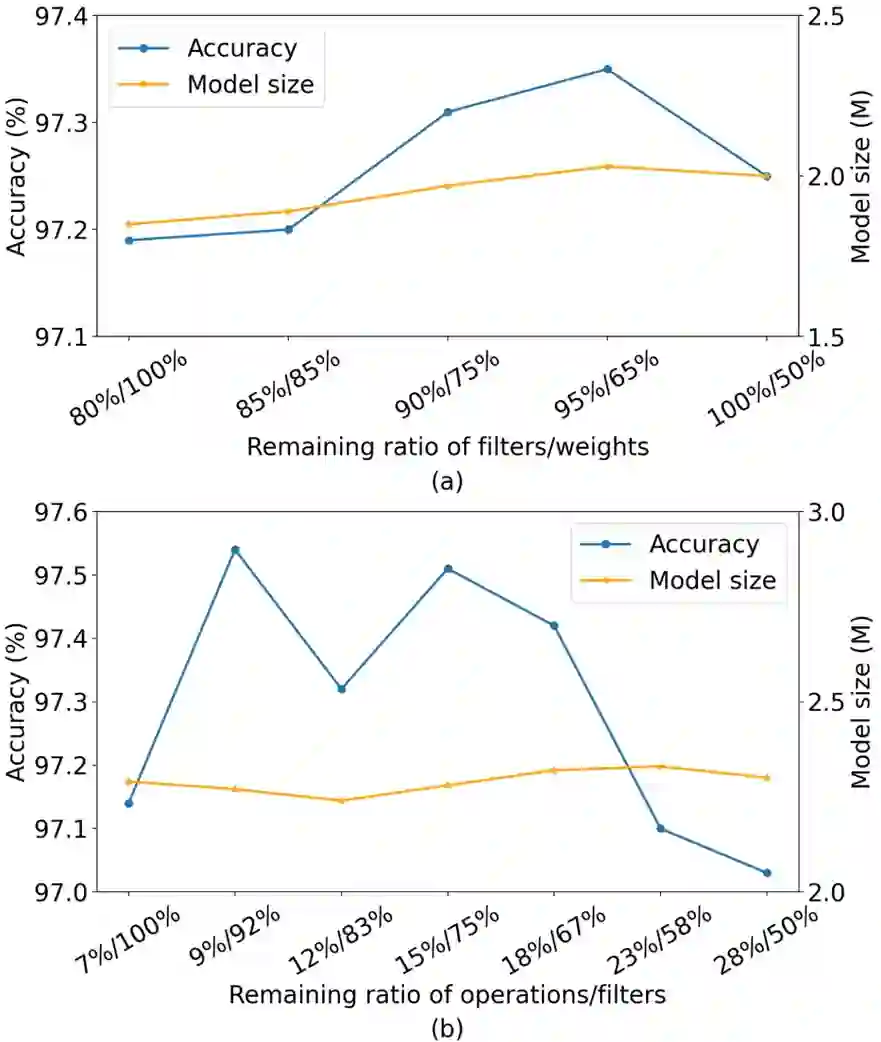
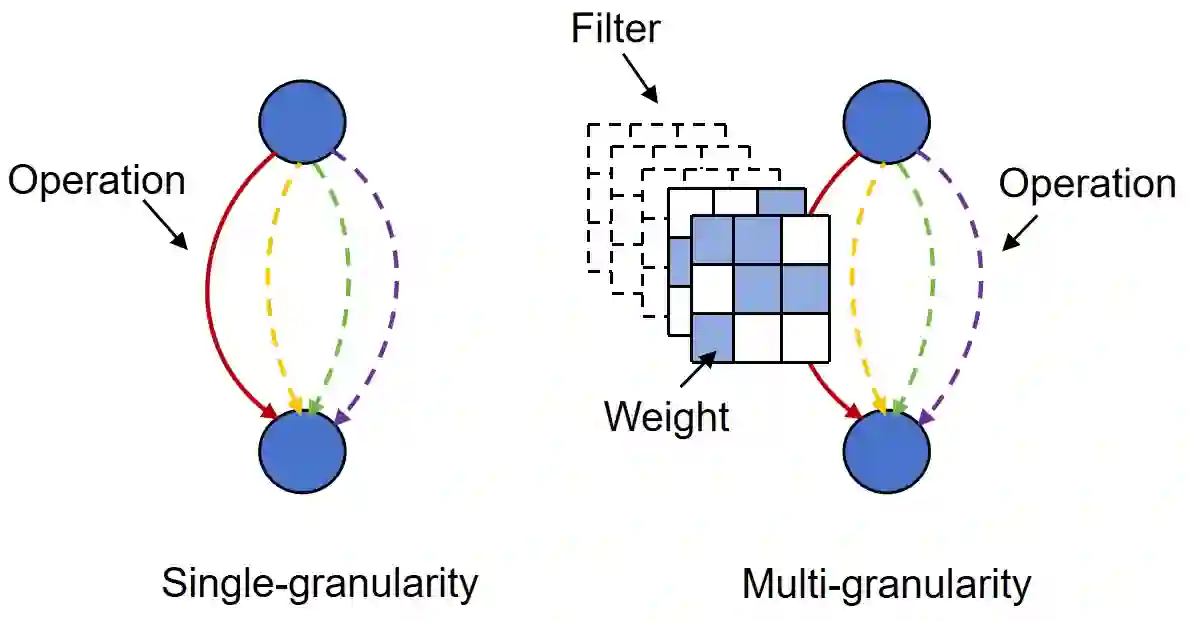
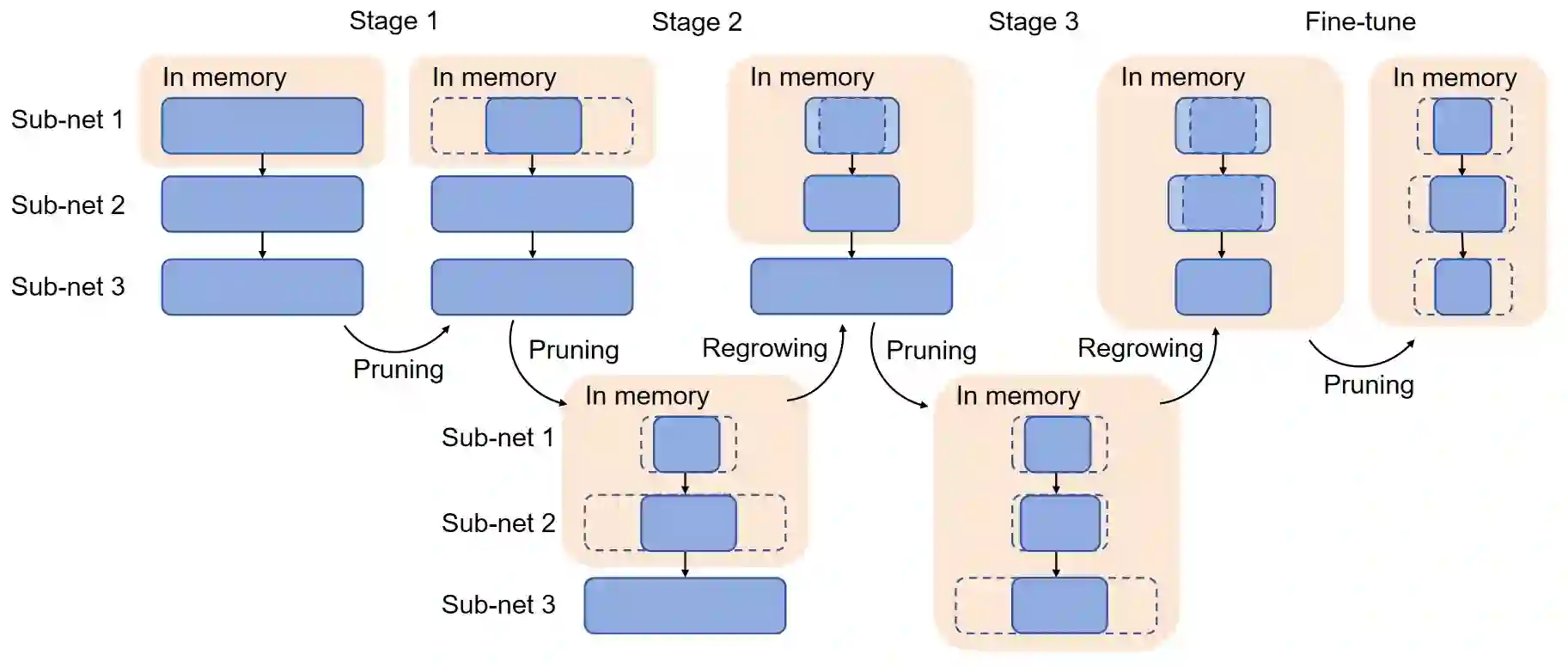
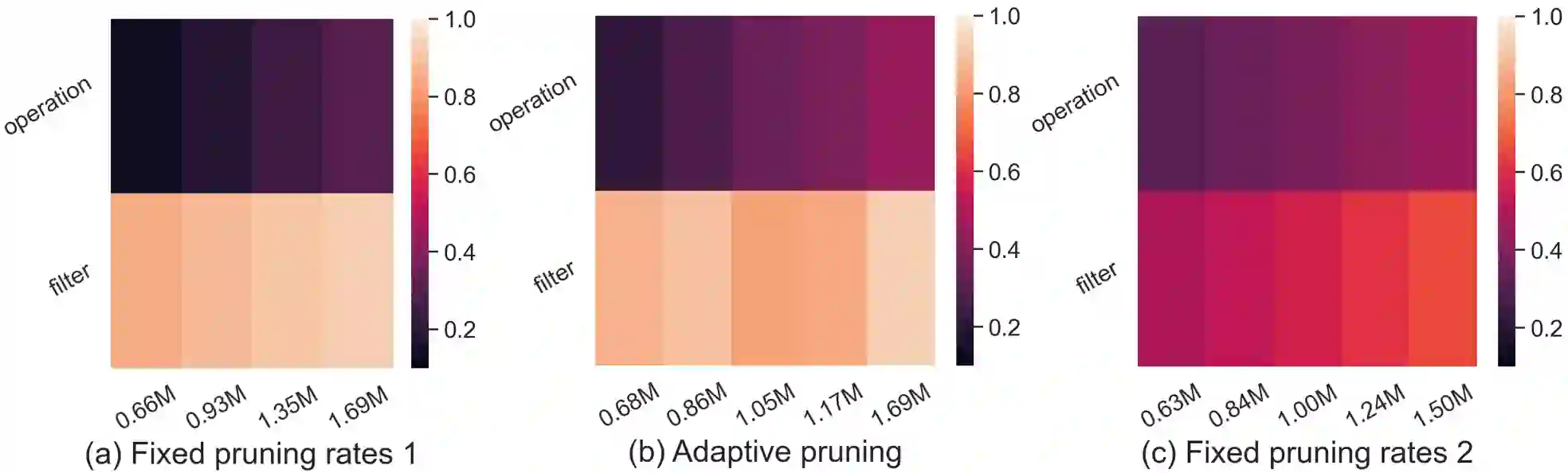
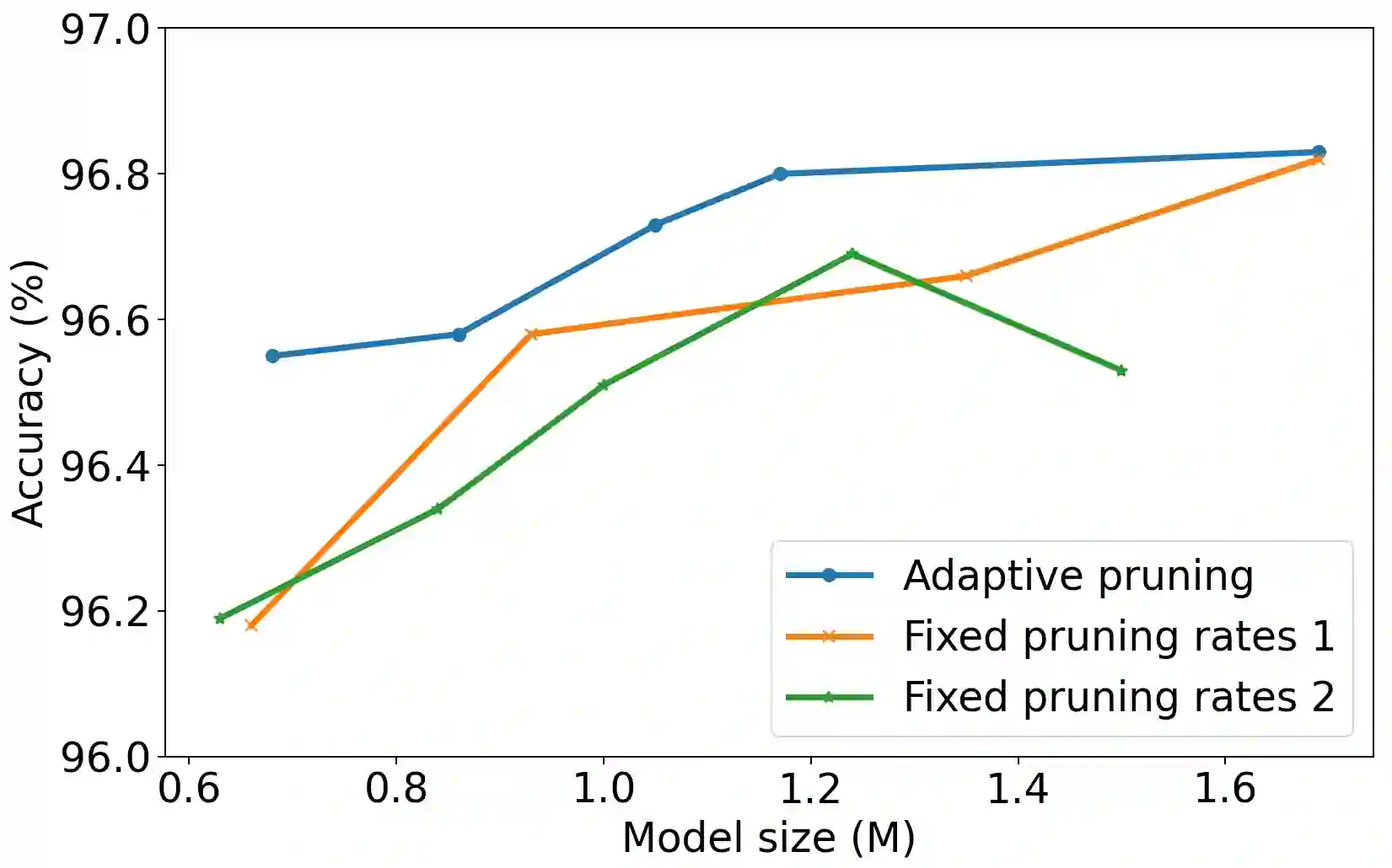
Differentiable architecture search (DAS) has become the prominent approach in the field of neural architecture search (NAS) due to its time-efficient automation of neural network design. It shifts the traditional paradigm of discrete architecture sampling and evaluation to differentiable super-net optimization and discretization. However, existing DAS methods either only conduct coarse-grained