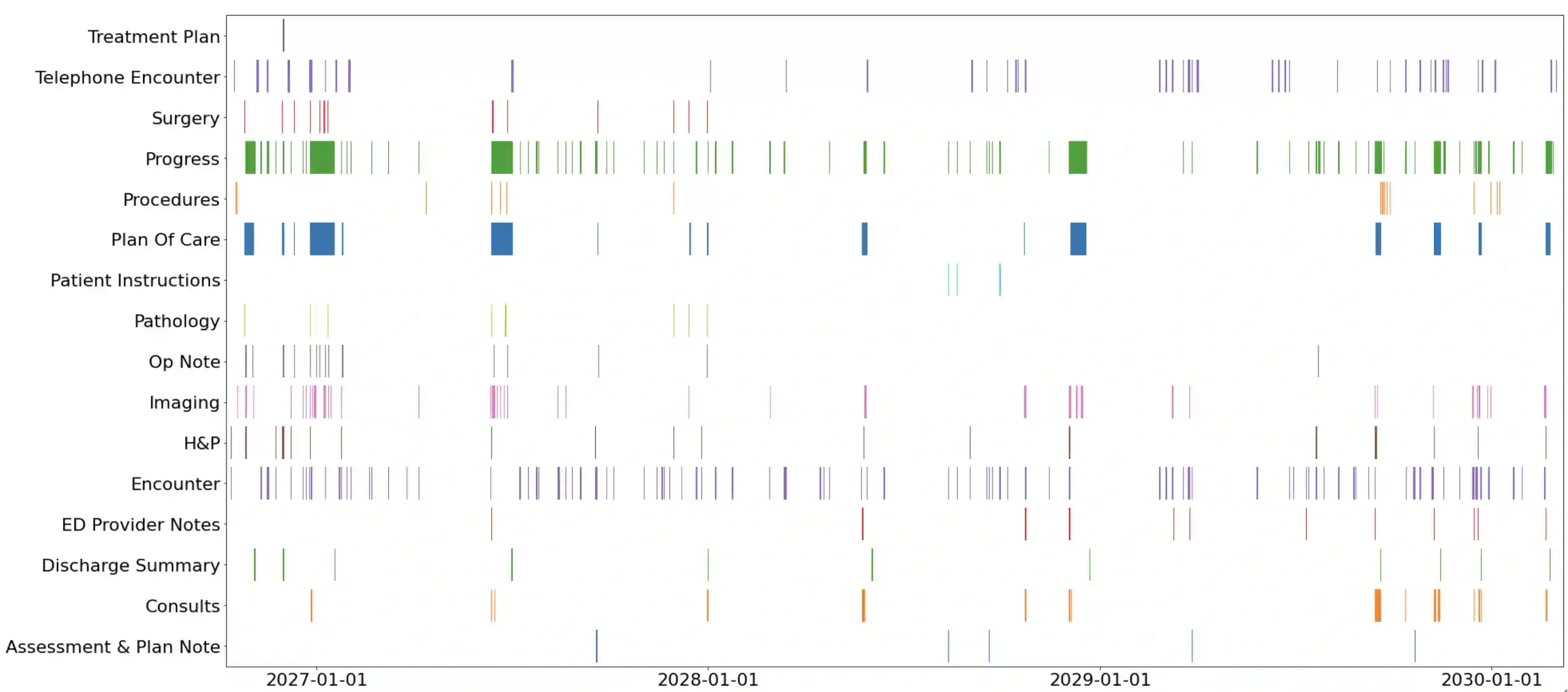
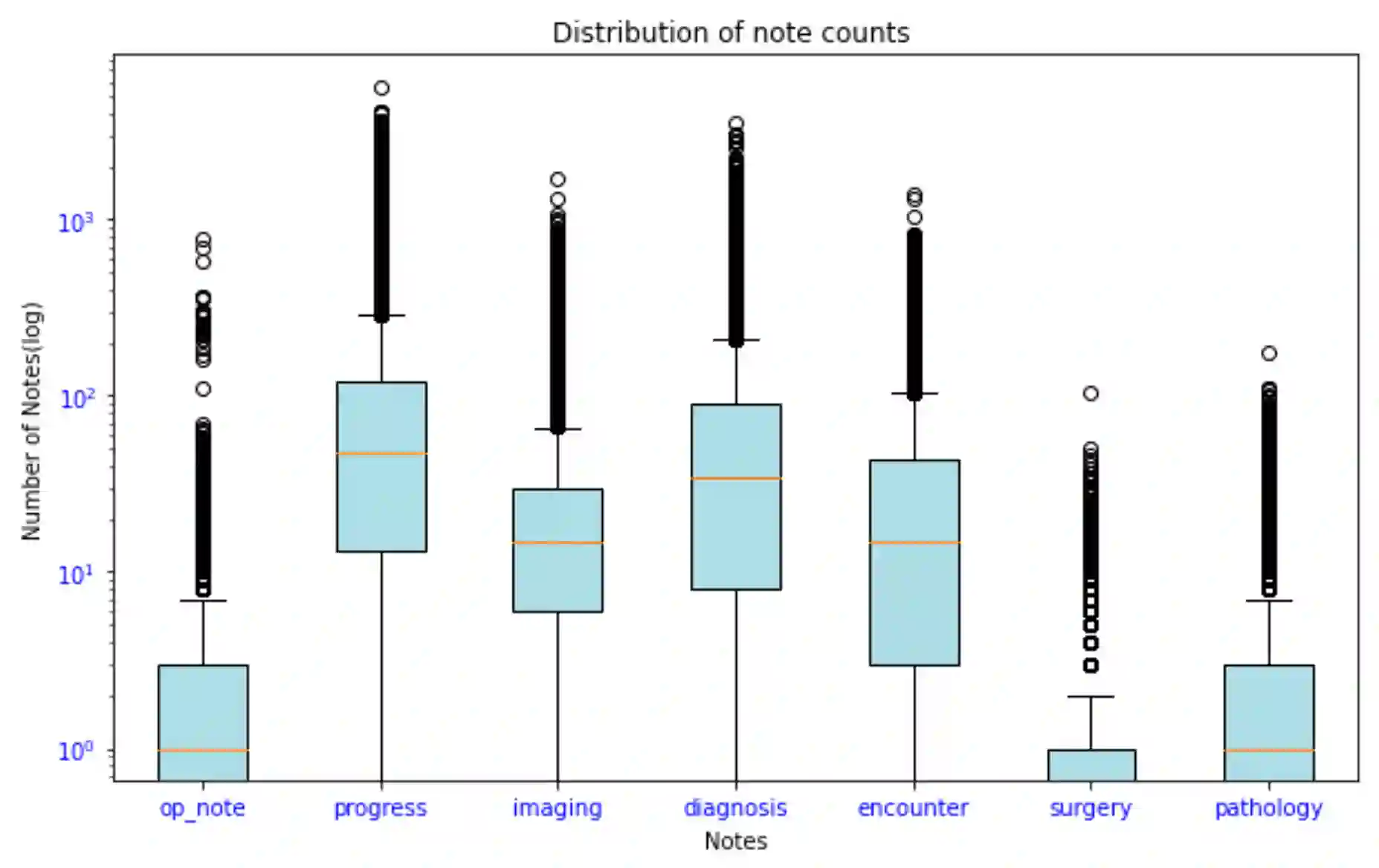
The rapid digitization of real-world data offers an unprecedented opportunity for optimizing healthcare delivery and accelerating biomedical discovery. In practice, however, such data is most abundantly available in unstructured forms, such as clinical notes in electronic medical records (EMRs), and it is generally plagued by confounders. In this paper, we present TRIALSCOPE, a unifying framework for distilling real-world evidence from population-level observational data. TRIALSCOPE leverages biomedical language models to structure clinical text at scale, employs advanced probabilistic modeling for denoising and imputation, and incorporates state-of-the-art causal inference techniques to combat common confounders. Using clinical trial specification as generic representation, TRIALSCOPE provides a turn-key solution to generate and reason with clinical hypotheses using observational data. In