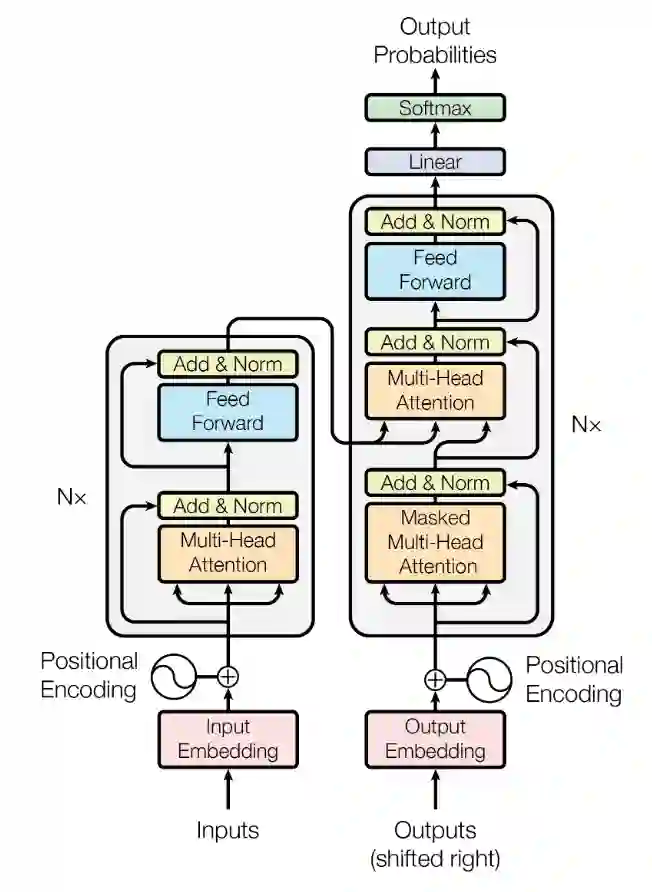
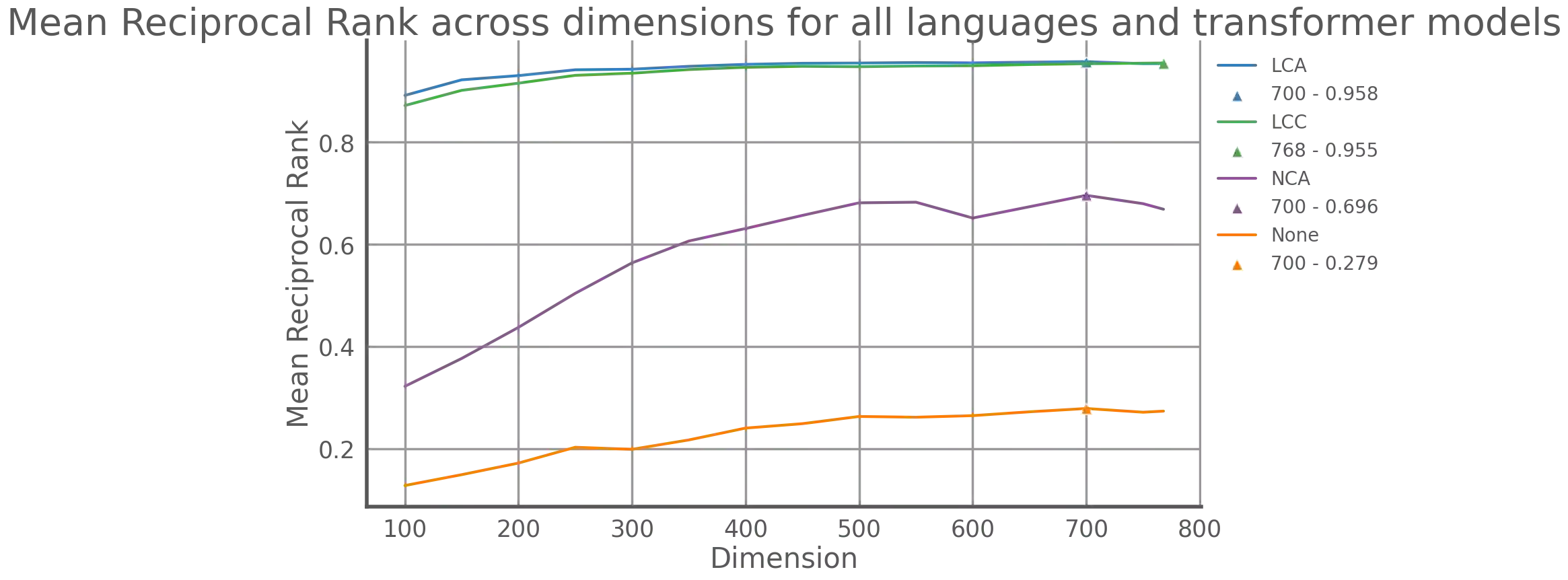
Recommendation systems, for documents, have become tools to find relevant content on the Web. However, these systems have limitations when it comes to recommending documents in languages different from the query language, which means they might overlook resources in non-native languages. This research focuses on representing documents across languages by using Transformer Leveraged Document Representations (TLDRs) that are mapped to a cross-lingual domain. Four multilingual pre-trained transformer models (mBERT, mT5 XLM RoBERTa, ErnieM) were evaluated using three mapping methods across 20 language pairs representing combinations of five selected languages of the European Union. Metrics like Mate Retrieval Rate and Reciprocal Rank were used to measure the effectiveness of mapped TLDRs compared to non-mapped ones. The results highlight the power of cross-lingual representations achieved through pre-trained transformers and mapping approaches suggesting a promising direction for expanding beyond language connections, between two specific languages.
翻译:推荐系统作为文档领域的重要工具,能够帮助用户在网络上发现相关内容。然而,当需推荐与查询语言不同的文档时,这些系统存在局限性,可能因此忽略非母语资源。本研究聚焦于利用映射至跨语言域的Transformer增强文档表示(TLDRs)来实现文档的跨语言表征。通过三种映射方法,对四个多语言预训练Transformer模型(mBERT、mT5、XLM-RoBERTa、ErnieM)在代表五种欧盟语言组合的20个语言对上进行评估。采用伴侣检索率和倒数排名等指标,对比映射与非映射TLDRs的效果。实验结果表明,通过预训练Transformer与映射方法获得的跨语言表征具有显著优势,为突破局限于两种特定语言之间的语言连接拓展提供了有前景的研究方向。