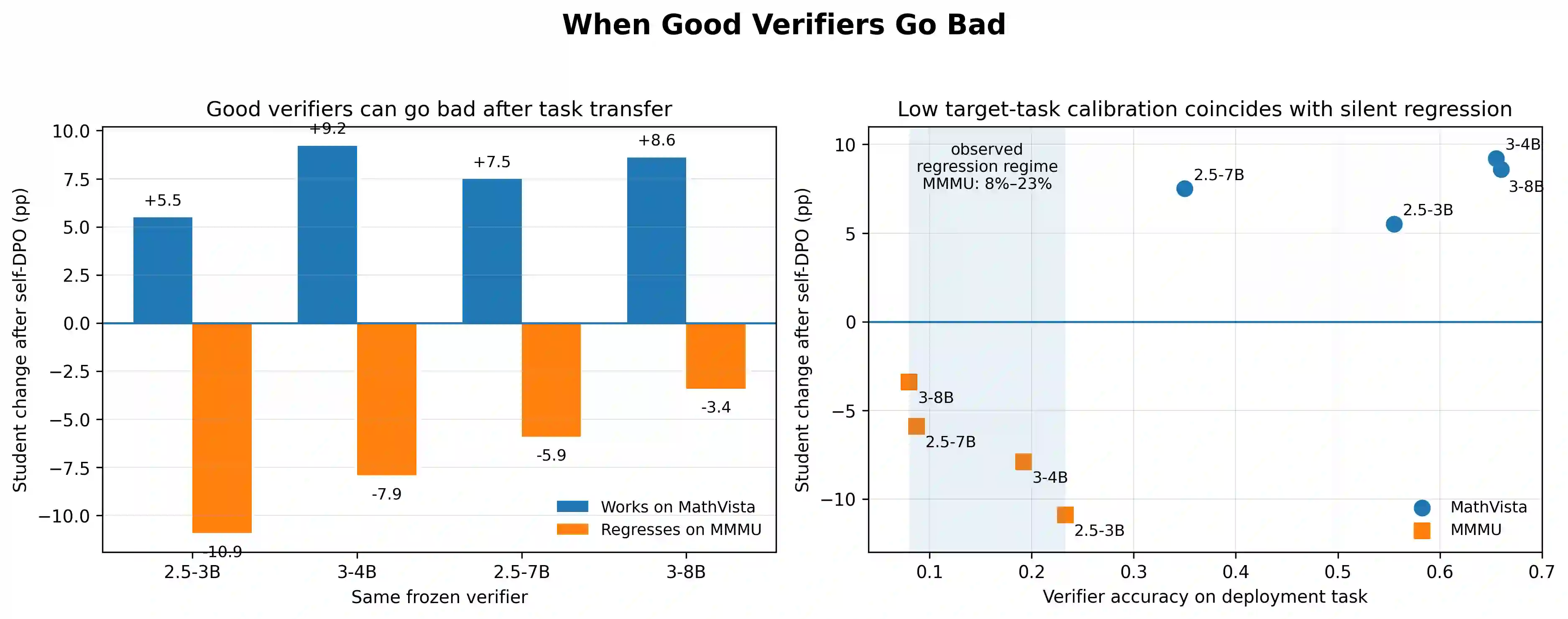
Verifier-driven self-DPO is a common recipe for self-improving production visual-language models. In this setup, a frozen verifier scores candidate generations, the top- and bottom-scoring candidates form a preference example, and DPO updates the learner. The deployment-time assumption is monotone: a stronger verifier should yield a stronger student. We show that this assumption can fail because verifier quality is highly task-specific. On a four-rung open-source verifier ladder across MathVista, MMMU, and BLINK, the same verifiers that are above-threshold and improve a Qwen-3-VL-2B student on MathVista become sub-threshold on MMMU, where their task-rubric accuracy drops to 8% to 23%. In this regime, every verifier we tested silently regresses the student, producing drops of 3.4 to 10.9 percentage points below the frozen baseline while the DPO training loss continues to decrease. The regression replicates on a second student, Qwen-2.5-VL-3B. Moreover, within the failure regime, damage is confidence-inverted: the more accurate-but-still-wrong verifier causes larger regression than a near-random verifier, suggesting that progress-gated replay amplifies confidently wrong preference pairs. We give a compact mechanistic explanation via a variance theorem for progress-gated replay and its direction-mismatch failure mode. The deployment message is operational rather than purely diagnostic: before running any verifier-driven loop, teams should measure target-task rubric accuracy, rank verifiers by target-task rubric quality rather than parameter count, and treat diminishing returns in above-threshold regimes as a verifier-side compute budget cap.
翻译:验证器驱动的自我DPO是生产级视觉语言模型自我提升的常见方法。在此设置中,冻结的验证器对候选生成结果进行评分,得分最高和最低的候选结果构成偏好样本,DPO更新学习器。部署时的假设是单调的:更强的验证器应产生更强的学生模型。我们证明这一假设可能失效,因为验证器质量具有高度任务特异性。在MathVista、MMMU和BLINK上搭建的四级开源验证器阶梯中,同样的验证器在MathVista上达到阈值并提升Qwen-3-VL-2B学生模型性能,但在MMMU上低于阈值,其任务评分准确率降至8%至23%。在此情况下,我们测试的所有验证器都会无声地导致学生模型性能倒退,使其低于冻结基线3.4至10.9个百分点,而DPO训练损失持续下降。这种倒退在第二个学生模型Qwen-2.5-VL-3B上得到复现。此外,在失效区间内,损害与置信度呈反比:更准确但仍错误的验证器比近乎随机的验证器导致更大的性能倒退,这表明进步门控重放放大了错误置信的偏好对。我们通过进步门控重放的方差定理及其方向失配失效模式,给出了紧凑的机制解释。这一定位信息具有操作指导意义而不仅是诊断价值:在运行任何验证器驱动循环之前,团队应测量目标任务评分准确率,根据目标任务评分质量而非参数数量对验证器排序,并将阈值区间内的收益递减视为验证器侧的计算预算上限。