extensive experiments and analyses on a large-scale real-world dataset with over one million cancer patients from a large US healthcare network, we show that TRIALSCOPE can produce high-quality structuring of real-world data and generates comparable results to marquee cancer trials. In addition to facilitating in-silicon clinical trial design and optimization, TRIALSCOPE may be used to empower synthetic controls, pragmatic trials, post-market surveillance, as well as support fine-grained patient-like-me reasoning in precision diagnosis and treatment.
翻译:真实世界数据的快速数字化为优化医疗服务和加速生物医学发现提供了前所未有的机遇。然而在实际应用中,此类数据通常以非结构化形式大量存在(如电子病历中的临床笔记),并普遍受到混杂因素的影响。本文提出TRIALSCOPE,一个从群体水平观察性数据中提炼真实世界证据的统一框架。TRIALSCOPE利用生物医学语言模型大规模结构化临床文本,采用先进概率建模进行去噪与数据插补,并整合最先进的因果推断技术以应对常见混杂因素。通过将临床试验规范作为通用表征,TRIALSCOPE提供了一种即用型解决方案,可使用观察性数据生成并推理临床假设。我们在包含来自美国大型医疗网络超百万癌症患者的大规模真实世界数据集上进行了广泛实验与分析,结果表明TRIALSCOPE能对真实世界数据产生高质量的结构化结果,并生成与标志性癌症试验可比的结果。除支持硅基临床试验设计与优化外,TRIALSCOPE还可用于赋能合成对照、实效性试验、上市后监测,以及在精准诊断与治疗中支持细粒度的相似患者推理。