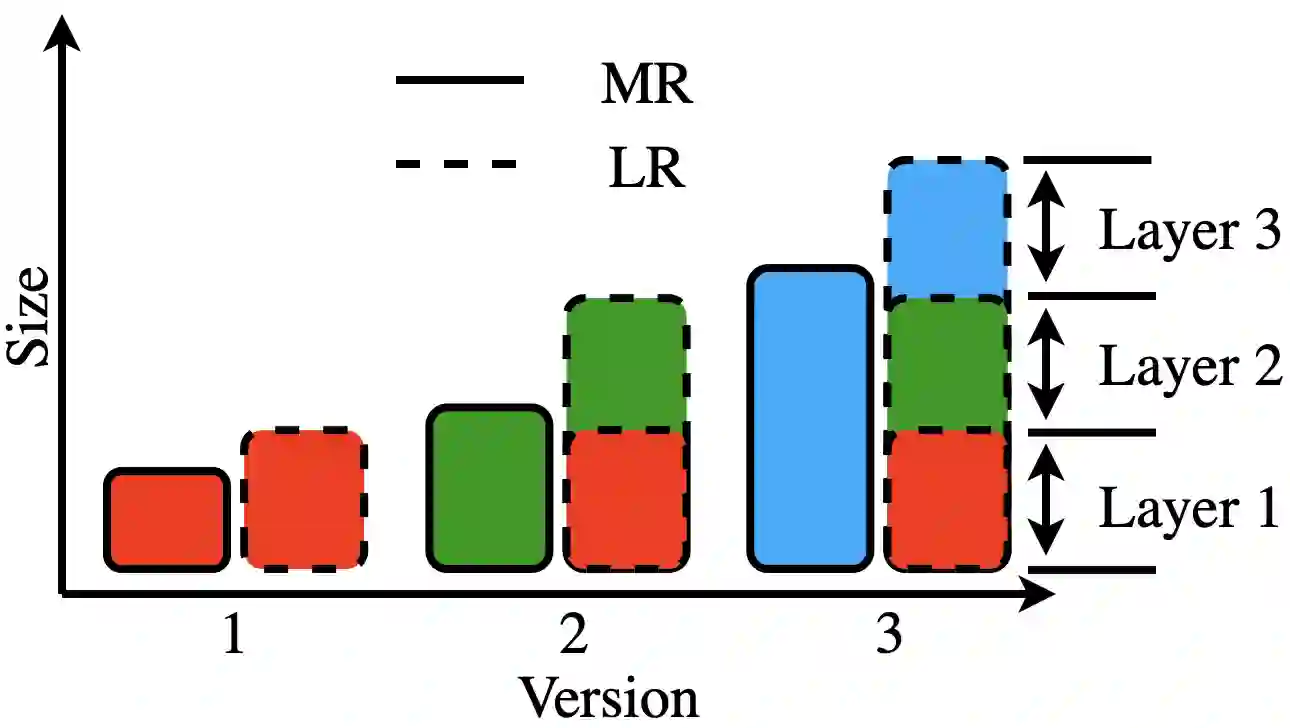
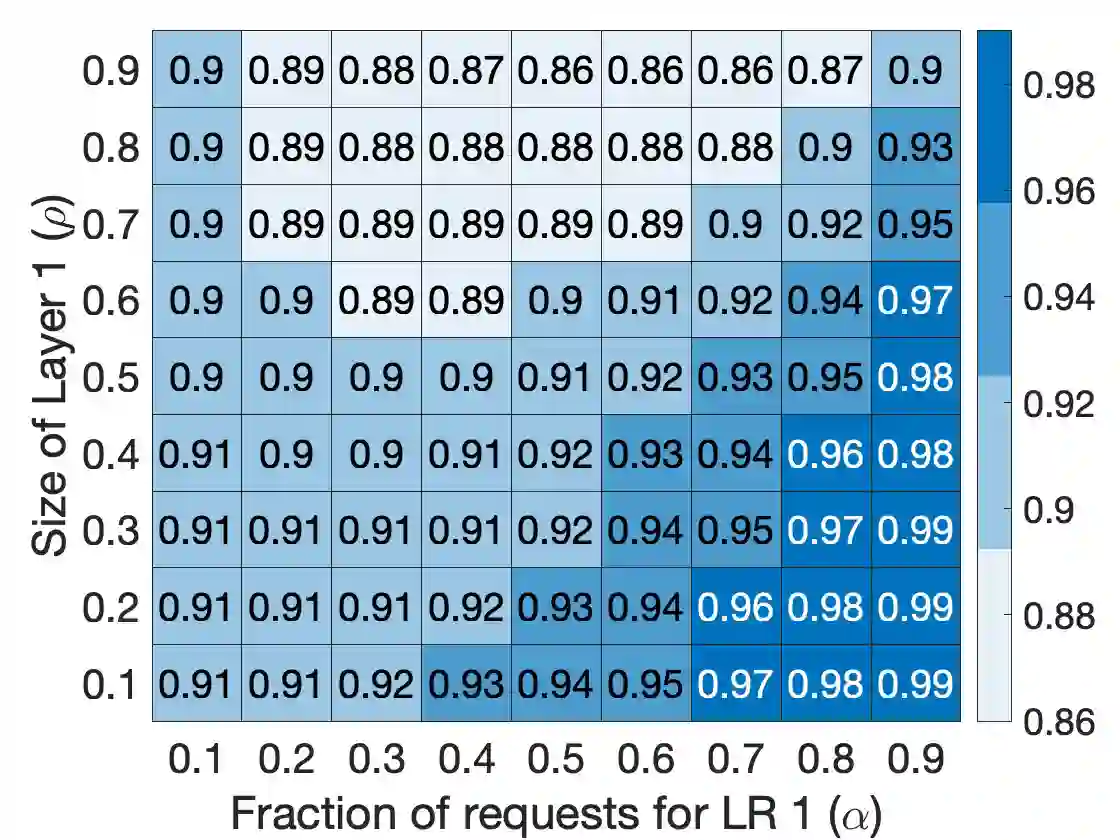
The effective management of large amounts of data processed or required by today's cloud or edge computing systems remains a fundamental challenge. This paper focuses on cache management for applications where data objects can be stored in layered representations. In such representations, each additional data layer enhances the "quality" of the object's version but comes with an incremental cost of memory space. This layered approach proves beneficial in various scenarios, including the delivery of zoomable maps, video coding, future Virtual Reality gaming, and layered neural network models where additional data layers improve inference accuracy. In systems where users or devices demand different versions of a data object, layered representations offer flexibility for caching policies to achieve improved hit rates. In this paper, we explore the performance of various