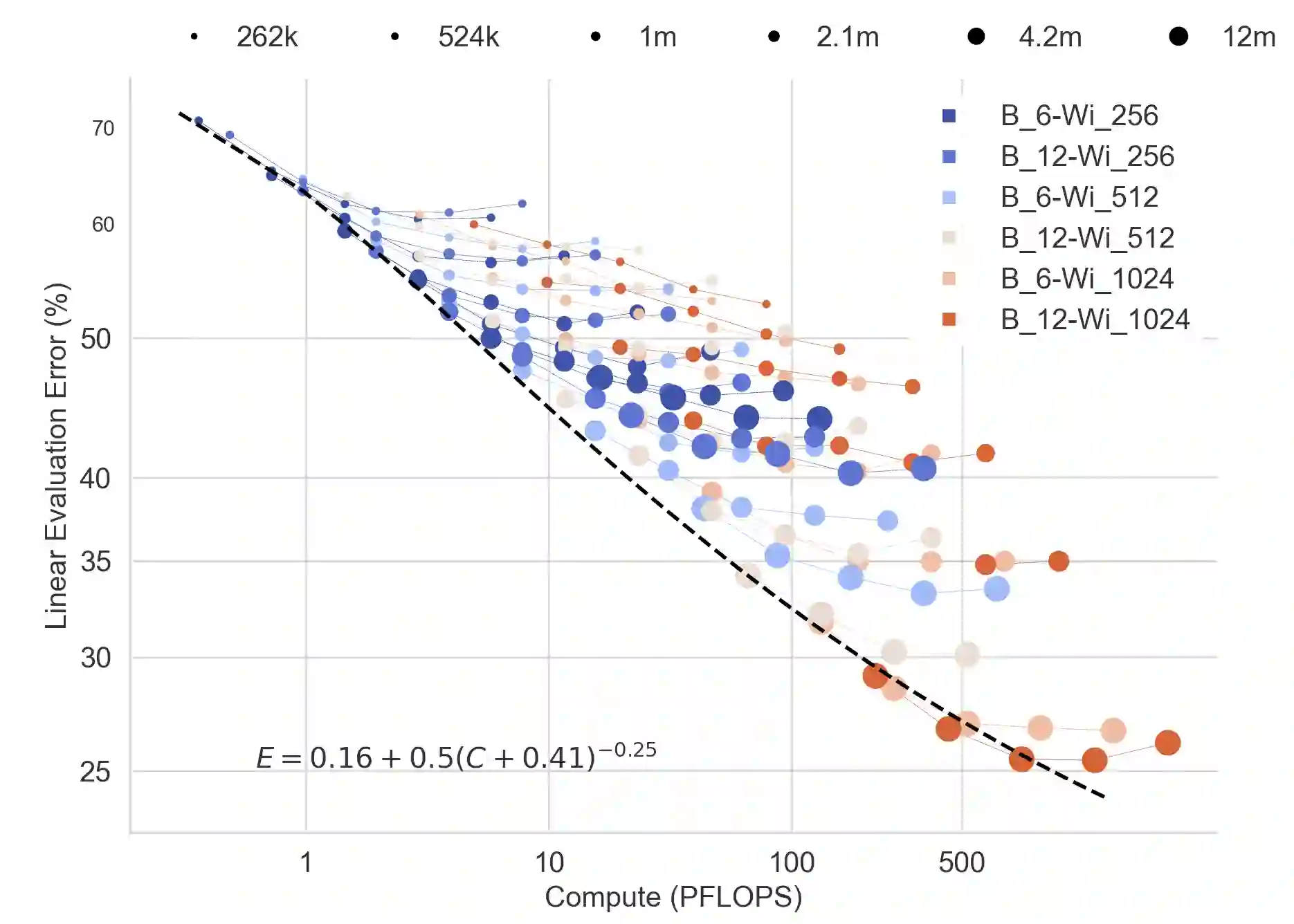
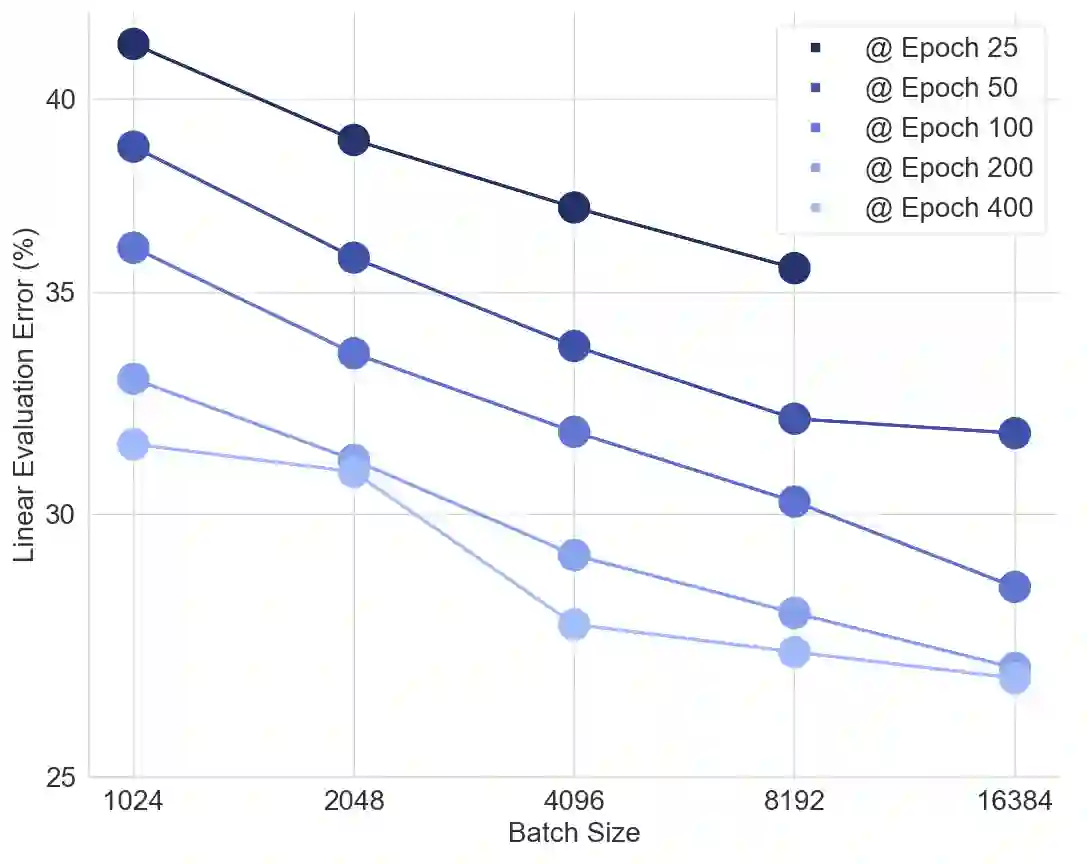
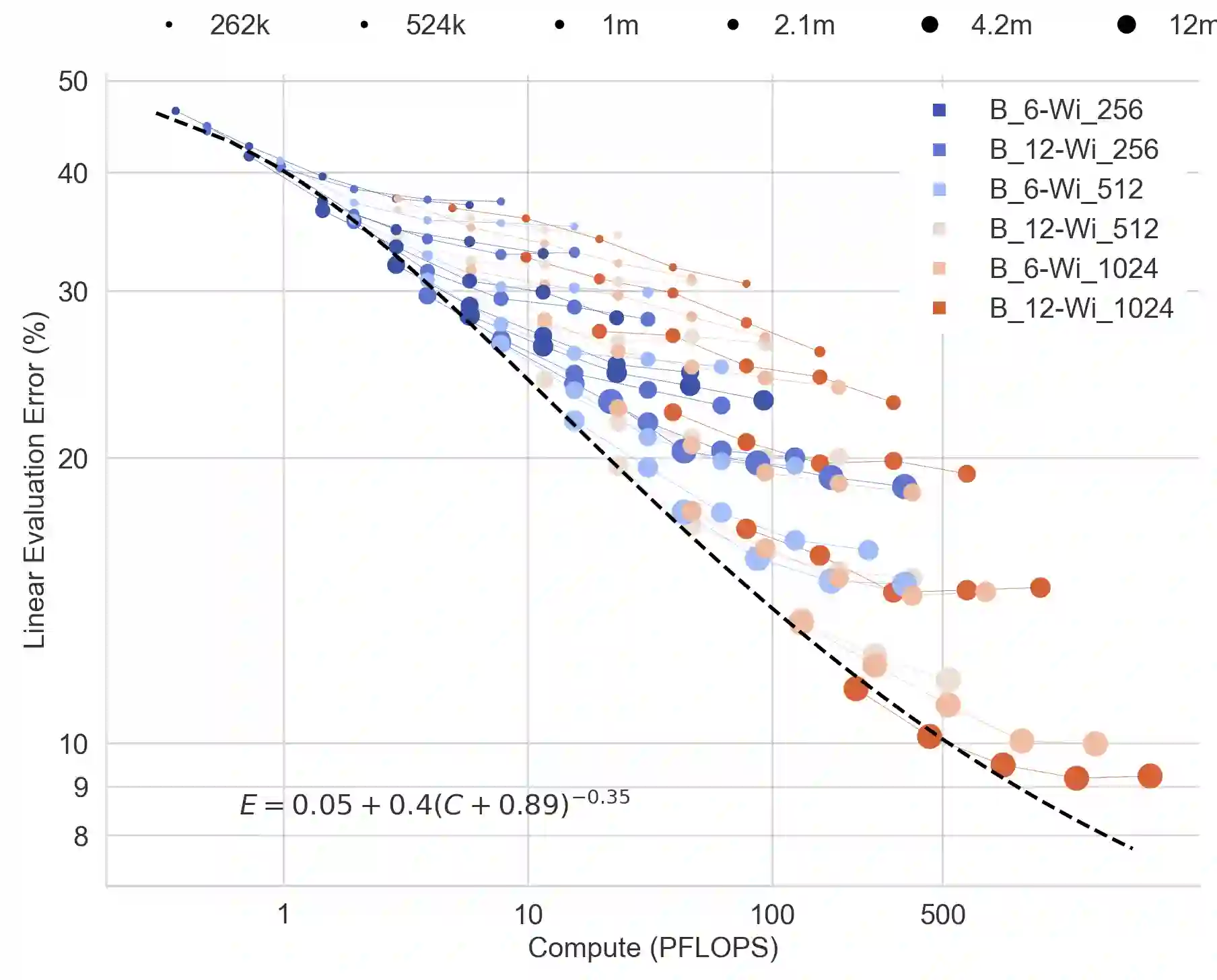
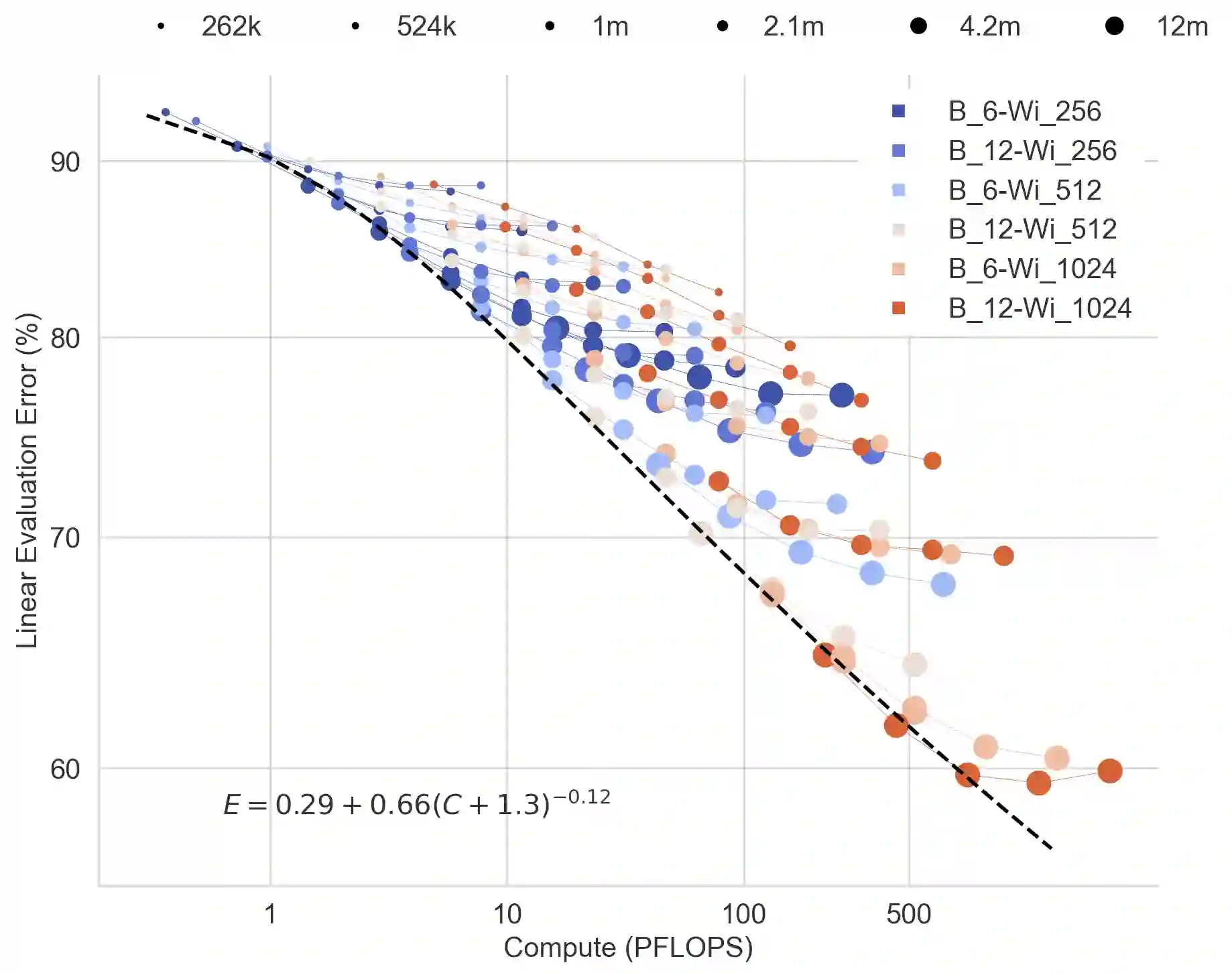
In this work we revisit the most fundamental building block in deep learning, the multi-layer perceptron (MLP), and study the limits of its performance on vision tasks. Empirical insights into MLPs are important for multiple reasons. (1) Given the recent narrative "less inductive bias is better", popularized due to transformers eclipsing convolutional models, it is natural to explore the limits of this hypothesis. To that