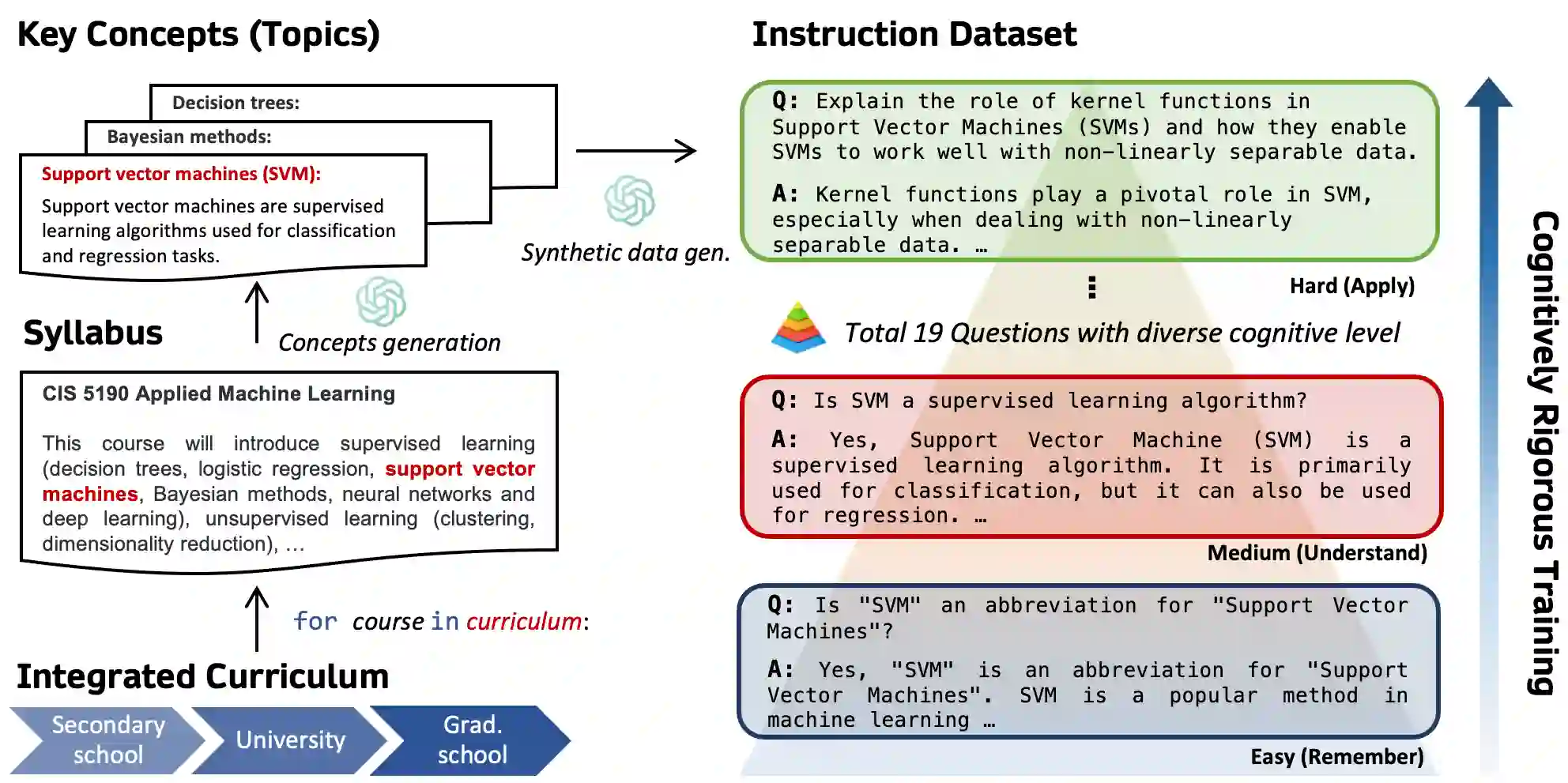
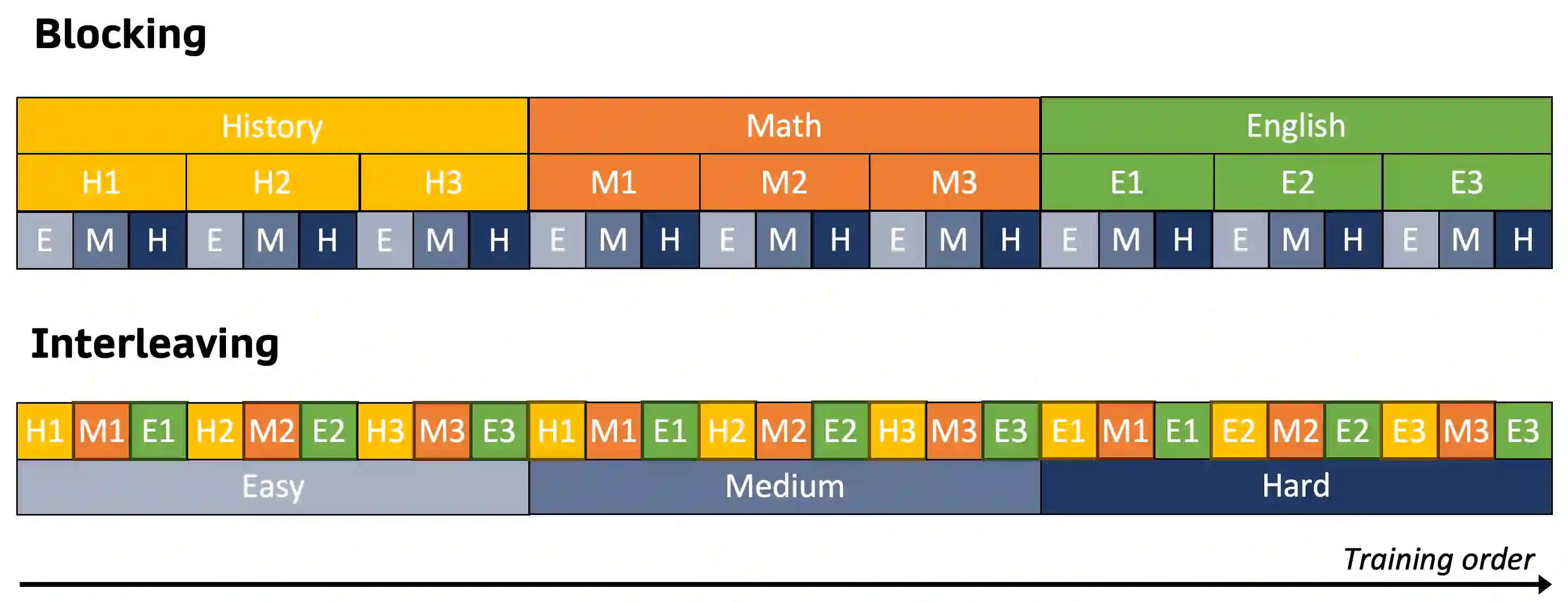
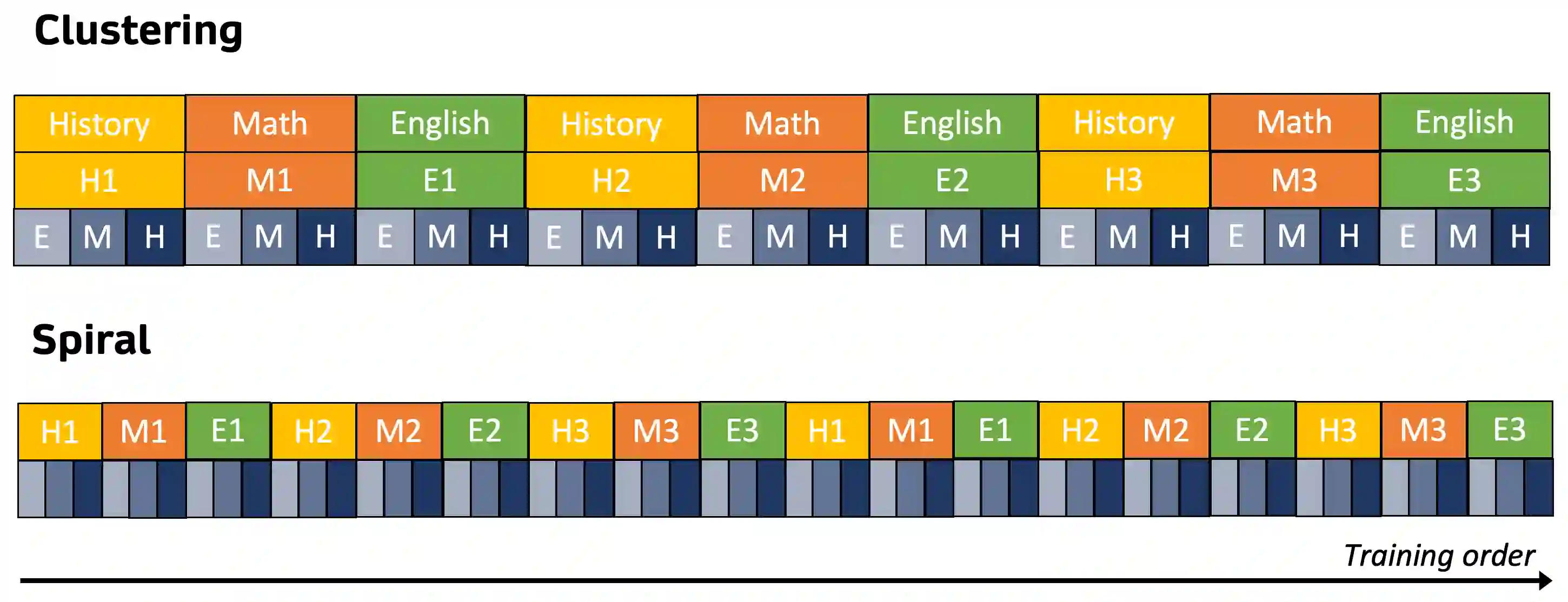
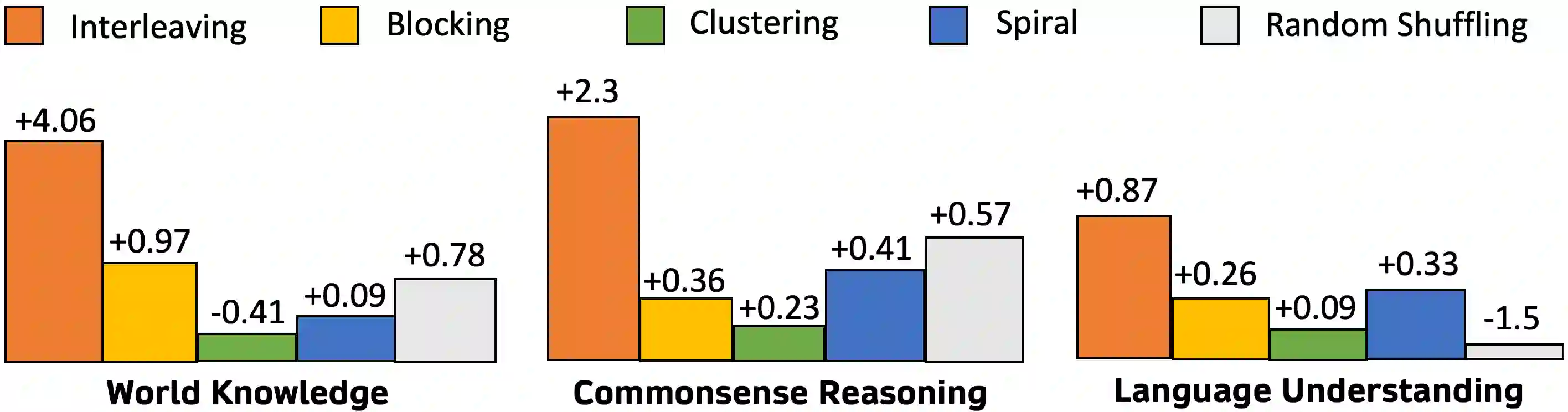
In building instruction-tuned large language models (LLMs), the importance of a deep understanding of human knowledge can be often overlooked by the importance of instruction diversification. This research proposes a novel approach to instruction tuning by integrating a structured cognitive learning methodology that takes inspiration from the systematic progression and cognitively stimulating nature of human education through two key steps. First, our synthetic instruction data generation pipeline, designed with some