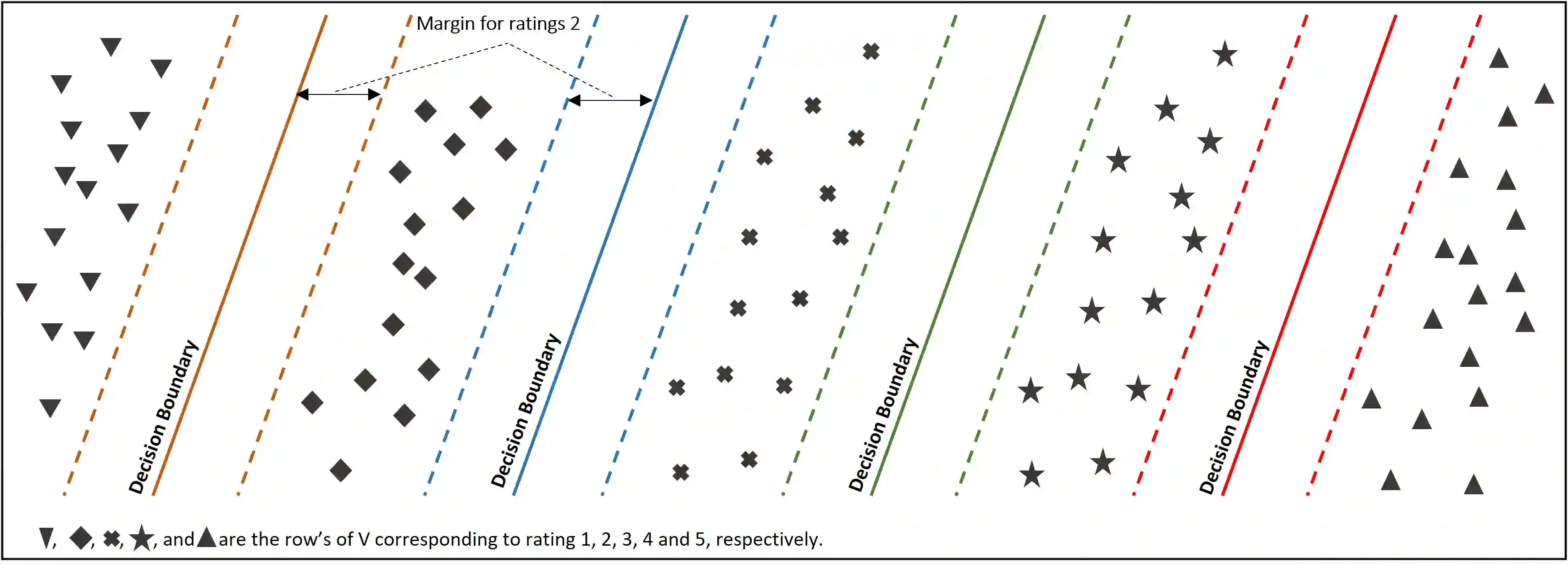
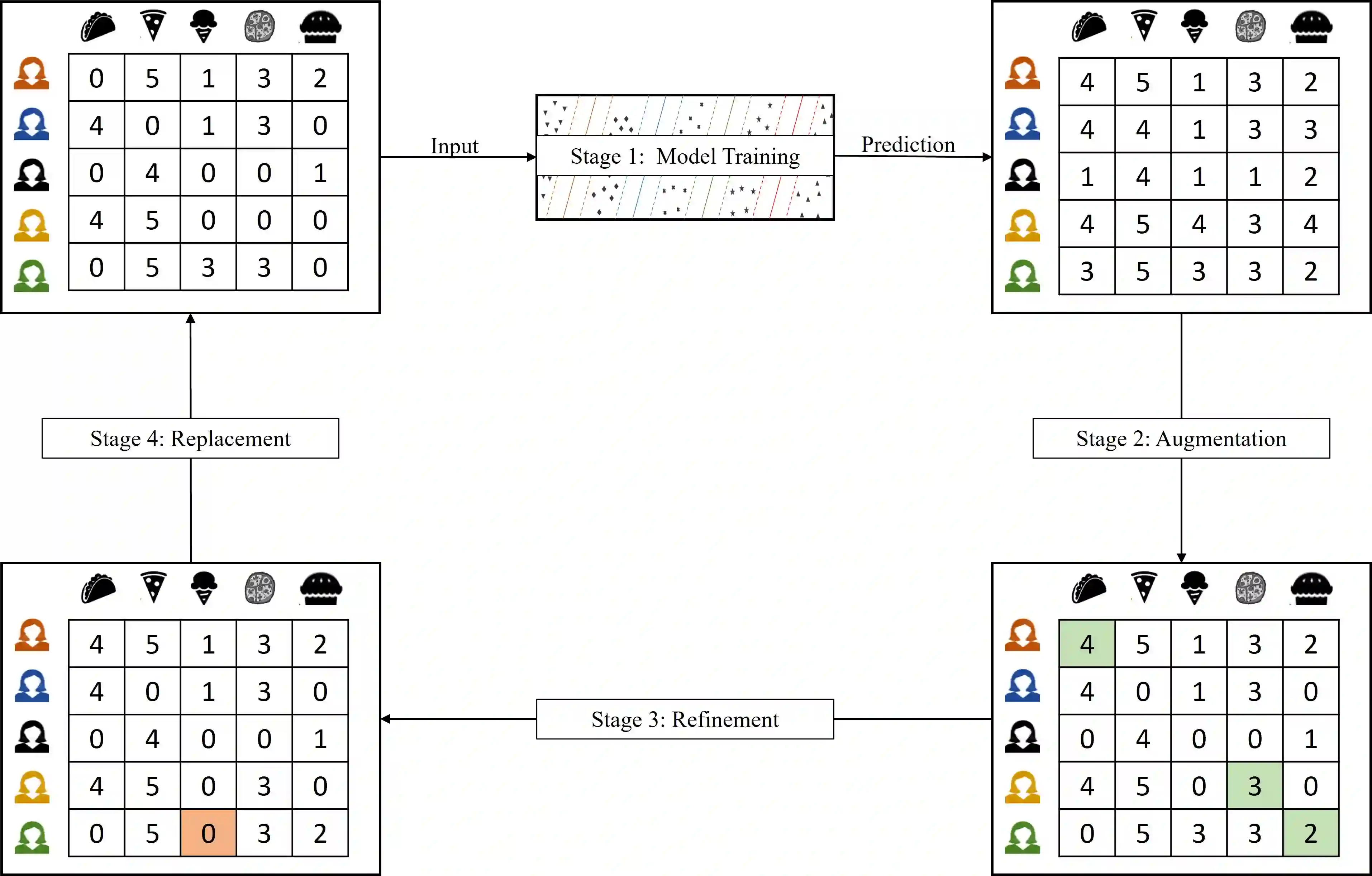
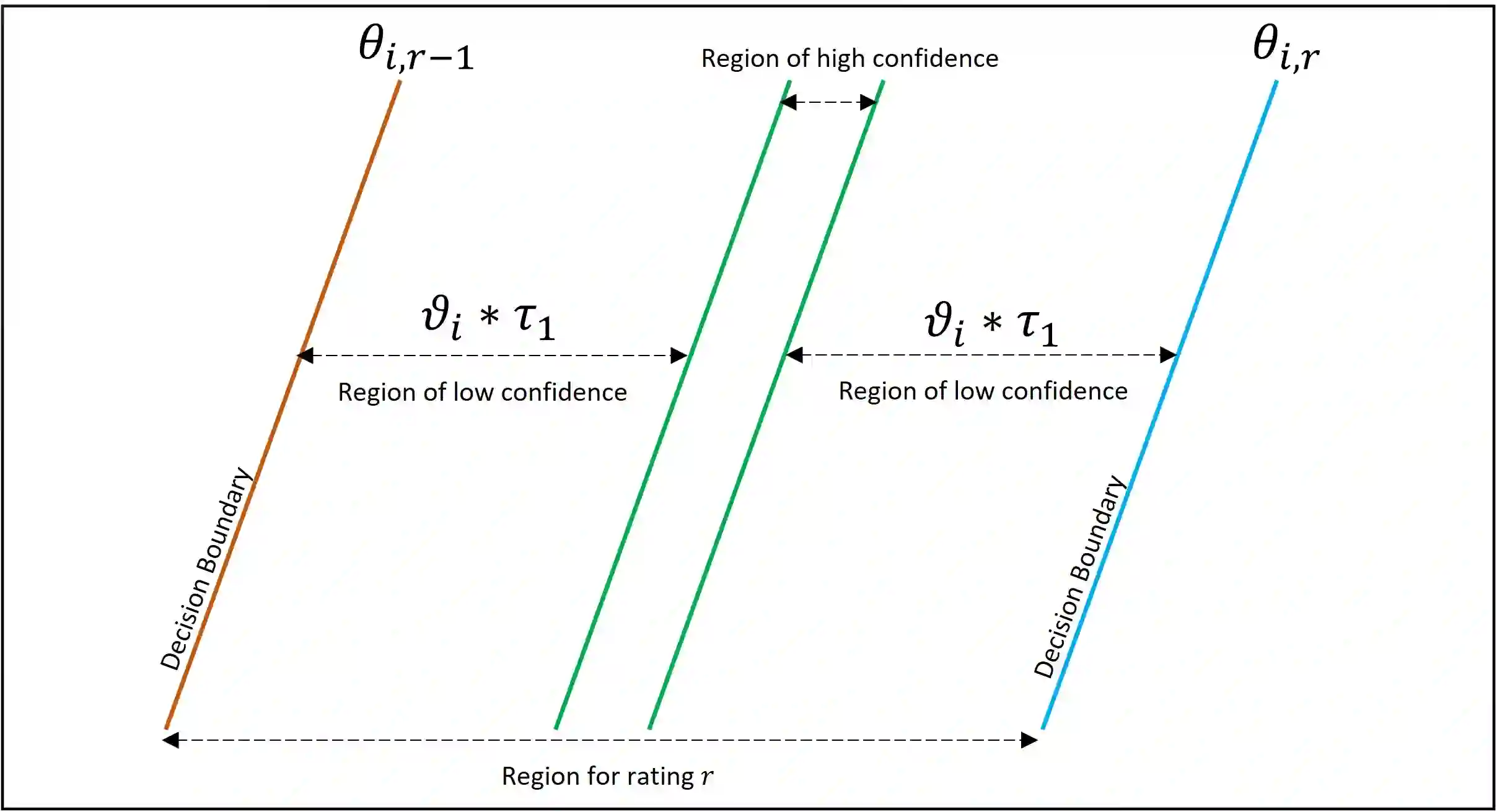
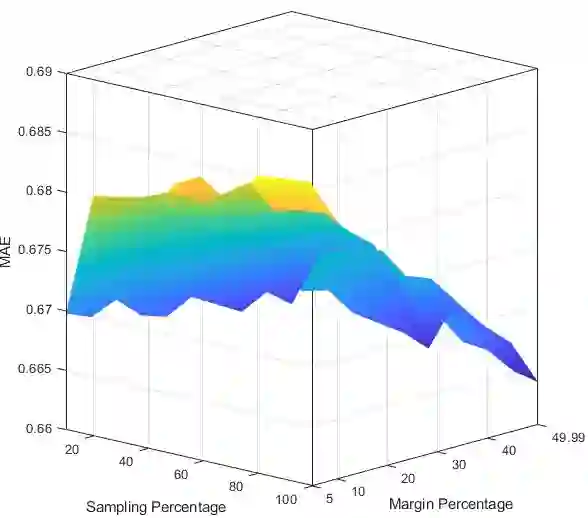
Collaborative filtering (CF) has become a popular method for developing recommender systems (RSs) where ratings of a user for new items are predicted based on her past preferences and available preference information of other users. Despite the popularity of CF-based methods, their performance is often greatly limited by the sparsity of observed entries. In this study, we explore the data augmentation and refinement aspects of Maximum Margin Matrix Factorization (MMMF), a widely accepted CF