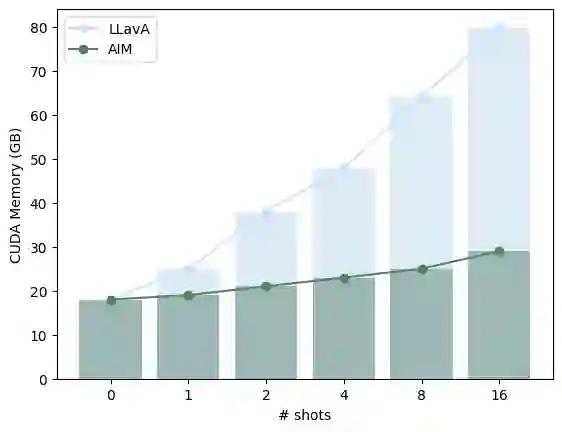
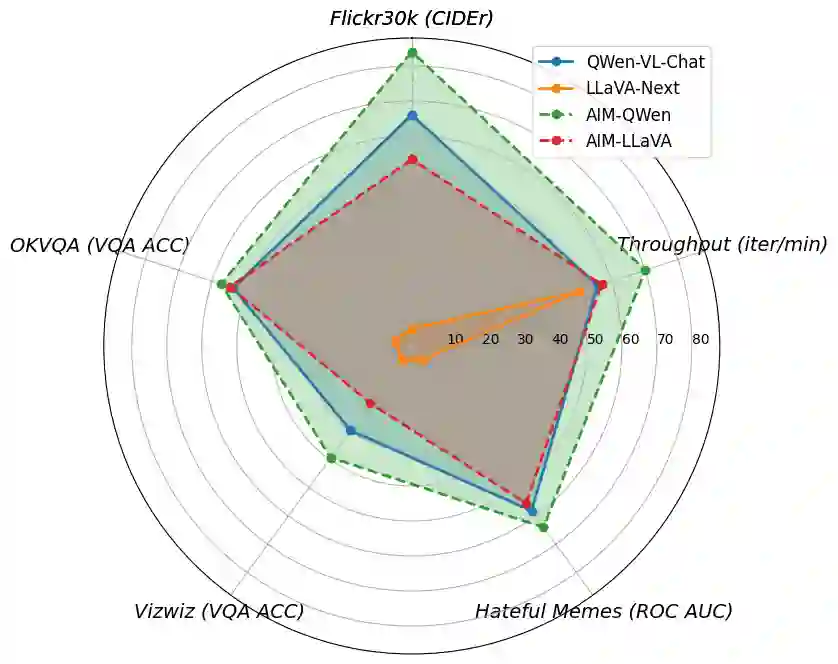
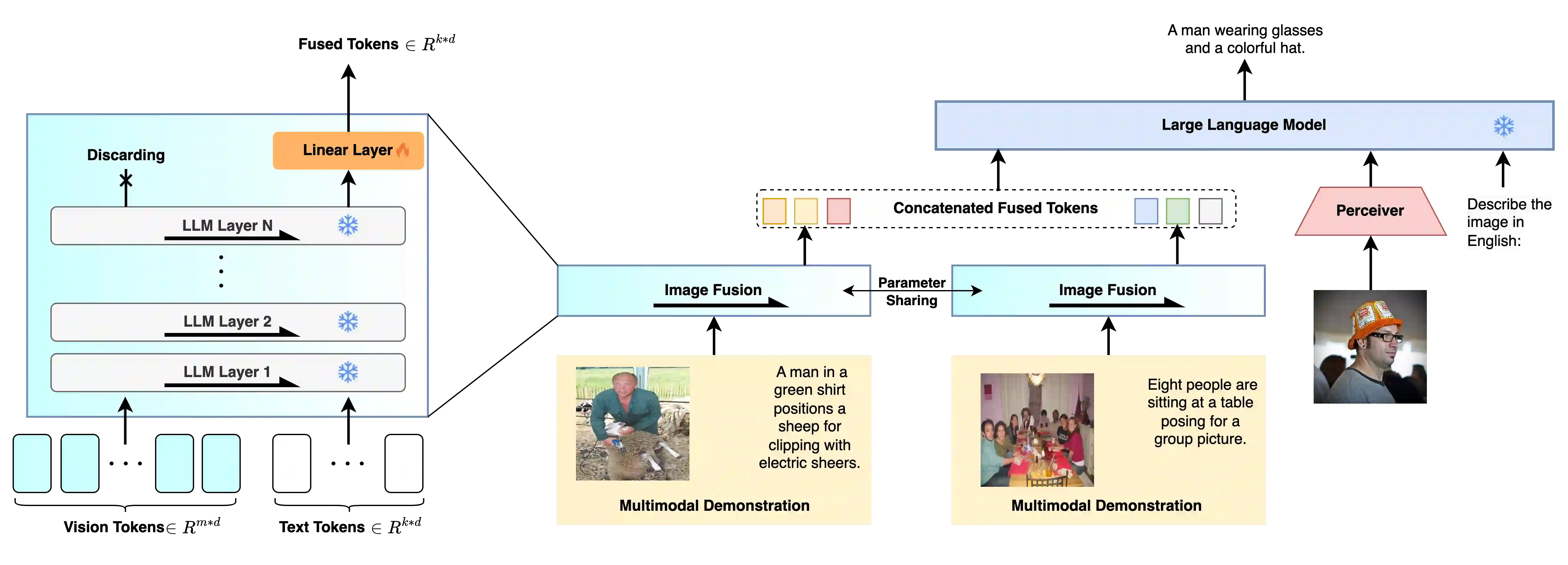
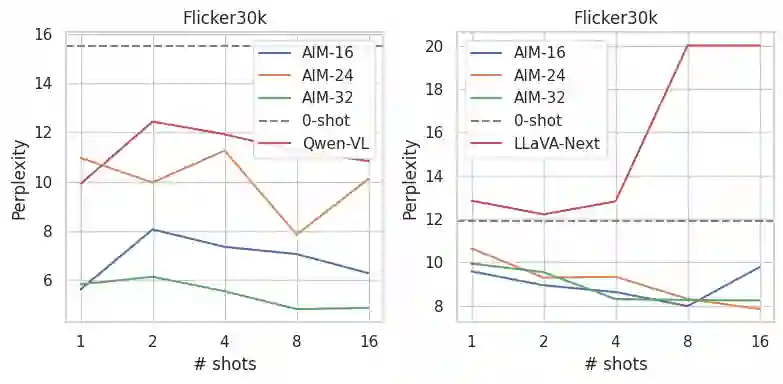
In-context learning (ICL) facilitates Large Language Models (LLMs) exhibiting emergent ability on downstream tasks without updating billions of parameters. However, in the area of multi-modal Large Language Models (MLLMs), two problems hinder the application of multi-modal ICL: (1) Most primary MLLMs are only trained on single-image datasets, making them unable to read multi-modal demonstrations. (2) With the demonstrations increasing, thousands of visual tokens highly challenge hardware and degrade ICL performance. During preliminary explorations, we discovered that the inner LLM tends to focus more on the linguistic modality within multi-modal demonstrations to generate responses. Therefore, we propose a general and light-weighted framework \textbf{AIM} to tackle the mentioned problems through \textbf{A}ggregating \textbf{I}mage information of \textbf{M}ultimodal demonstrations to the dense latent space of the corresponding linguistic part. Specifically, AIM first uses the frozen backbone MLLM to read each image-text demonstration and extracts the vector