traditionally studied caching policies, such as Belady, LRU, and LFU, both with and without layering. To this end, we develop an asymptotically accurate analytical model for Layered LRU (LLRU). We study how the performance of LLRU is impacted by factors such as the number of layers, the popularity of different objects and layers, and overheads associated with storing layered representations. For instance, we show that, for LLRU, more layers are not always beneficial and indeed performance depends in subtle ways on the popularity and size profiles of layers.
翻译:当今云或边缘计算系统处理或所需海量数据的有效管理仍是一项根本性挑战。本文聚焦于数据对象可采用分层表示存储的应用程序缓存管理。在此类表示中,每个新增数据层都会提升对象版本的"质量",但需付出内存空间的增量成本。这种分层方法在多种场景中被证明具有优势,包括可缩放地图的交付、视频编码、未来虚拟现实游戏,以及通过新增数据层提升推理准确度的分层神经网络模型。在用户或设备需要数据对象不同版本的系统环境中,分层表示为缓存策略提供了提升命中率的灵活性。本文探究了多种传统缓存策略(如Belady、LRU和LFU)在分层与非分层配置下的性能表现。为此,我们为分层LRU(LLRU)建立了渐近精确的分析模型,并研究层数、不同对象与层级的流行度、以及分层表示存储开销等因素对LLRU性能的影响。例如,我们证明对于LLRU而言,更多层级并非总是有益的,其性能实际上以微妙的方式取决于各层级的流行度与规模分布特征。