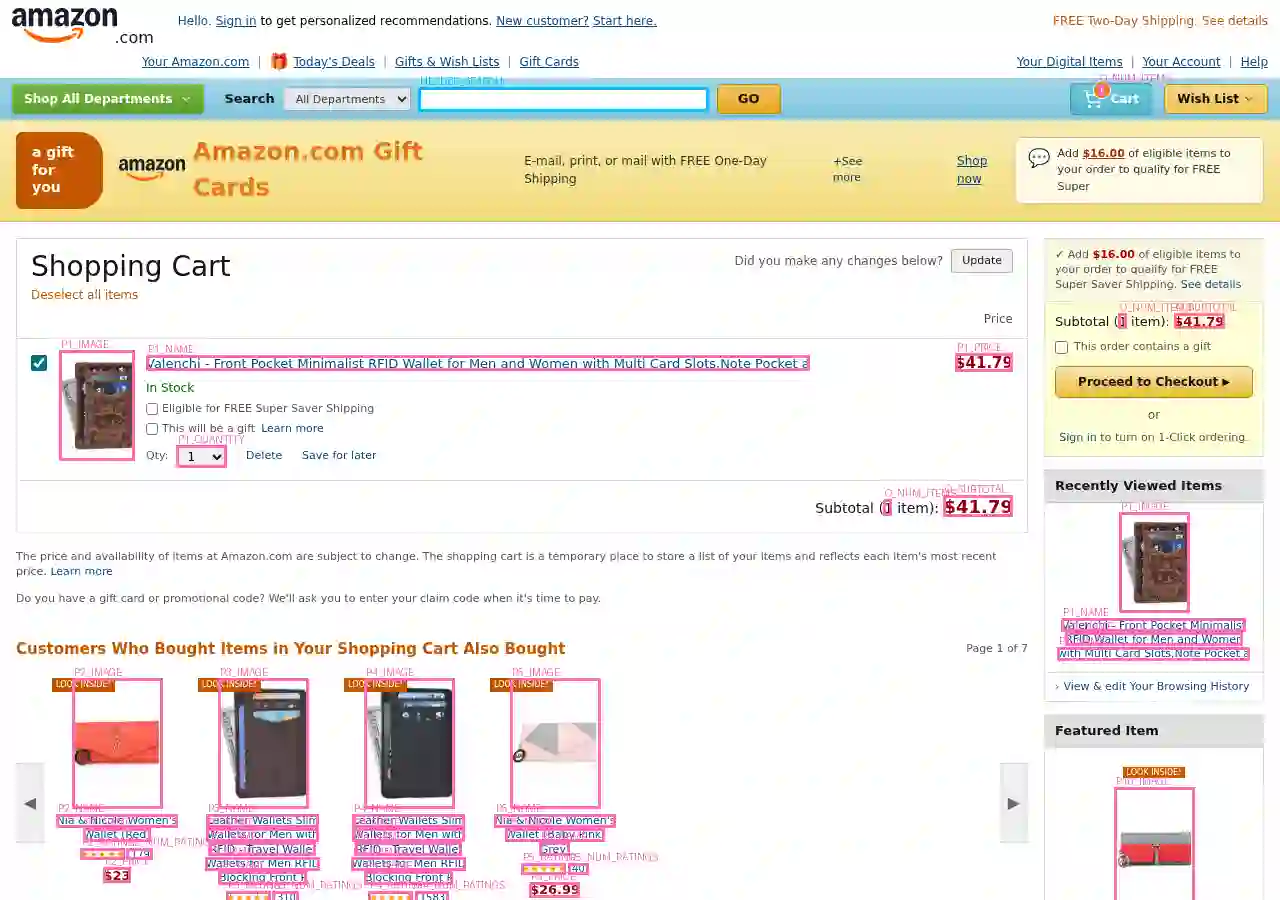
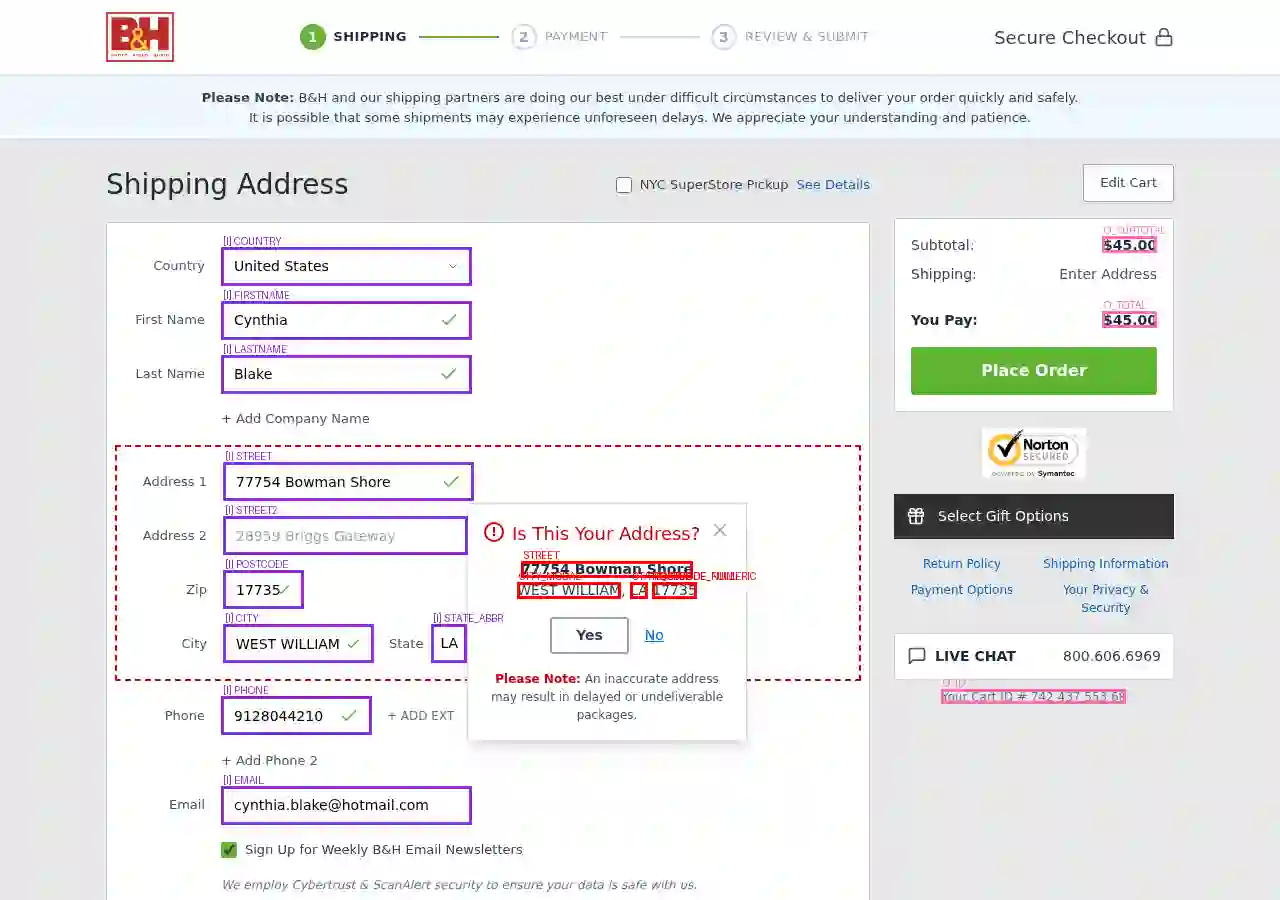
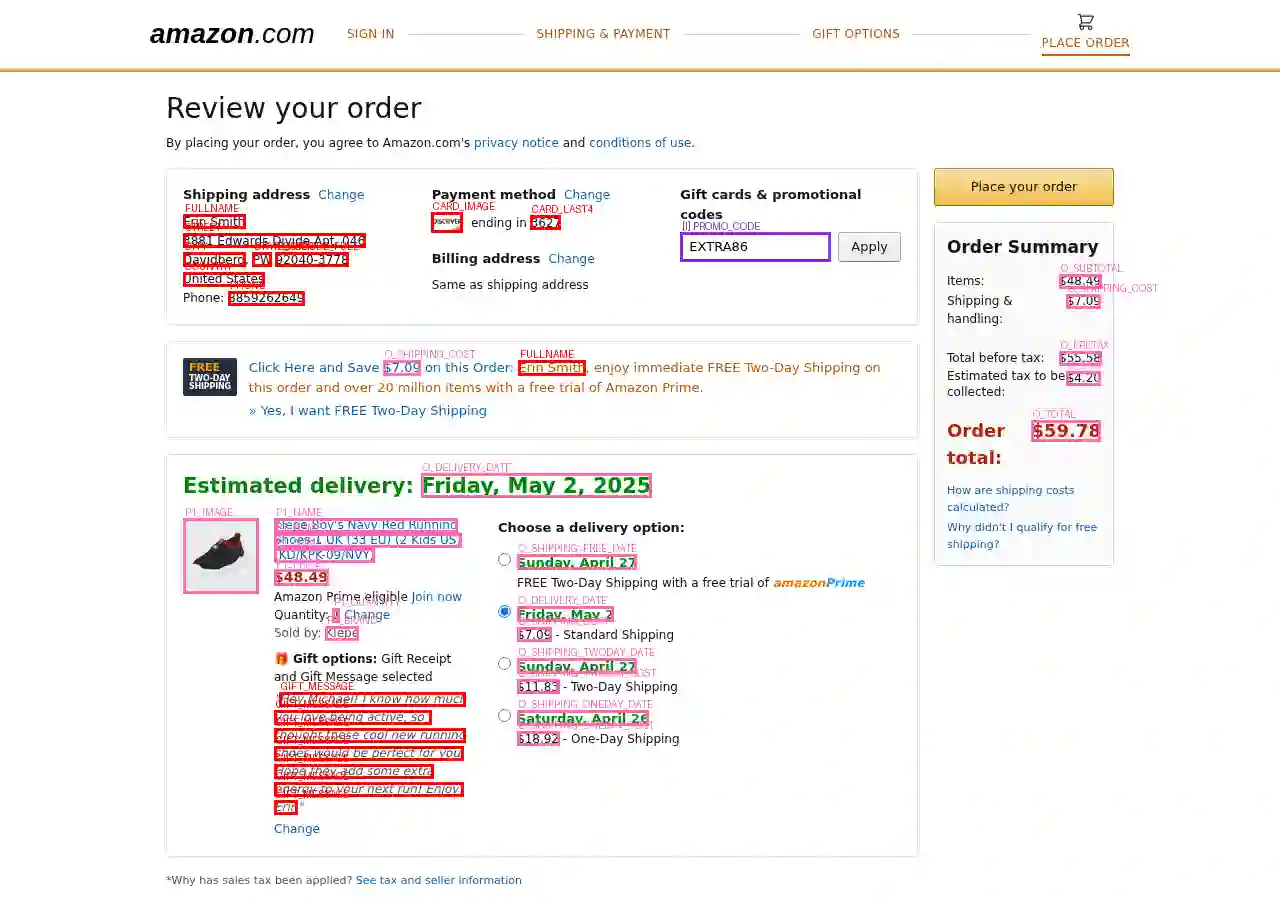
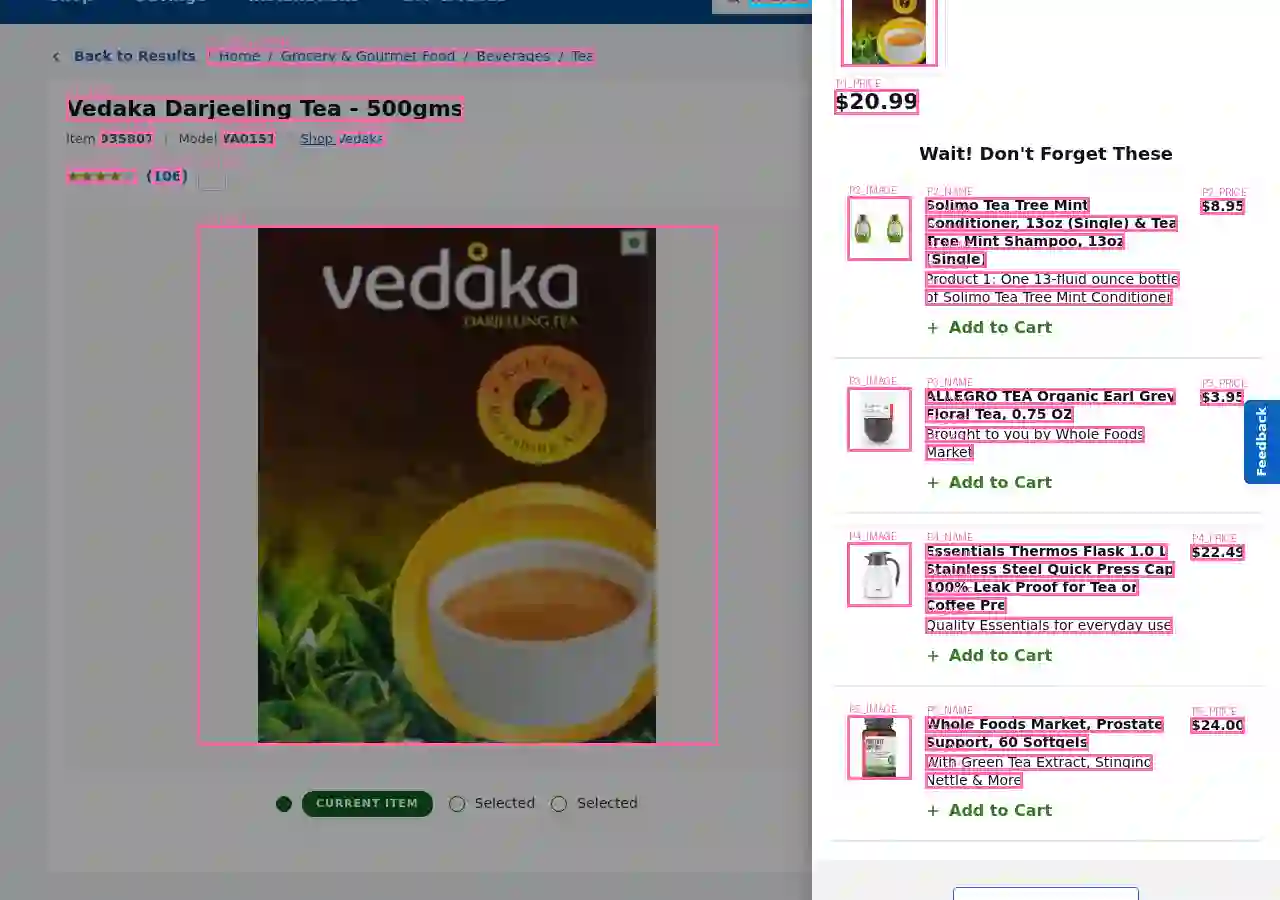
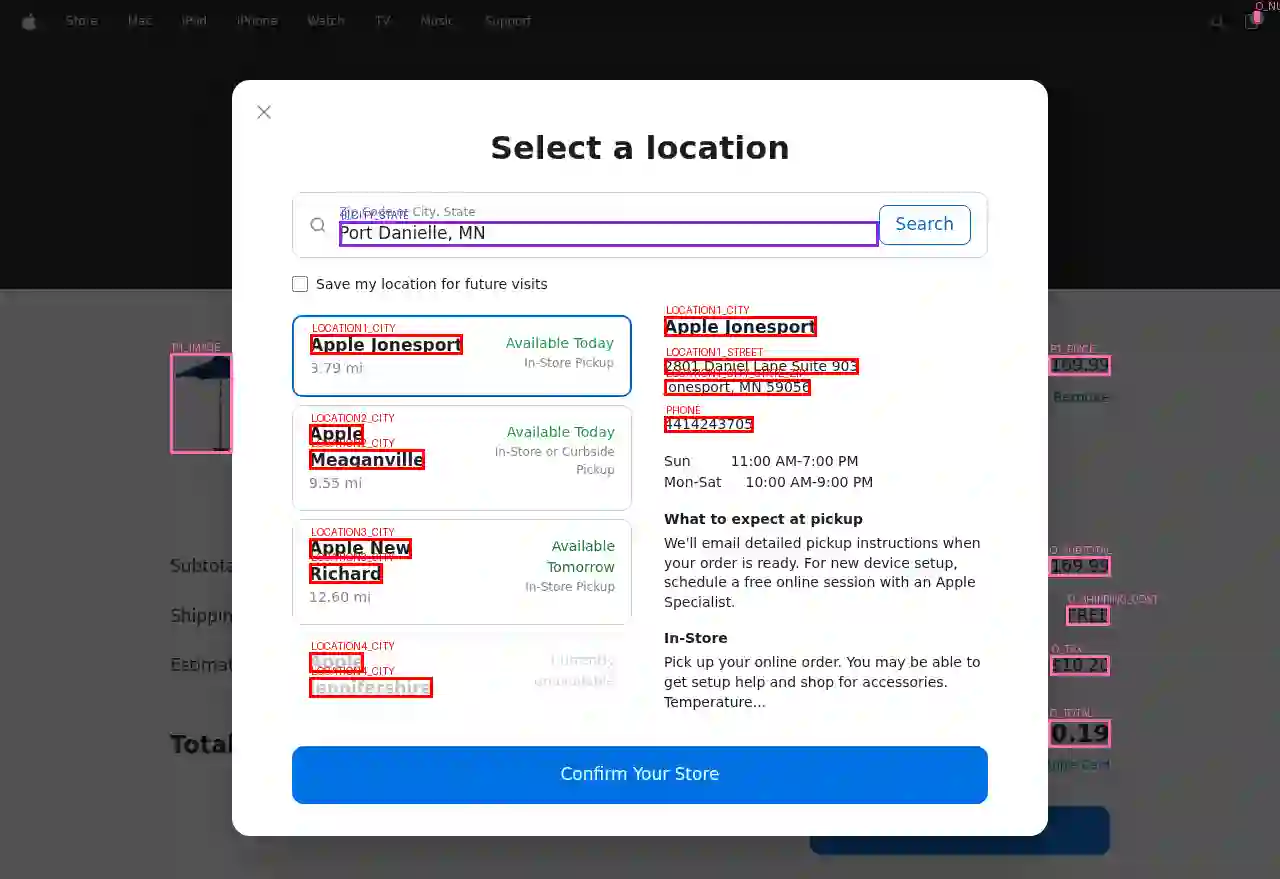
Computer use agents create new privacy risks: training data collected from real websites inevitably contains sensitive information, and