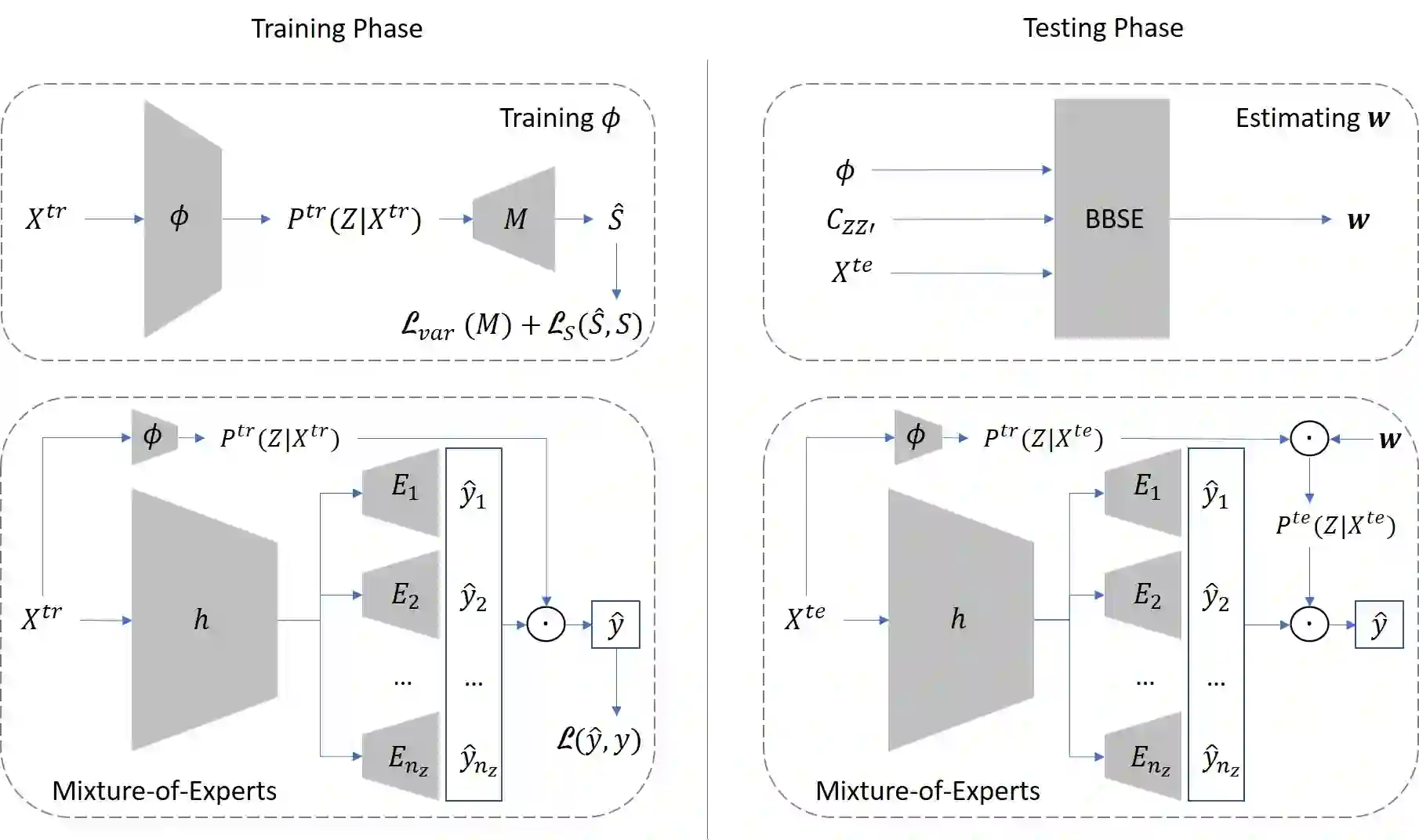
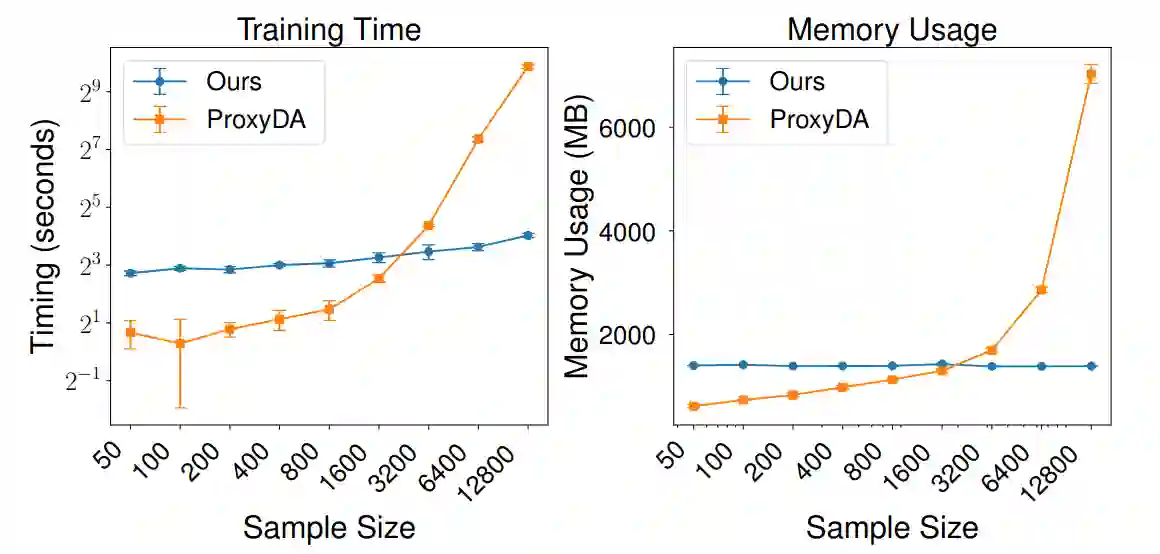
We consider the task of out-of-distribution (OOD) generalization, where the distribution shift is due to an unobserved confounder ($Z$) affecting both the covariates ($X$) and the labels ($Y$). In this setting, traditional assumptions of covariate and label shift are unsuitable due to the confounding, which introduces heterogeneity in the predictor, i.e., $\hat{Y} = f_Z(X)$. OOD generalization differs from traditional domain adaptation by not assuming access to the covariate distribution ($X^\text{te}$) of the test samples during training. These conditions create a challenging scenario for OOD robustness: (a) $Z^\text{tr}$ is an unobserved confounder during training, (b) $P^\text{te}{Z} \neq P^\text{tr}{Z}$, (c) $X^\text{te}$ is unavailable during training, and (d) the posterior predictive distribution depends on $P^\text{te}(Z)$, i.e., $\hat{Y} = E_{P^\text{te}(Z)}[f_Z(X)]$. In general, accurate predictions are unattainable in this scenario, and existing literature has proposed complex predictors based on identifiability assumptions that require multiple additional variables. Our work investigates a set of identifiability assumptions that tremendously simplify the predictor, whose resulting elegant simplicity outperforms existing approaches.
翻译:我们考虑分布外(OOD)泛化任务,其中分布偏移是由一个同时影响协变量($X$)和标签($Y$)的未观测混杂因子($Z$)所导致。在此设定下,由于混杂效应引入了预测器的异质性(即 $\hat{Y} = f_Z(X)$),传统的协变量偏移和标签偏移假设均不适用。OOD泛化与传统域适应的区别在于:训练期间不假设能够获取测试样本的协变量分布($X^\text{te}$)。这些条件为OOD鲁棒性构成了一个具有挑战性的场景:(a)$Z^\text{tr}$ 是训练期间未观测的混杂因子;(b)$P^\text{te}{Z} \neq P^\text{tr}{Z}$;(c)$X^\text{te}$ 在训练期间不可用;(d)后验预测分布依赖于 $P^\text{te}(Z)$,即 $\hat{Y} = E_{P^\text{te}(Z)}[f_Z(X)]$。一般而言,在此场景下无法获得精确预测,现有文献基于可识别性假设提出了需要多个额外变量的复杂预测器。本研究探究了一组可显著简化预测器的可识别性假设,其最终呈现的优雅简洁性超越了现有方法。