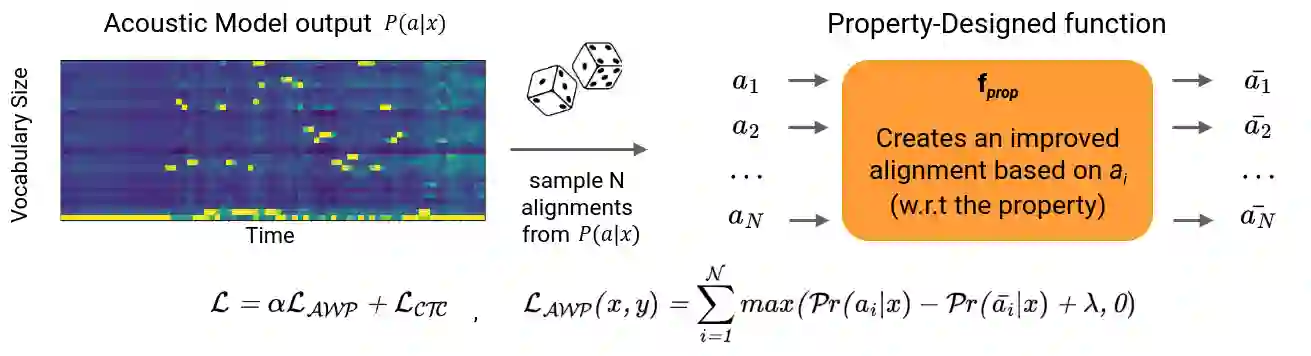
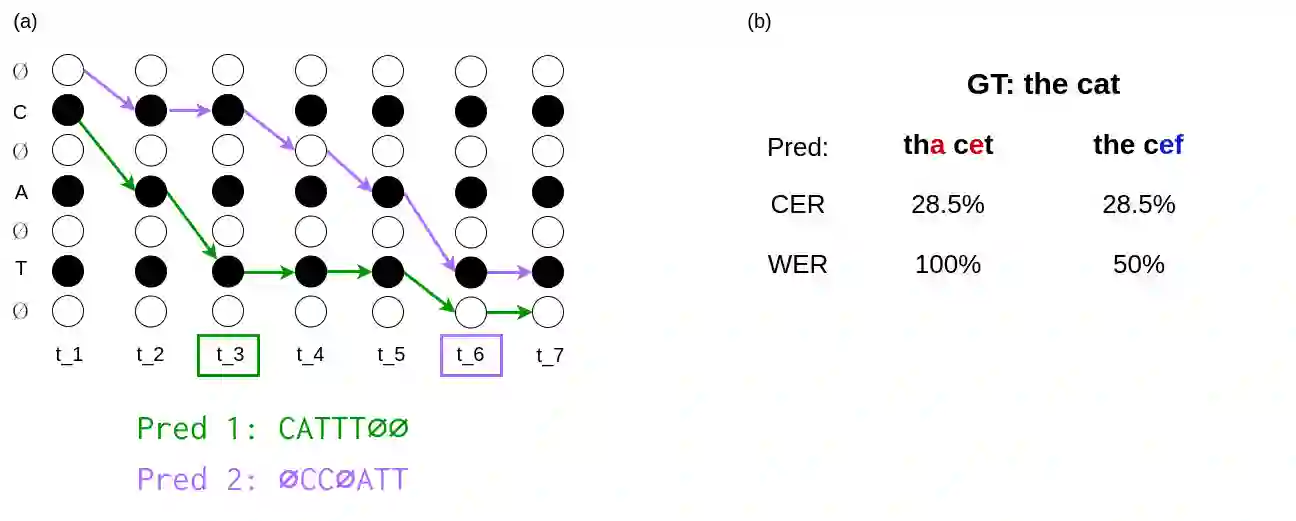
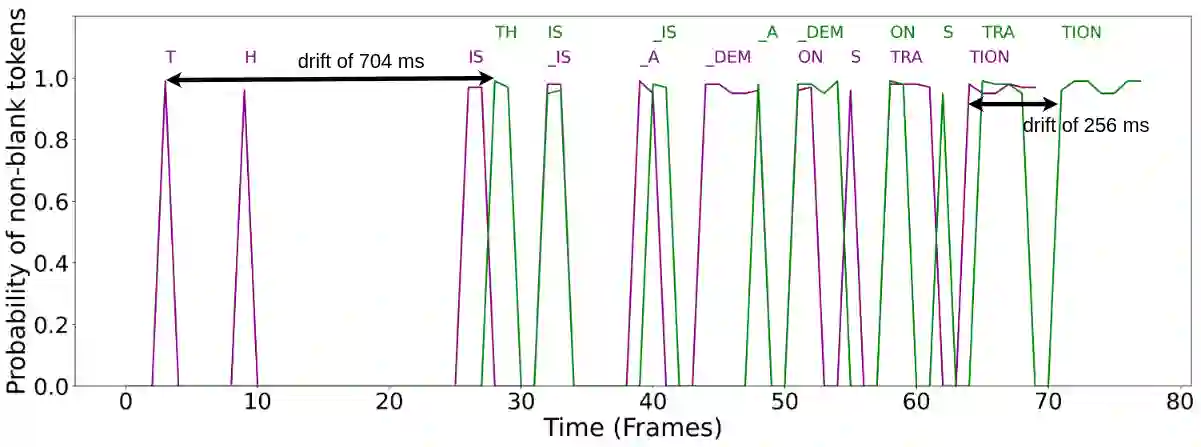
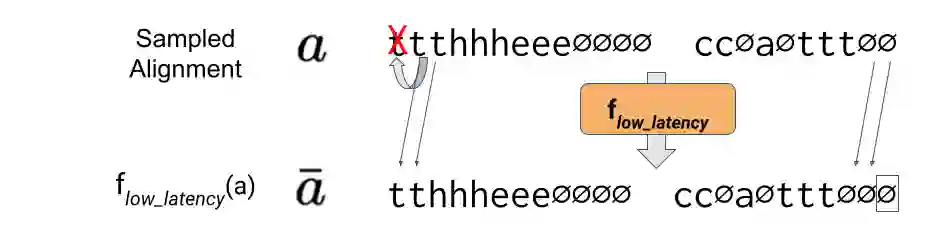
Connectionist Temporal Classification (CTC) is a widely used criterion for training supervised sequence-to-sequence (seq2seq) models. It enables learning the relations between input and output sequences, termed alignments, by marginalizing over perfect alignments (that yield the ground truth), at the expense of imperfect alignments. This binary differentiation of perfect and imperfect alignments falls short of capturing other essential alignment properties that hold significance in other real-world applications. Here we propose $\textit{Align With Purpose}$, a $\textbf{general Plug-and-Play framework}$ for enhancing a desired property in models trained with the CTC criterion. We do that by complementing the CTC with an additional loss term that prioritizes alignments according to a desired property. Our method does not require any intervention in the CTC loss function, enables easy optimization of a variety of properties, and allows differentiation between both perfect and imperfect alignments. We apply our framework in the domain of Automatic Speech Recognition (ASR) and show its