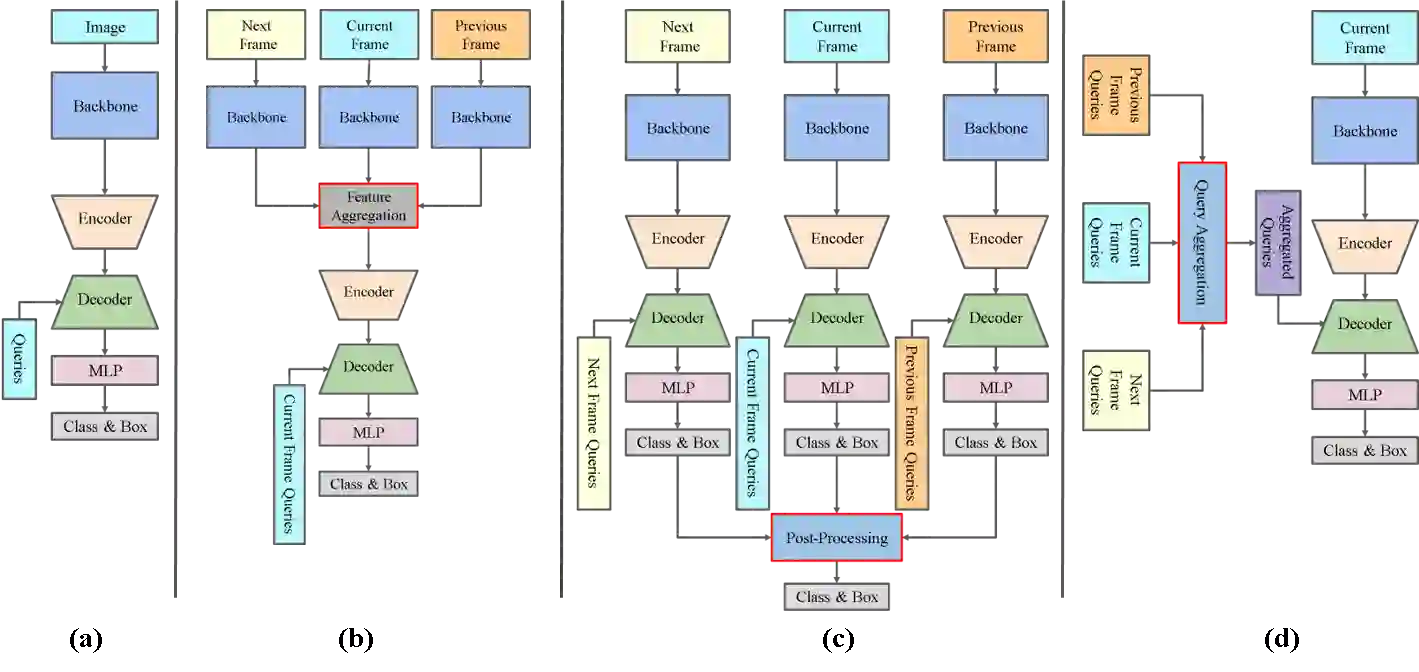
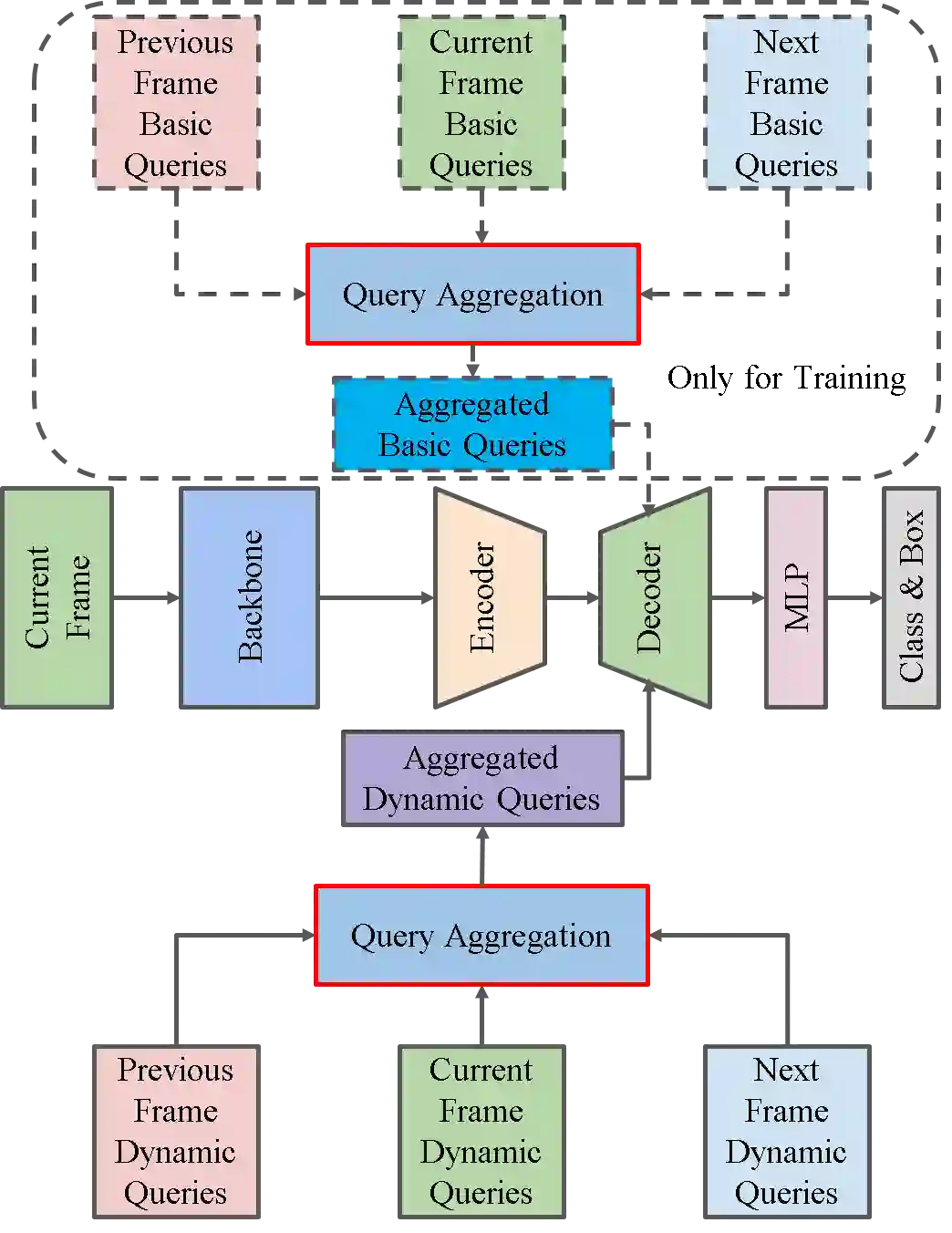
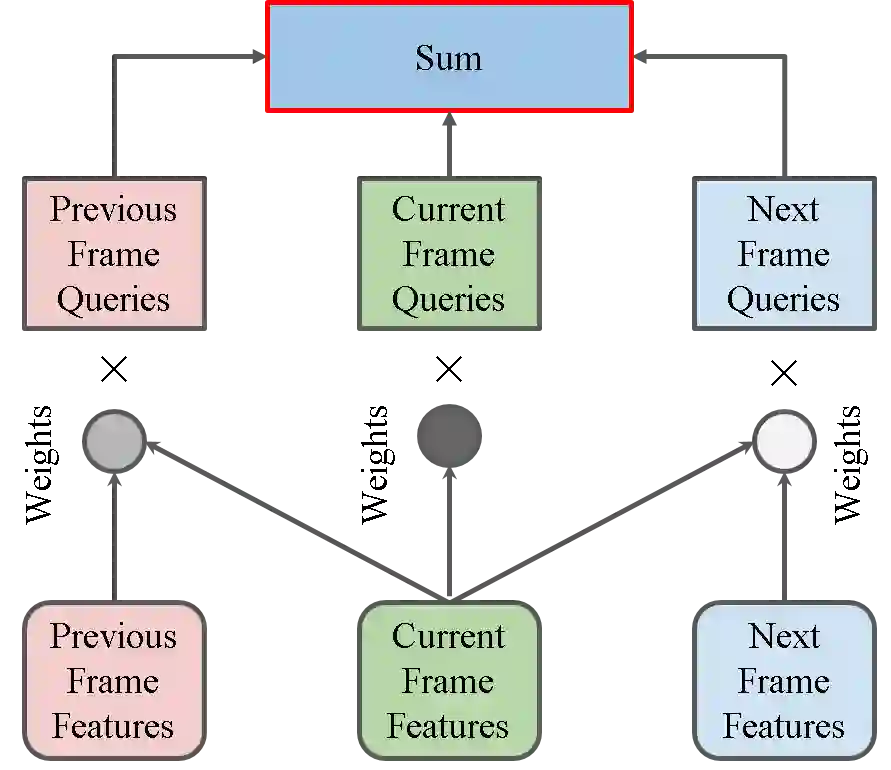
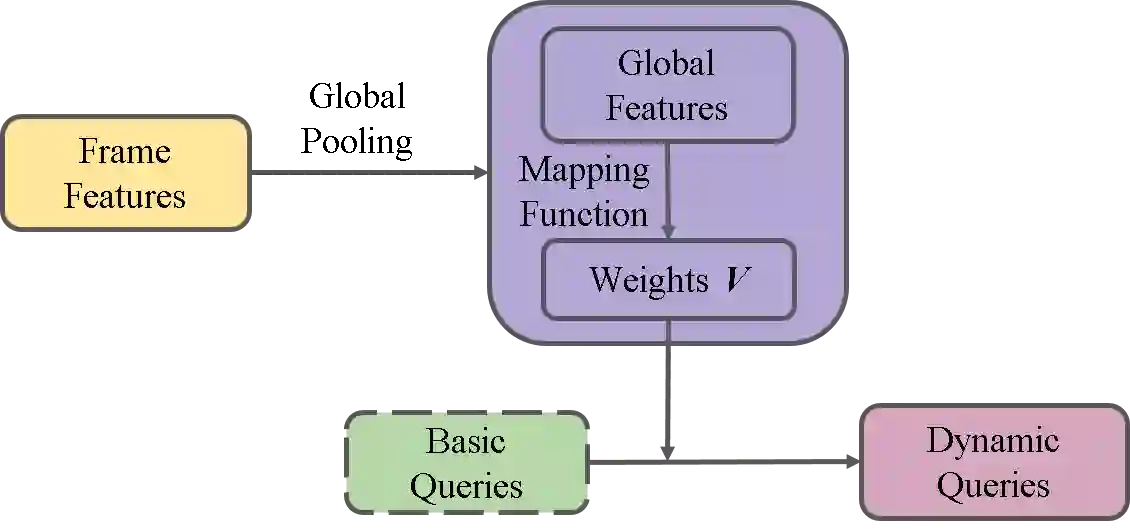
Video object detection needs to solve feature degradation situations that rarely happen in the image domain. One solution is to use the temporal information and fuse the features from the neighboring frames. With Transformerbased object detectors getting a better performance on the image domain tasks, recent works began to extend those methods to video object detection. However, those existing Transformer-based video object detectors still follow the same pipeline as