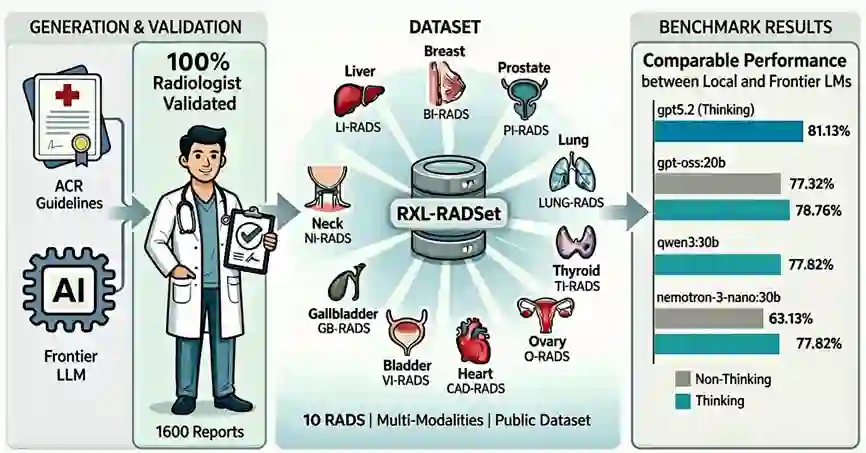
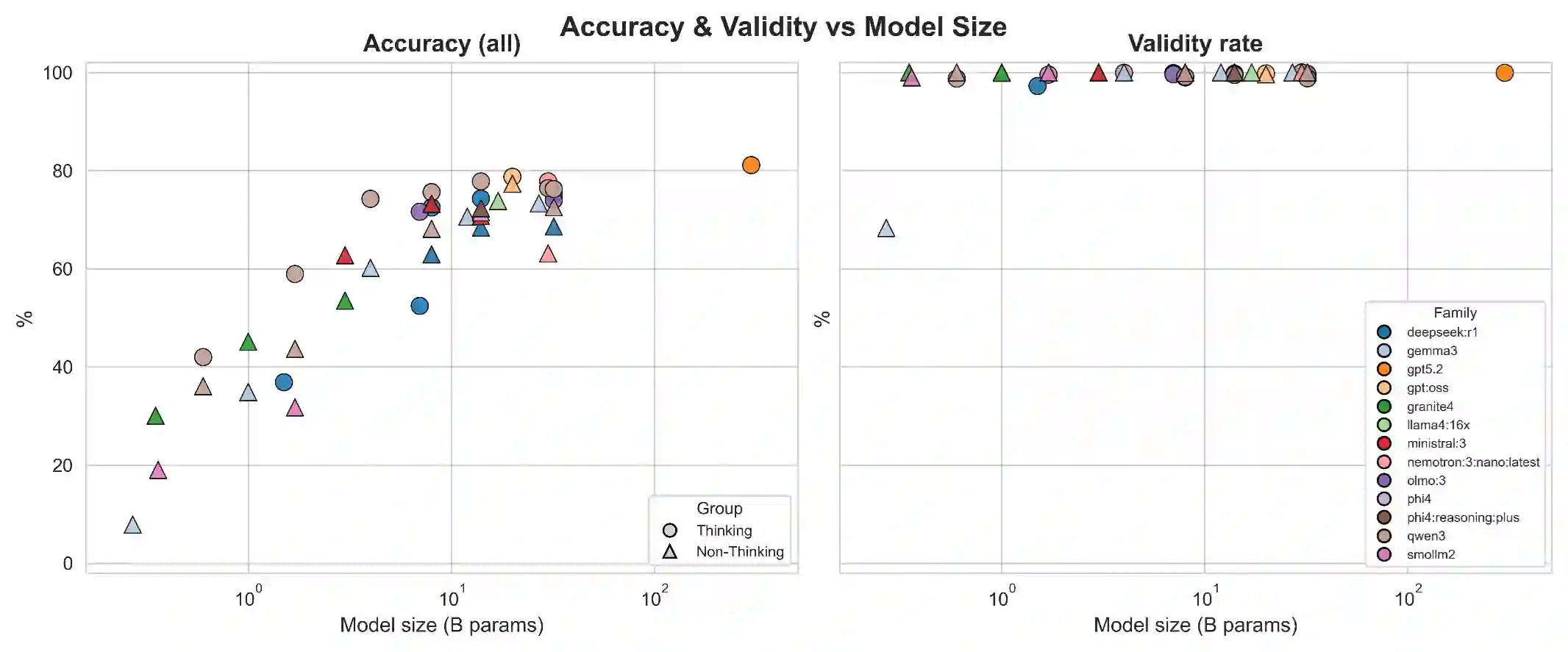
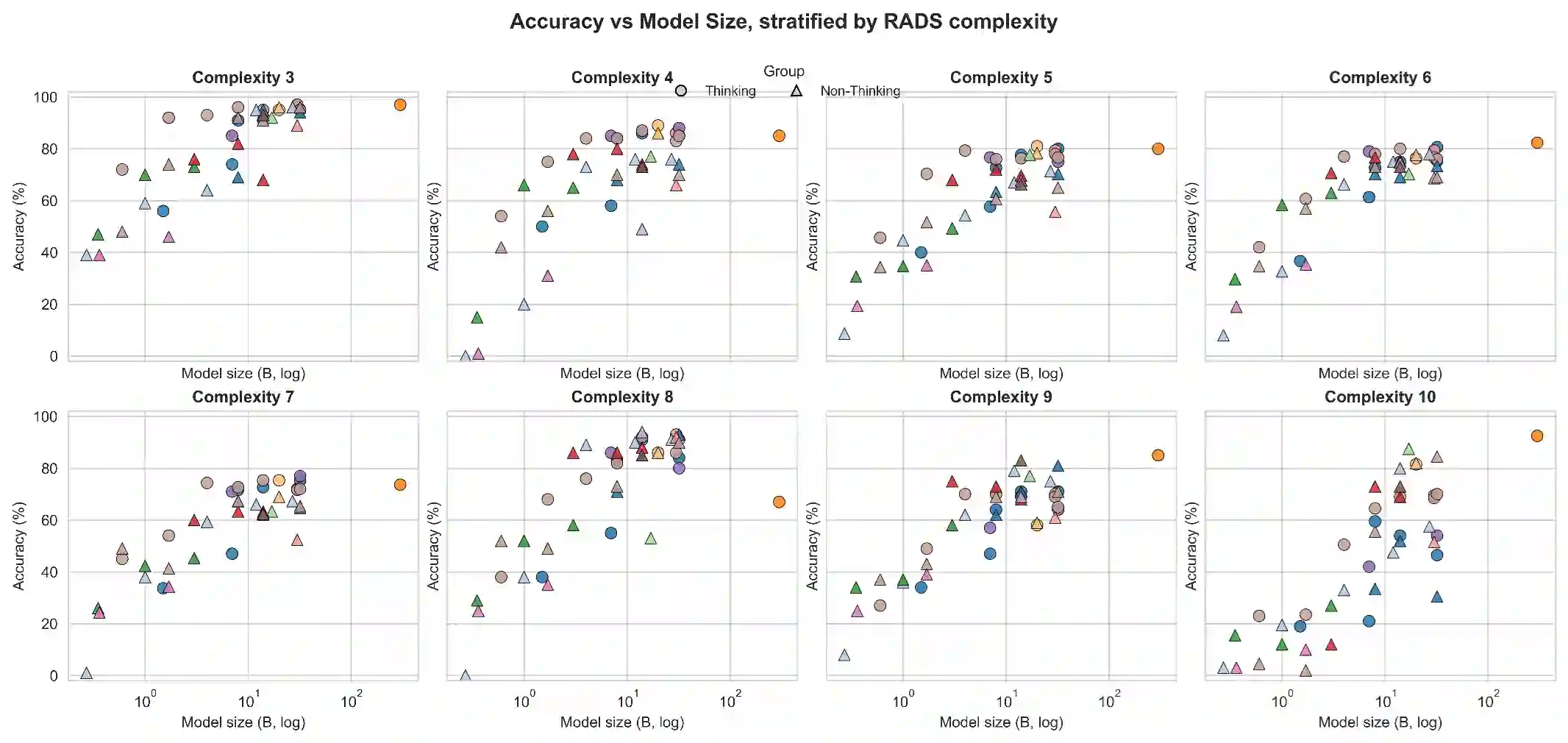
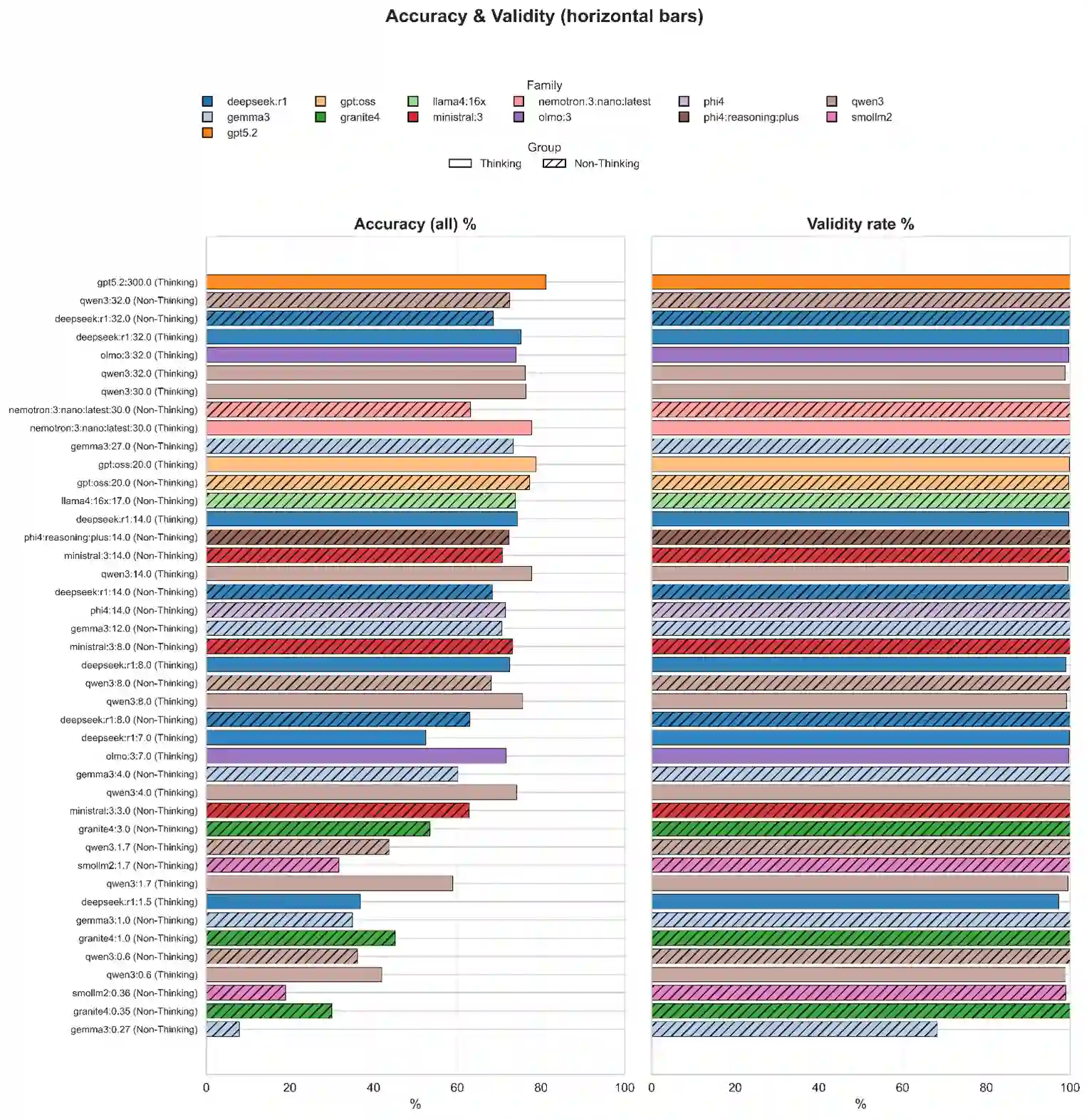
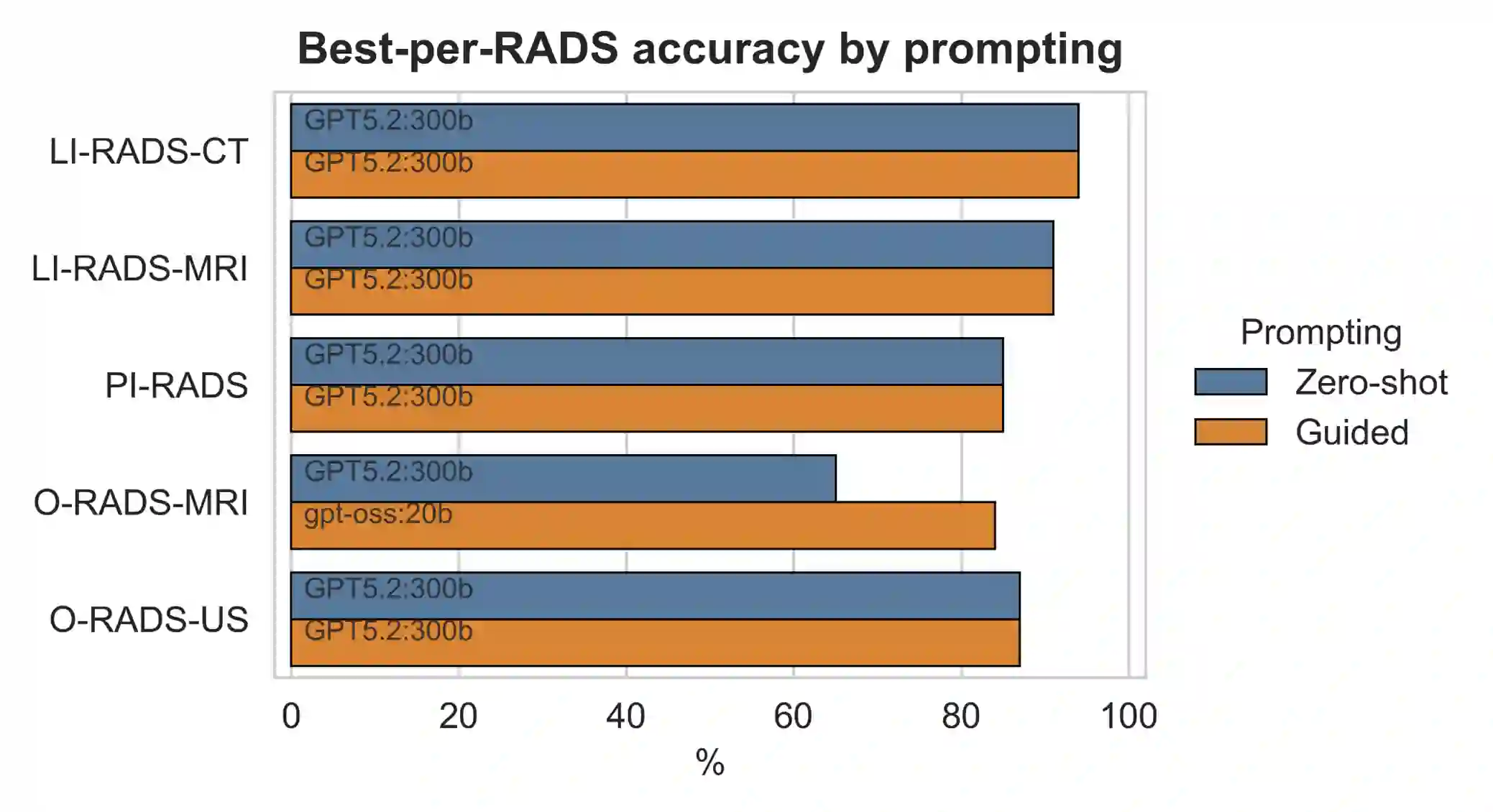
Background: Reporting and Data Systems (RADS) standardize radiology risk communication but automated RADS assignment from narrative reports is challenging because of guideline complexity, output-format constraints, and limited benchmarking across RADS frameworks and model sizes. Purpose: To create RXL-RADSet, a radiologist-verified synthetic multi-RADS