technique for rating predictions, which has not been investigated before. We exploit the inherent characteristics of CF algorithms to assess the confidence level of individual ratings and propose a semi-supervised approach for rating augmentation based on self-training. We hypothesize that any CF algorithm's predictions with low confidence are due to some deficiency in the training data and hence, the performance of the algorithm can be improved by adopting a systematic data augmentation strategy. We iteratively use some of the ratings predicted with high confidence to augment the training data and remove low-confidence entries through a refinement process. By repeating this process, the system learns to improve prediction accuracy. Our method is experimentally evaluated on several state-of-the-art CF algorithms and leads to informative rating augmentation, improving the performance of the baseline approaches.
翻译:协同过滤(CF)已成为开发推荐系统(RSs)的常用方法,其通过用户的历史偏好及其他用户的可用偏好信息,预测该用户对新项目的评分。尽管基于CF的方法广受欢迎,但其性能往往受到观测条目稀疏性的极大限制。在本研究中,我们探索了最大间隔矩阵分解(MMMF)在评分预测这一广泛接受的CF技术中的数据增强与精炼方面,这是此前尚未被研究过的方向。我们利用CF算法的内在特性来评估单个评分的置信水平,并提出一种基于自训练的半监督评分增强方法。我们假设,任何CF算法低置信度的预测均源于训练数据的某种缺陷,因此,通过采用系统性的数据增强策略可提升算法性能。我们迭代地将部分高置信度预测评分用于增强训练数据,并通过精炼过程移除低置信度条目。通过重复这一过程,系统学会提升预测准确性。我们基于多种最先进的CF算法对所提方法进行了实验评估,结果表明该方法能够实现信息丰富的评分增强,从而提升基线方法的性能。