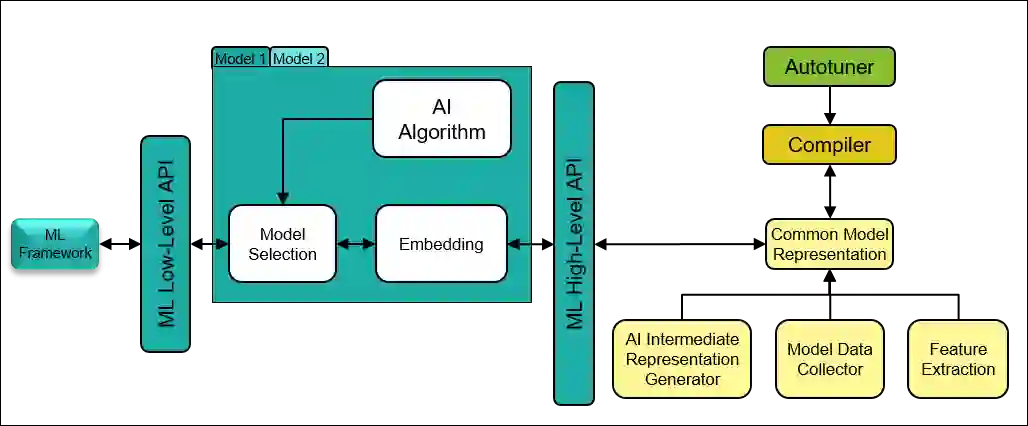
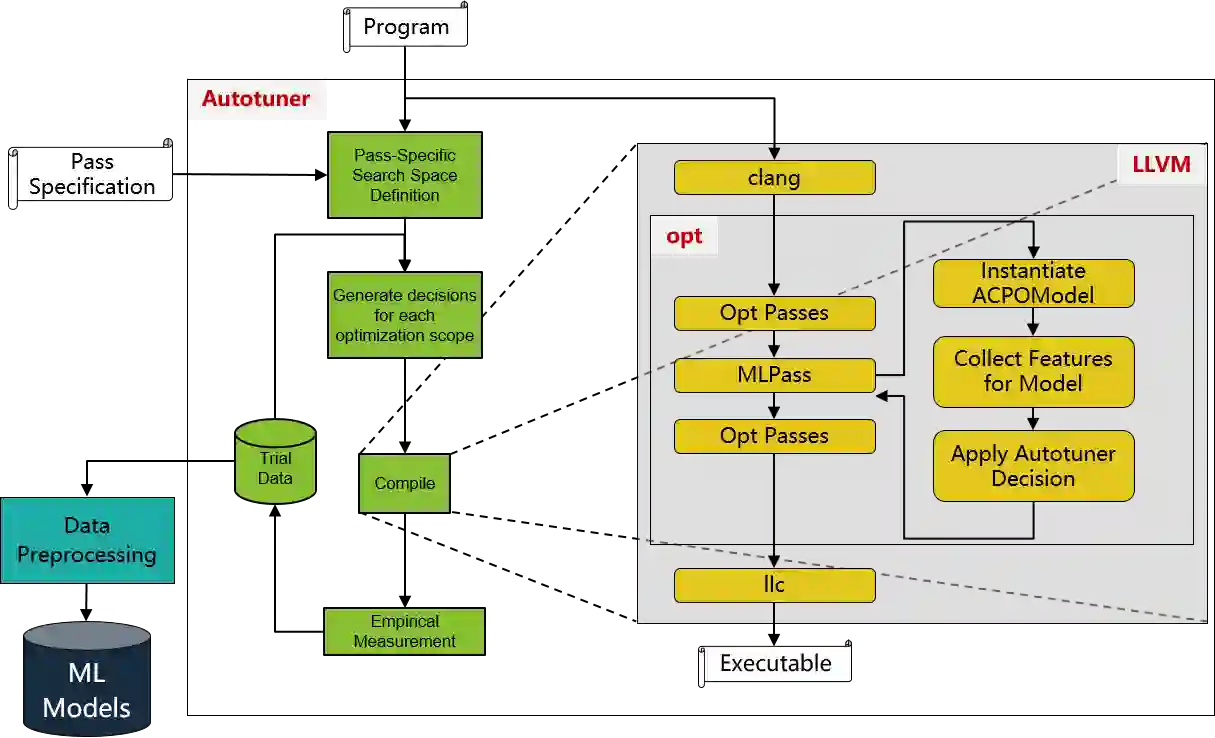
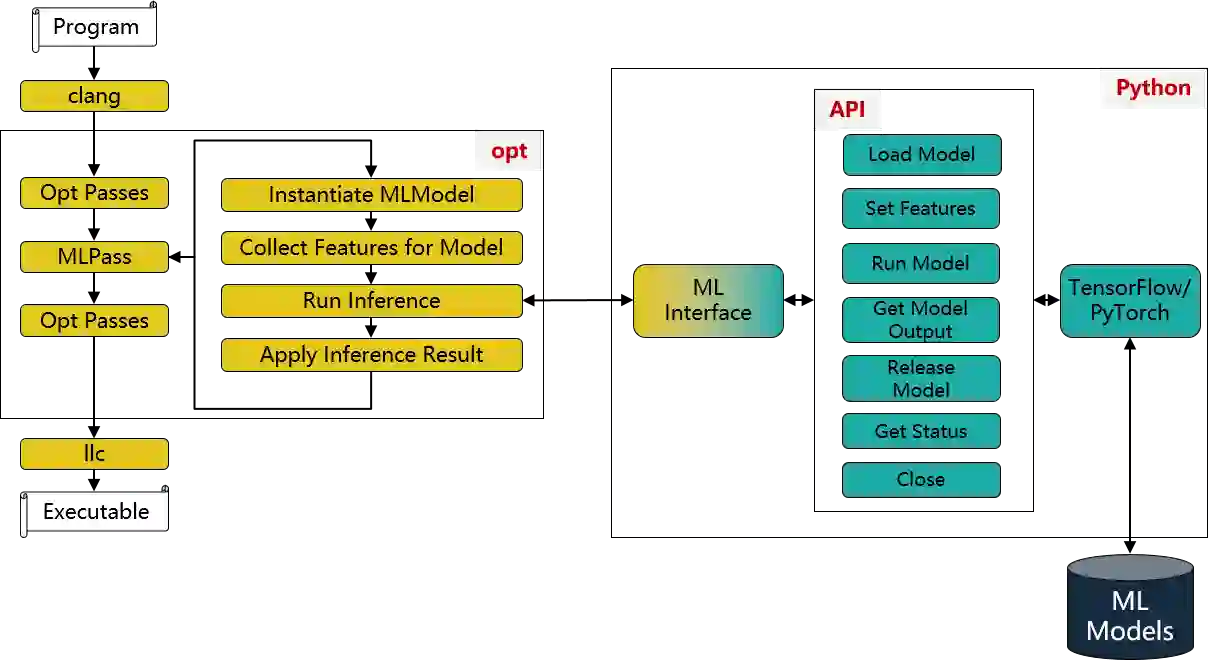
The key to performance optimization of a program is to decide correctly when a certain transformation should be applied by a compiler. Traditionally, such profitability decisions are made by hand-coded algorithms tuned for a very small number of benchmarks, usually requiring a great deal of effort to be retuned when the benchmark suite changes. This is an ideal opportunity to apply machine-learning models to speed up the tuning process; while this realization has been around since the late 90s, only recent advancements in ML enabled a practical application of ML to compilers as an end-to-end framework. Even so, seamless integration of ML into the compiler would require constant rebuilding of the compiler when models are updated. This paper presents ACPO: \textbf{\underline{A}}I-Enabled \textbf{\underline{C}}ompiler-driven \textbf{\underline{P}}rogram \textbf{\underline{O}}ptimization; a novel framework to provide LLVM with simple and comprehensive tools to benefit from employing ML models for different optimization passes. We first showcase the