benchmark, and compare validity and accuracy of open-weight small language models (SLMs) with a proprietary model for RADS assignment. Materials and Methods: RXL-RADSet contains 1,600 synthetic radiology reports across 10 RADS (BI-RADS, CAD-RADS, GB-RADS, LI-RADS, Lung-RADS, NI-RADS, O-RADS, PI-RADS, TI-RADS, VI-RADS) and multiple modalities. Reports were generated by LLMs using scenario plans and simulated radiologist styles and underwent two-stage radiologist verification. We evaluated 41 quantized SLMs (12 families, 0.135-32B parameters) and GPT-5.2 under a fixed guided prompt. Primary endpoints were validity and accuracy; a secondary analysis compared guided versus zero-shot prompting. Results: Under guided prompting GPT-5.2 achieved 99.8% validity and 81.1% accuracy (1,600 predictions). Pooled SLMs (65,600 predictions) achieved 96.8% validity and 61.1% accuracy; top SLMs in the 20-32B range reached ~99% validity and mid-to-high 70% accuracy. Performance scaled with model size (inflection between <1B and >=10B) and declined with RADS complexity primarily due to classification difficulty rather than invalid outputs. Guided prompting improved validity (99.2% vs 96.7%) and accuracy (78.5% vs 69.6%) compared with zero-shot. Conclusion: RXL-RADSet provides a radiologist-verified multi-RADS benchmark; large SLMs (20-32B) can approach proprietary-model performance under guided prompting, but gaps remain for higher-complexity schemes.
翻译:背景:报告与数据系统(RADS)标准化了放射学风险沟通,但由于指南复杂性、输出格式限制以及跨RADS框架和模型规模的基准测试有限,从叙事报告自动分配RADS具有挑战性。目的:创建放射科医师验证的合成多RADS基准数据集RXL-RADSet,并比较开源小语言模型(SLMs)与专有模型在RADS分配任务中的有效性和准确性。