references to human educational frameworks, is enriched with meta-data detailing topics and cognitive rigor for each instruction. Specifically, our generation framework is infused with questions of varying levels of rigorousness, inspired by Bloom's Taxonomy, a classic educational model for structured curriculum learning. Second, during instruction tuning, we curate instructions such that questions are presented in an increasingly complex manner utilizing the information on question complexity and cognitive rigorousness produced by our data generation pipeline. Our human-inspired curriculum learning yields significant performance enhancements compared to uniform sampling or round-robin, improving MMLU by 3.06 on LLaMA 2. We conduct extensive experiments and find that the benefits of our approach are consistently observed in eight other benchmarks. We hope that our work will shed light on the post-training learning process of LLMs and its similarity with their human counterpart.
翻译:在构建指令微调的大型语言模型(LLM)时,对人类知识深层理解的重要性常被指令多样化的重要性所掩盖。本研究提出一种新颖的指令微调方法,通过整合结构化认知学习策略,借鉴人类教育中系统递进性与认知启发性特征,分两个关键步骤实现突破。首先,我们构建的合成指令数据生成管线参考人类教育框架,为每条指令补充了描述主题与认知深度的元数据。具体而言,该生成框架植入了基于布鲁姆分类学(Bloom's Taxonomy)——这一经典课程结构学习模型——不同认知层级的问题。其次,在指令微调阶段,我们利用数据生成管线输出的问题复杂度与认知深度信息,按递进难度组织问题呈现顺序。这种受人类启发的课程学习相比均匀采样或轮询策略带来显著性能提升,使LLaMA 2的MMLU得分提高3.06。我们开展大量实验发现,该方法的优势在另外八个基准测试中持续显现。希望本研究能揭示LLM后训练学习过程与人类学习过程的相似性。