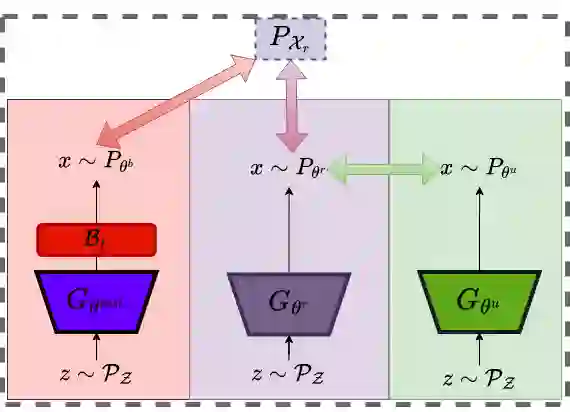
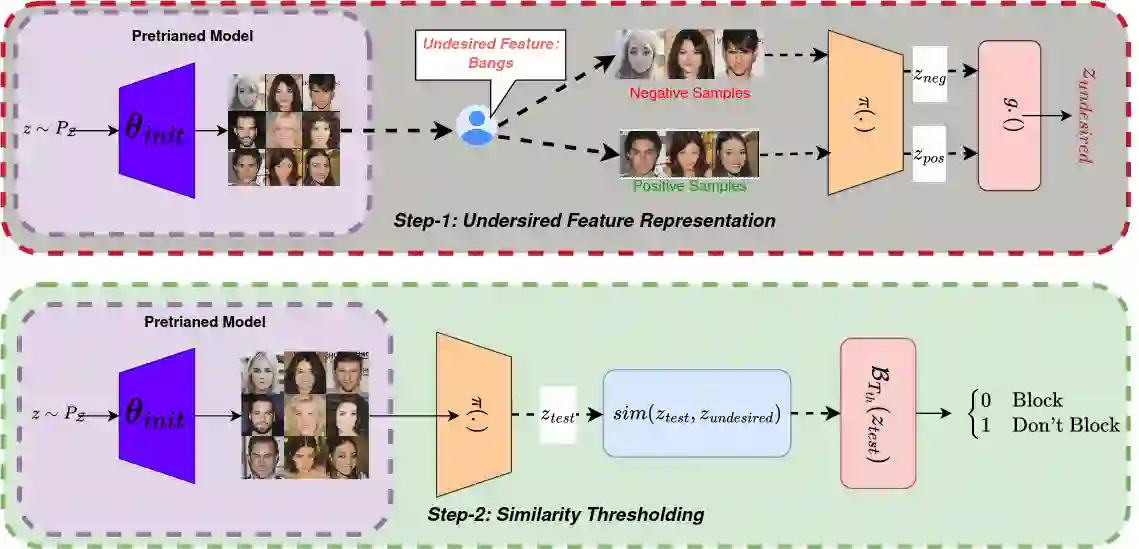
The heightened emphasis on the regulation of deep generative models, propelled by escalating concerns pertaining to privacy and compliance with regulatory frameworks, underscores the imperative need for precise control mechanisms over these models. This urgency is particularly underscored by instances in which generative models generate outputs that encompass objectionable, offensive, or potentially injurious content. In response, machine unlearning has emerged to selectively forget specific knowledge or remove the influence of undesirable data subsets from pre-trained models. However, modern machine unlearning approaches typically assume access to model parameters and architectural details during unlearning, which is not always feasible. In multitude of downstream tasks, these models function as black-box systems, with inaccessible pre-trained parameters, architectures, and training data. In such scenarios, the possibility of filtering undesired outputs becomes a practical alternative. The primary goal of this study is twofold: first, to elucidate the relationship between filtering and unlearning processes, and second, to formulate a methodology aimed at mitigating the display of undesirable outputs generated from models characterized as black-box systems. Theoretical analysis in this study demonstrates that, in the context of black-box models, filtering can be seen as a form of weak unlearning. Our proposed \textbf{\textit{Feature Aware Similarity Thresholding(FAST)}} method effectively suppresses undesired outputs by systematically encoding the representation of unwanted features in the latent space.
翻译:随着隐私保护和监管合规要求的日益提升,对深度生成模型的精准控制机制需求愈发迫切,尤其是当这些模型生成包含不当、冒犯性或潜在有害内容时尤为突出。为此,机器遗忘技术应运而生,旨在选择性遗忘特定知识或移除预训练模型中不良数据子集的影响。然而,现有机器遗忘方法通常需要访问模型参数和架构细节,这在实践中往往难以实现。在众多下游任务中,这些模型作为黑盒系统运行,其预训练参数、架构和训练数据均不可访问。在此类场景下,过滤不良输出成为可行的替代方案。本研究致力于实现双重目标:首先阐明过滤过程与遗忘机制间的关联性;其次提出一种能够缓解黑盒模型生成不良输出问题的系统化方法。理论分析表明,在黑盒模型场景下,过滤可被视为一种弱遗忘形式。我们提出的\textbf{\textit{特征感知相似性阈值方法(FAST)}}通过系统性地编码潜在空间中不良特征的表示,有效抑制了非期望输出的生成。