材料与方法:RXL-RADSet包含1,600份涵盖10种RADS(BI-RADS、CAD-RADS、GB-RADS、LI-RADS、Lung-RADS、NI-RADS、O-RADS、PI-RADS、TI-RADS、VI-RADS)及多种成像模态的合成放射学报告。报告由大语言模型基于场景方案和模拟放射科医师风格生成,并经过两阶段放射科医师验证。我们在固定引导提示下评估了41个量化SLMs(12个系列,0.135-320亿参数)和GPT-5.2。主要终点为有效性和准确性;次要分析比较了引导提示与零样本提示的效果。结果:在引导提示下,GPT-5.2达到99.8%的有效性和81.1%的准确性(1,600次预测)。SLMs总体(65,600次预测)达到96.8%的有效性和61.1%的准确性;表现最佳的20-320亿参数SLMs达到约99%的有效性和70%中高段的准确性。性能随模型规模扩大而提升(拐点出现在<10亿与≥100亿参数之间),并随RADS复杂性增加而下降,主要归因于分类难度而非无效输出。与零样本提示相比,引导提示显著提升了有效性(99.2% vs 96.7%)和准确性(78.5% vs 69.6%)。结论:RXL-RADSet提供了放射科医师验证的多RADS基准数据集;在引导提示下,大型SLMs(20-320亿参数)可接近专有模型性能,但在高复杂性RADS方案中仍存在差距。