those used for classical object detectors, like enhancing the object feature representations by aggregation. In this work, we take a different perspective on video object detection. In detail, we improve the qualities of queries for the Transformer-based models by aggregation. To achieve this goal, we first propose a vanilla query aggregation module that weighted averages the queries according to the features of the neighboring frames. Then, we extend the vanilla module to a more practical version, which generates and aggregates queries according to the features of the input frames. Extensive experimental results validate the effectiveness of our proposed methods: On the challenging ImageNet VID benchmark, when integrated with our proposed modules, the current state-of-the-art Transformer-based object detectors can be improved by more than 2.4% on mAP and 4.2% on AP50.
翻译:视频目标检测需解决图像领域鲜少出现的特征退化问题。一种解决方案是利用时序信息,融合相邻帧的特征。随着基于Transformer的目标检测器在图像领域任务中取得更优性能,近期研究开始将此类方法拓展至视频目标检测。然而,现有基于Transformer的视频目标检测器仍沿用经典目标检测器的流水线,例如通过聚合增强目标特征表示。本文从不同视角切入视频目标检测:具体而言,我们通过聚合提升Transformer模型中查询的质量。为实现该目标,我们首先提出一种朴素查询聚合模块,根据相邻帧特征对查询进行加权平均。随后,我们将该朴素模块扩展为更实用的版本,根据输入帧特征生成并聚合查询。大量实验结果验证了所提方法的有效性:在具有挑战性的ImageNet VID基准测试中,集成所提模块后,当前最先进的基于Transformer的目标检测器在mAP上提升超过2.4%,在AP50上提升超过4.2%。