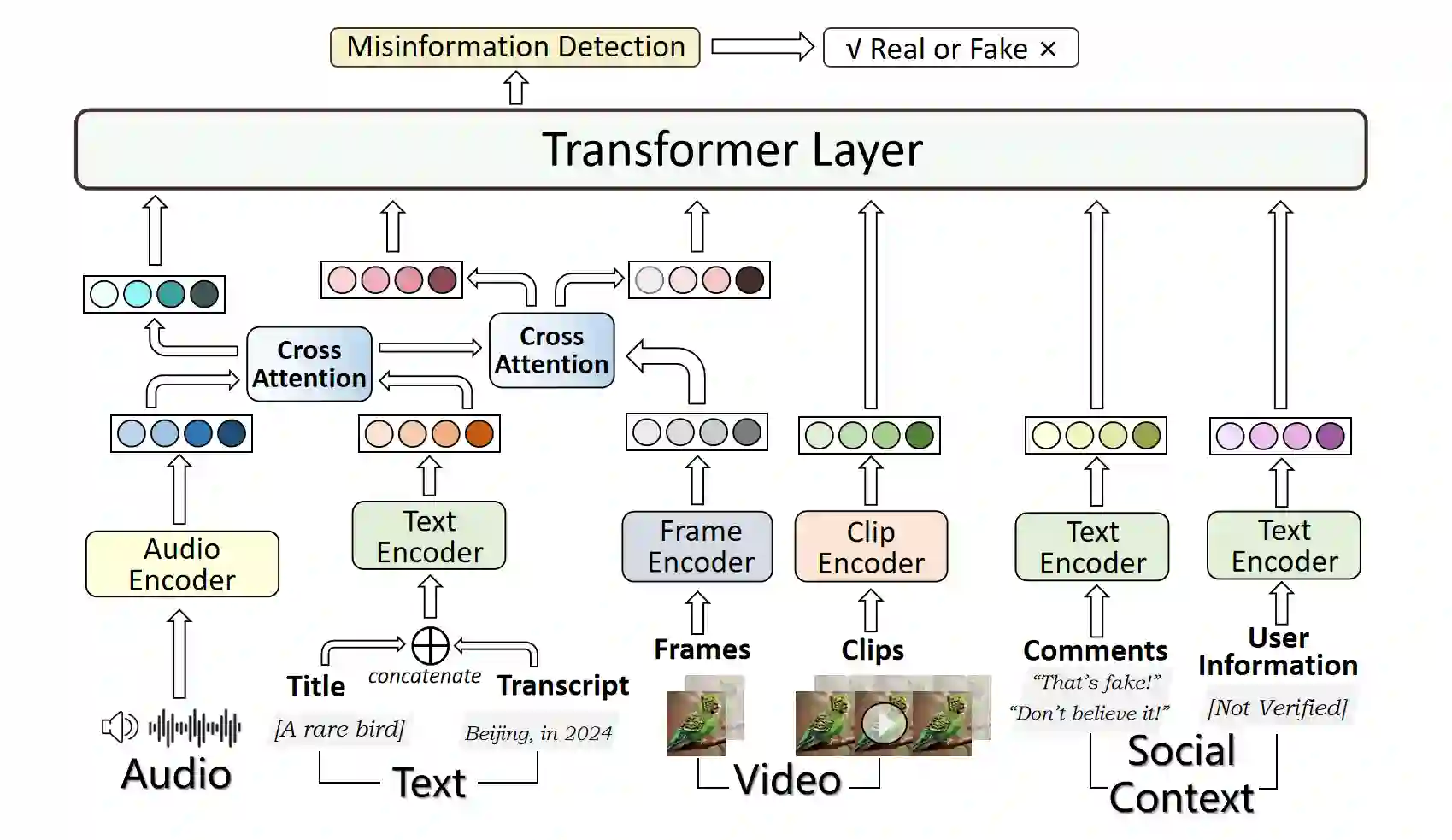
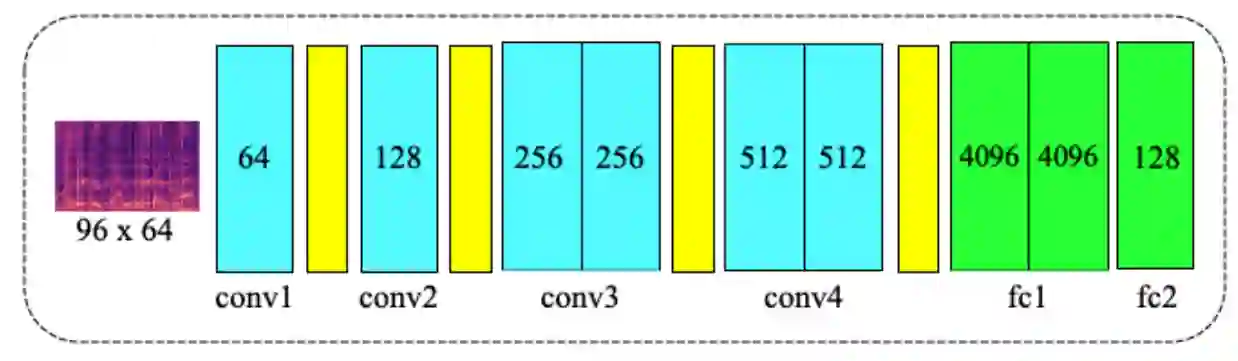
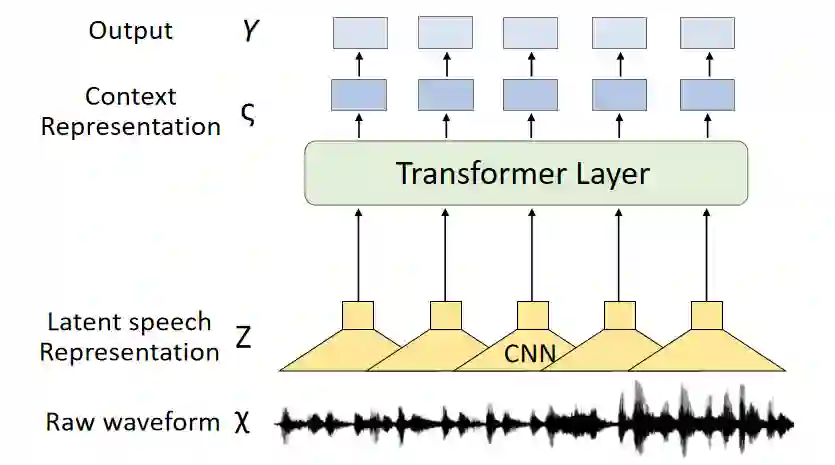
With the rapid development of deepfake technology, especially the deep audio fake technology, misinformation detection on the social media scene meets a great challenge. Social media data often contains multimodal information which includes audio, video, text, and images. However, existing multimodal misinformation detection methods tend to focus only on some of these modalities, failing to comprehensively address information from all modalities. To comprehensively address the various modal information that may appear on social media, this paper constructs a comprehensive multimodal misinformation detection framework. By employing corresponding neural network encoders for each modality, the framework can fuse different modality information and support the multimodal misinformation