cloud-hosted inference exposes user screenshots. Detecting personally identifiable information in web screenshots is critical for privacy-preserving deployment, but no public benchmark exists for this task. We introduce WebPII, a fine-grained synthetic benchmark of 44,865 annotated e-commerce UI images designed with three key properties: extended PII taxonomy including transaction-level identifiers that enable reidentification, anticipatory detection for partially-filled forms where users are actively entering data, and scalable generation through VLM-based UI reproduction. Experiments validate that these design choices improve layout-invariant detection across diverse interfaces and generalization to held-out page types. We train WebRedact to demonstrate practical utility, more than doubling text-extraction baseline accuracy (0.753 vs 0.357 mAP@50) at real-time CPU latency (20ms). We release the dataset and model to support privacy-preserving computer use research.
翻译:计算机使用代理带来了新的隐私风险:从真实网站收集的训练数据不可避免地包含敏感信息,而云端托管的推理过程会暴露用户截图。检测网页截图中的个人身份信息对于隐私保护部署至关重要,但目前该任务缺乏公开基准。我们提出了WebPII,这是一个包含44,865张带标注电子商务UI图像的细粒度合成基准数据集,其设计具有三个关键特性:扩展的PII分类体系(包含可实现再识别的交易级标识符)、针对用户正在填写数据的部分填充表单的预见性检测,以及通过基于VLM的UI复现实现的可扩展生成。实验验证表明,这些设计选择提升了跨多样界面的布局无关检测能力以及对未见过页面类型的泛化性能。我们训练了WebRedact模型以展示其实用价值,在实时CPU延迟(20毫秒)下,其文本提取基线准确率提升超过一倍(mAP@50达到0.753,基线为0.357)。我们公开数据集与模型,以支持隐私保护的计算机使用研究。