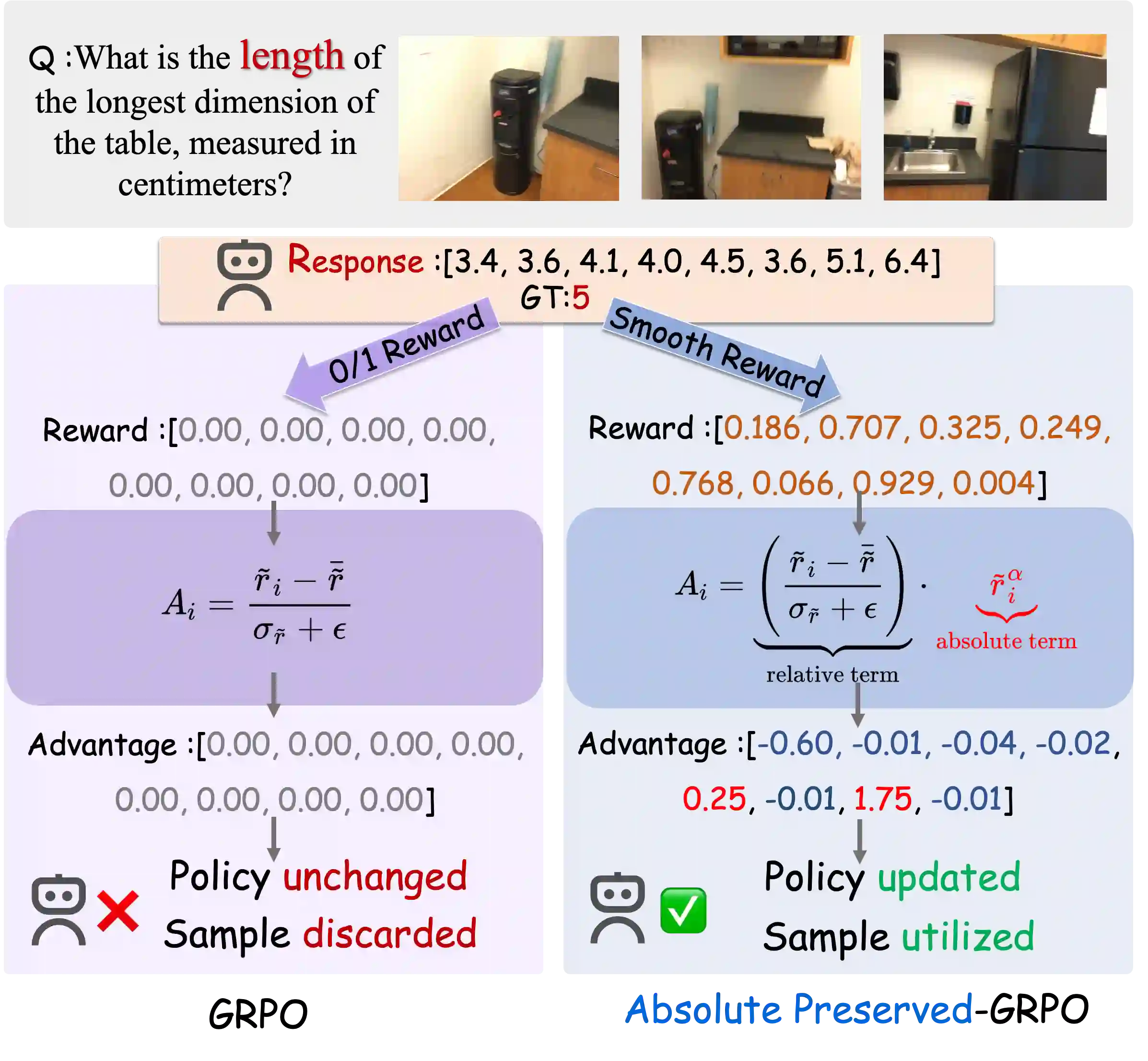
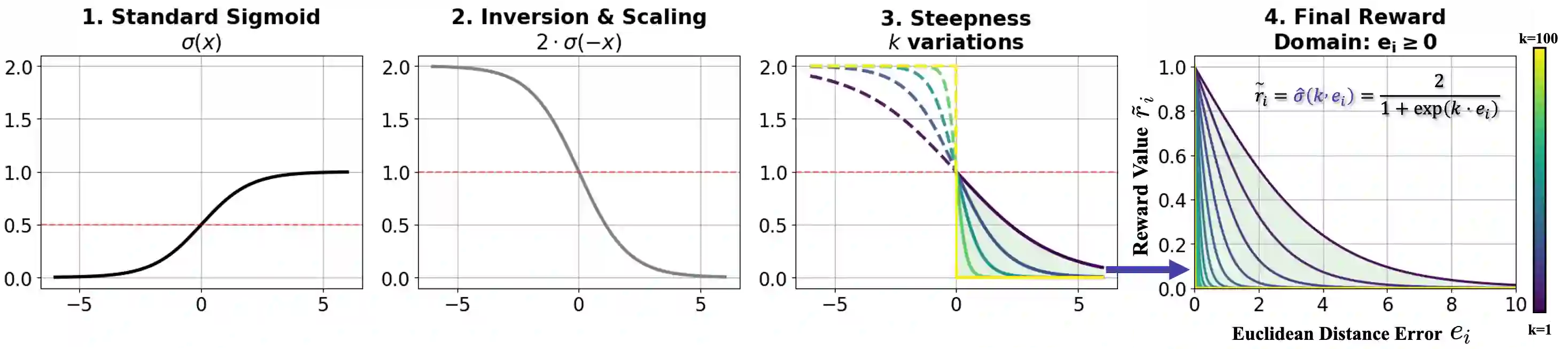
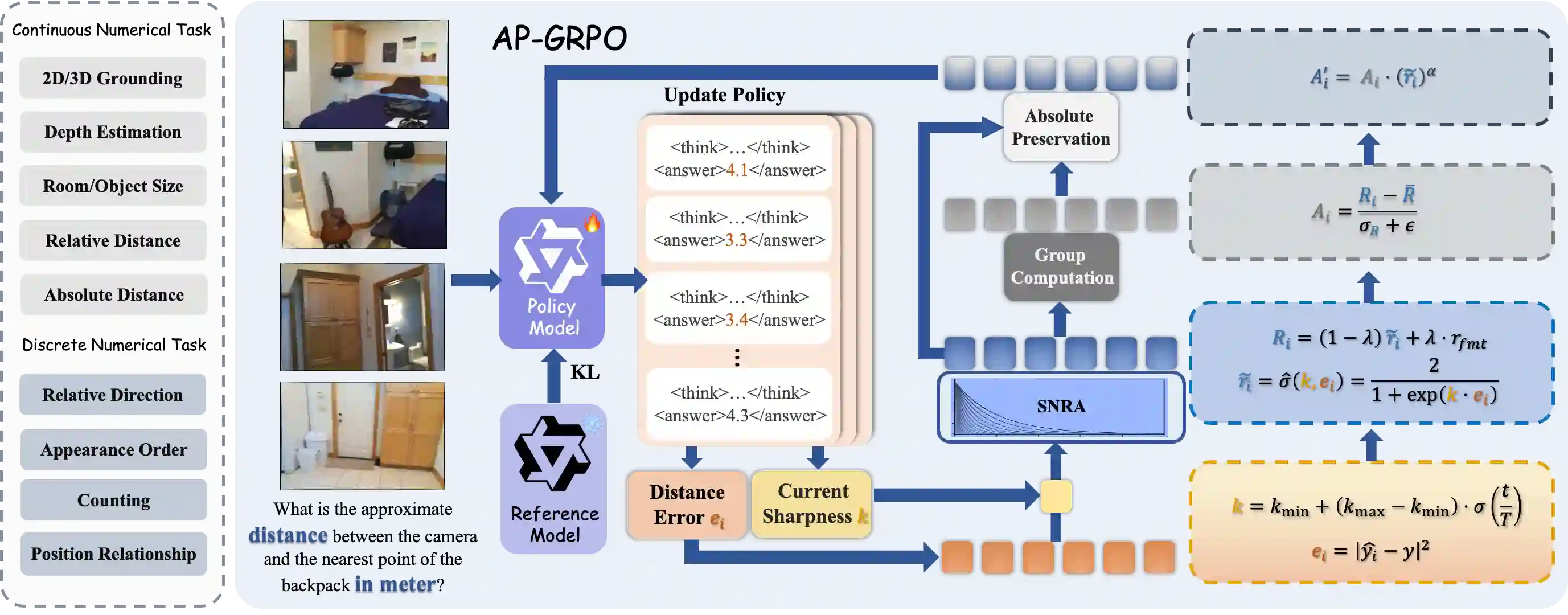
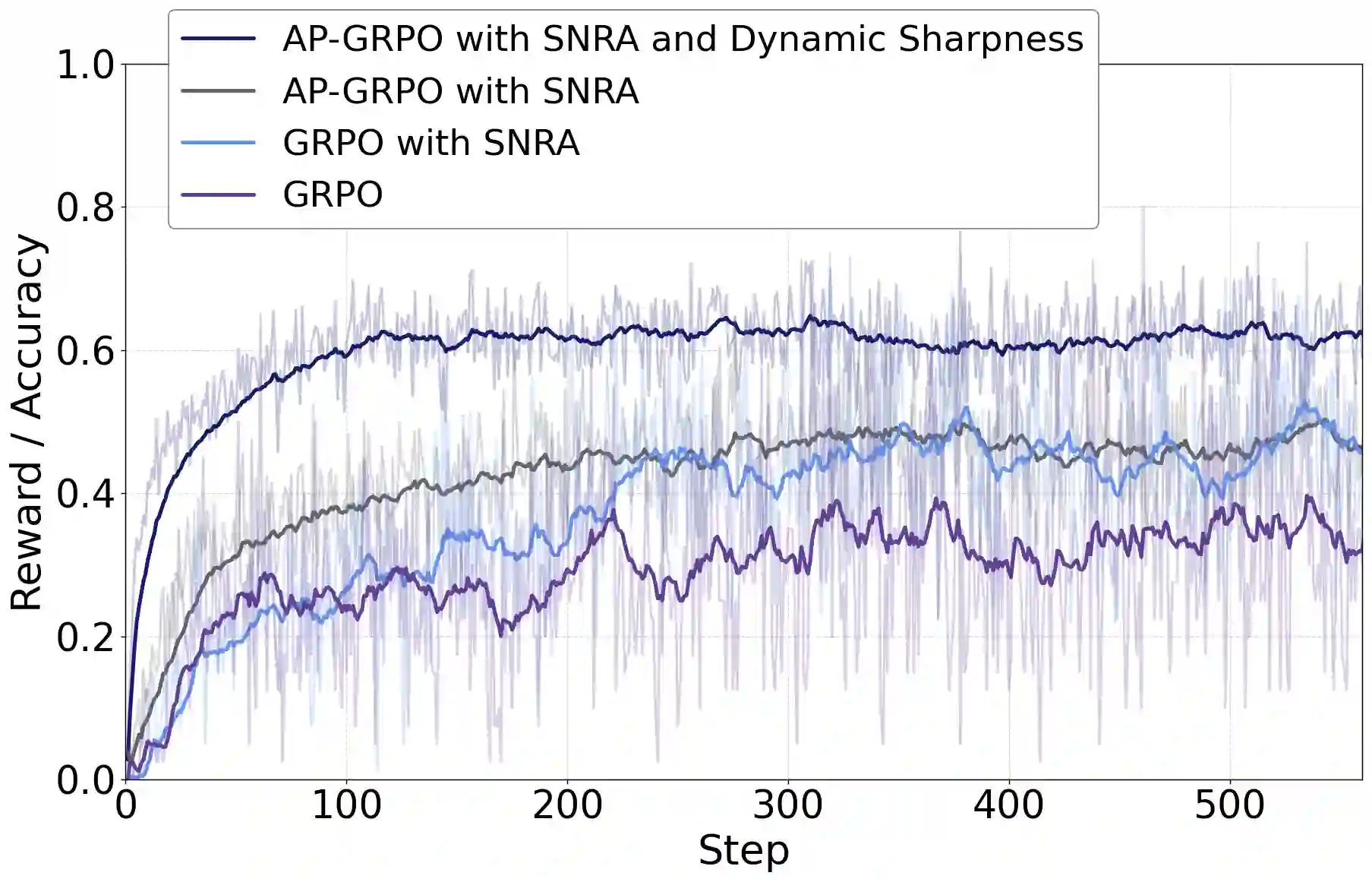
Vision-Language Models (VLMs) face a critical bottleneck in achieving precise numerical prediction for 3D scene understanding. Traditional reinforcement learning (RL) approaches, primarily based on relative ranking, often suffer from severe reward sparsity and gradient instability, failing to effectively exploit the verifiable signals provided by 3D physical constraints. Notably, in standard GRPO frameworks, relative normalization causes "near-miss" samples (characterized by small but non-zero errors) to suffer