high-level view, class hierarchy, and functionalities of ACPO and subsequently, demonstrate \taco{a couple of use cases of ACPO by ML-enabling the Loop Unroll and Function Inlining passes and describe how ACPO can be leveraged to optimize other passes. Experimental results reveal that ACPO model for Loop Unroll is able to gain on average 4\% and 3\%, 5.4\%, 0.2\% compared to LLVM's O3 optimization when deployed on Polybench, Coral-2, CoreMark, and Graph-500, respectively. Furthermore, by adding the Inliner model as well, ACPO is able to provide up to 4.5\% and 2.4\% on Polybench and Cbench compared with LLVM's O3 optimization, respectively.
翻译:程序性能优化的关键在于正确判断何时应让编译器应用某种变换。传统上,这种收益性决策由手工编码的算法完成,这些算法针对极少数基准测试进行调优,且当基准测试套件发生变化时,通常需要耗费大量精力重新调优。这为应用机器学习模型加速调优过程提供了理想契机;尽管这一认识自90年代末便已存在,但直到近期机器学习领域的进展才使得将机器学习作为端到端框架实际应用于编译器成为可能。即便如此,将机器学习无缝集成到编译器中仍需要在模型更新时持续重建编译器。本文提出ACPO:人工智能驱动的编译器程序优化——一个新颖框架,旨在为LLVM提供简洁全面的工具,使其能够通过在不同优化阶段采用机器学习模型受益。我们首先展示ACPO的高层视图、类层次结构和功能,随后通过启用循环展开和内联函数优化的机器学习功能,演示两个ACPO应用案例,并描述如何利用ACPO优化其他优化阶段。实验结果表明,在Polybench、Coral-2、CoreMark和Graph-500基准测试上部署时,用于循环展开的ACPO模型相比LLVM的O3优化分别平均获得4%、3%、5.4%和0.2%的性能提升。此外,结合内联模型后,ACPO在Polybench和Cbench上相比LLVM的O3优化分别可提供高达4.5%和2.4%的性能提升。