representations on top of the text. These vectors naturally fuse the information of the image-text pair, and AIM transforms them into fused virtual tokens acceptable for the inner LLM via a trainable projection layer. Ultimately, these fused tokens function as variants of multi-modal demonstrations, fed into the MLLM to direct its response to the current query as usual. Because these fused tokens stem from the textual component of the image-text pair, a multi-modal demonstration is nearly reduced to a pure textual demonstration, thus seamlessly applying to any MLLMs. With its de facto MLLM frozen, AIM is parameter-efficient and we train it on public multi-modal web corpora which have nothing to do with downstream test tasks.
翻译:上下文学习(ICL)使大语言模型(LLM)能够在无需更新数十亿参数的情况下,在下游任务中展现出涌现能力。然而,在多模态大语言模型(MLLM)领域,两个问题阻碍了多模态ICL的应用:(1)大多数主流MLLM仅在单图像数据集上训练,导致其无法理解多模态示例;(2)随着示例数量增加,数千个视觉标记对硬件构成极大挑战并降低ICL性能。在初步探索中,我们发现内部LLM倾向于更多地关注多模态示例中的语言模态以生成响应。为此,我们提出一个通用轻量级框架**AIM**,通过将多模态示例的**图**像信息**聚**合到对应语言部分的稠密潜空间来解决上述问题。具体而言,AIM首先使用冻结的骨干MLLM读取每个图文示例,并在文本顶部提取向量表示。这些向量自然地融合了图文对的信息,AIM通过可训练的投影层将其转换为内部LLM可接受的融合虚拟标记。最终,这些融合标记作为多模态示例的变体,像常规操作一样输入MLLM以引导其对当前查询的响应。由于这些融合标记源自图文对的文本部分,多模态示例几乎被简化为纯文本示例,从而可无缝应用于任意MLLM。通过保持实际MLLM冻结,AIM具有参数高效性,并在与下游测试任务无关的公开多模态网络语料库上进行训练。