from advantage collapse. This leads to a severe data utilization bottleneck where valuable boundary samples are discarded during optimization. To address this, we introduce the Smooth Numerical Reward Activation (SNRA) operator and the Absolute-Preserving GRPO (AP-GRPO) framework. SNRA employs a dynamically parameterized Sigmoid function to transform raw feedback into a dense, continuous reward continuum. Concurrently, AP-GRPO integrates absolute scalar gradients to mitigate the numerical information loss inherent in conventional relative-ranking mechanisms. By leveraging this approach, we constructed Numerical3D-50k, a dataset comprising 50,000 verifiable 3D subtasks. Empirical results indicate that AP-GRPO achieves performance parity with large-scale supervised methods while maintaining higher data efficiency, effectively activating latent 3D reasoning in VLMs without requiring architectural modifications.
翻译:视觉语言模型(VLMs)在实现三维场景理解的精确数值预测方面面临关键瓶颈。传统的强化学习(RL)方法主要基于相对排序,常受严重的奖励稀疏性和梯度不稳定性困扰,无法有效利用三维物理约束提供的可验证信号。值得注意的是,在标准GRPO框架中,相对归一化会导致“近似命中”样本(以微小但非零误差为特征)遭受优势崩溃。这造成了严重的数据利用瓶颈,使得有价值的边界样本在优化过程中被丢弃。为解决此问题,我们引入了平滑数值奖励激活(SNRA)算子和绝对保持GRPO(AP-GRPO)框架。SNRA采用动态参数化的Sigmoid函数,将原始反馈转化为稠密、连续的奖励连续体。同时,AP-GRPO整合了绝对标量梯度,以缓解传统相对排序机制固有的数值信息损失。基于此方法,我们构建了Numerical3D-50k数据集,包含50,000个可验证的三维子任务。实验结果表明,AP-GRPO在保持更高数据效率的同时,实现了与大规模监督方法相当的性能,有效激活了VLMs中潜在的三维推理能力,且无需修改模型架构。