generality in terms of property selection, architectural choice, and scale of training dataset (up to 280,000 hours). To demonstrate the effectiveness of our framework, we apply it to two unrelated properties: emission time and word error rate (WER). For the former, we report an improvement of up to 570ms in latency optimization with a minor reduction in WER, and for the latter, we report a relative improvement of 4.5% WER over the baseline models. To the best of our knowledge, these applications have never been demonstrated to work on a scale of data as large as ours. Notably, our method can be implemented using only a few lines of code, and can be extended to other alignment-free loss functions and to domains other than ASR.
翻译:连接主义时序分类(CTC)是训练监督序列到序列(seq2seq)模型时广泛使用的准则。它通过边缘化完美对齐(产生真实标签的对齐)而牺牲不完美对齐,从而学习输入与输出序列之间的关系(即对齐)。这种完美与不完美对齐的二元区分,未能捕捉到在其他实际应用中具有重要意义的其他关键对齐属性。本文提出**<i>对准目标</i>**,这是一个**通用即插即用框架**,用于增强基于CTC准则训练的模型中的期望属性。我们通过为CTC补充一个额外的损失项来实现,该损失项根据期望属性优先选择对齐。我们的方法无需对CTC损失函数进行任何干预,能够轻松优化多种属性,并允许区分完美和不完美对齐。我们将该框架应用于自动语音识别(ASR)领域,展示了其在属性选择、架构选择及训练数据集规模(高达280,000小时)方面的通用性。为验证框架有效性,我们将其应用于两个不相关的属性:发射时间和词错误率(WER)。对于前者,我们报告了在WER轻微下降的情况下,延迟优化最高提升570毫秒;对于后者,我们报告了相较于基线模型WER相对改善4.5%。据我们所知,这些应用此前从未在如此大规模数据上得到验证。值得注意的是,我们的方法仅需数行代码即可实现,并可扩展至其他无对齐损失函数及ASR以外的领域。