detection task. Based on the constructed framework, this paper explores the importance of the audio modality in multimodal misinformation detection tasks on social media. By adjusting the architecture of the acoustic encoder, the effectiveness of different acoustic feature encoders in the multimodal misinformation detection tasks is investigated. Furthermore, this paper discovers that audio and video information must be carefully aligned, otherwise the misalignment across different audio and video modalities can severely impair the model performance.
翻译:随着深度伪造技术,特别是深度音频伪造技术的快速发展,社交媒体场景下的虚假信息检测面临巨大挑战。社交媒体数据通常包含音频、视频、文本和图像等多模态信息。然而,现有的多模态虚假信息检测方法往往仅关注其中部分模态,未能全面处理所有模态的信息。为全面应对社交媒体上可能出现的各类模态信息,本文构建了一个综合性的多模态虚假信息检测框架。该框架通过为每种模态采用相应的神经网络编码器,能够融合不同模态信息,并支持多模态虚假信息检测任务。基于所构建的框架,本文探究了音频模态在社交媒体多模态虚假信息检测任务中的重要性。通过调整声学编码器的架构,研究了不同声学特征编码器在多模态虚假信息检测任务中的有效性。此外,本文发现音频与视频信息必须仔细对齐,否则不同音频与视频模态间的错位会严重损害模型性能。