end, MLPs offer an ideal test bed, as they lack any vision-specific inductive bias. (2) MLPs have almost exclusively been the main protagonist in the deep learning theory literature due to their mathematical simplicity, serving as a proxy to explain empirical phenomena observed for more complex architectures. Surprisingly, experimental datapoints for MLPs are very difficult to find in the literature, especially when coupled with large pre-training protocols. This discrepancy between practice and theory is worrying: Do MLPs reflect the empirical advances exhibited by practical models? Or do theorists need to rethink the role of MLPs as a proxy? We provide insights into both these aspects. We show that the performance of MLPs drastically improves with scale (95% on CIFAR10, 82% on CIFAR100, 58% on ImageNet ReaL), highlighting that lack of inductive bias can indeed be compensated. We observe that MLPs mimic the behaviour of their modern counterparts faithfully, with some components in the learning setting however exhibiting stronger or unexpected behaviours. Due to their inherent computational efficiency, large pre-training experiments become more accessible for academic researchers. All of our experiments were run on a single GPU.
翻译:本文重新审视了深度学习中最基础的构建模块——多层感知机(MLP),并研究了其在视觉任务中的性能极限。对于MLP的实证洞察具有重要意义,原因如下:(1)鉴于近期因Transformer超越卷积模型而流行的“更少归纳偏置更优”的观点,探索这一假设的极限显得尤为必要。MLP因其缺乏任何视觉特定归纳偏置,成为理想的研究对象。(2)MLP几乎一直是深度学习理论文献中的核心研究对象,其数学简洁性使其成为解释更复杂架构所表现出的实证现象的替代模型。然而,令人惊讶的是,文献中关于MLP的实验数据极为稀缺,尤其当涉及大规模预训练方案时。这种实践与理论之间的脱节令人担忧:MLP是否能反映实际模型所展现的实证进展?抑或理论家们需要重新思考MLP作为替代模型的作用?我们针对这两方面提供了见解。研究表明,MLP的性能随规模扩展显著提升(在CIFAR10、CIFAR100和ImageNet ReaL上分别达到95%、82%和58%),这凸显了归纳偏置的缺乏确实可通过规模补偿。我们观察到MLP忠实地模仿了其现代对应物的行为,但在学习设置的某些组件中表现出更强或意料之外的模式。鉴于其固有的计算效率,大型预训练实验对学术研究者而言更具可行性。我们所有的实验均在单张GPU上完成。