operation-level search, or restrictively explore fine-grained filter-level and weight-level units using manually-defined remaining ratios, which fail to simultaneously achieve small model size and satisfactory model performance. Additionally, they address the high memory consumption of the search process at the expense of search quality. To tackle these issues, we introduce multi-granularity architecture search (MGAS), a unified framework which aims to comprehensively and memory-efficiently explore the multi-granularity search space to discover both effective and efficient neural networks. Specifically, we learn discretization functions specific to each granularity level to adaptively determine the remaining ratios according to the evolving architecture. This ensures an optimal balance among units of different granularity levels for different target model sizes. Considering the memory demands, we break down the super-net optimization and discretization into multiple sub-net stages. By allowing re-pruning and regrowing of units in previous sub-nets during subsequent stages, we compensate for potential bias in earlier stages. Extensive experiments on CIFAR-10, CIFAR-100 and ImageNet demonstrate that MGAS outperforms other state-of-the-art methods in achieving a better trade-off between model performance and model size.
翻译:可微架构搜索因其在神经网络设计自动化中的高效性,已成为神经架构搜索领域的主流方法。它将传统离散架构采样与评估的范式转变为可微超网络优化与离散化。然而,现有可微架构搜索方法要么仅进行粗粒度的操作级搜索,要么使用人工定义的保留比例局限地探索细粒度的滤波器级和权重级单元,无法同时实现小模型尺寸与满意的模型性能。此外,这些方法以牺牲搜索质量为代价来应对搜索过程中的高内存消耗。为解决这些问题,我们提出多粒度架构搜索(MGAS)——一个旨在全面且内存高效地探索多粒度搜索空间以发现高效神经网络的统一框架。具体而言,我们为每个粒度层级学习特定的离散化函数,使其能根据演化中的架构自适应确定保留比例,从而针对不同目标模型尺寸实现各粒度层级单元间的最优平衡。考虑内存需求,我们将超网络优化与离散化分解为多个子网络阶段。通过在后续阶段允许对前序子网络中的单元进行重新剪枝与重新生长,我们补偿了早期阶段可能产生的偏差。在CIFAR-10、CIFAR-100和ImageNet上的大量实验表明,MGAS在实现模型性能与模型尺寸的更优权衡方面优于其他最新方法。