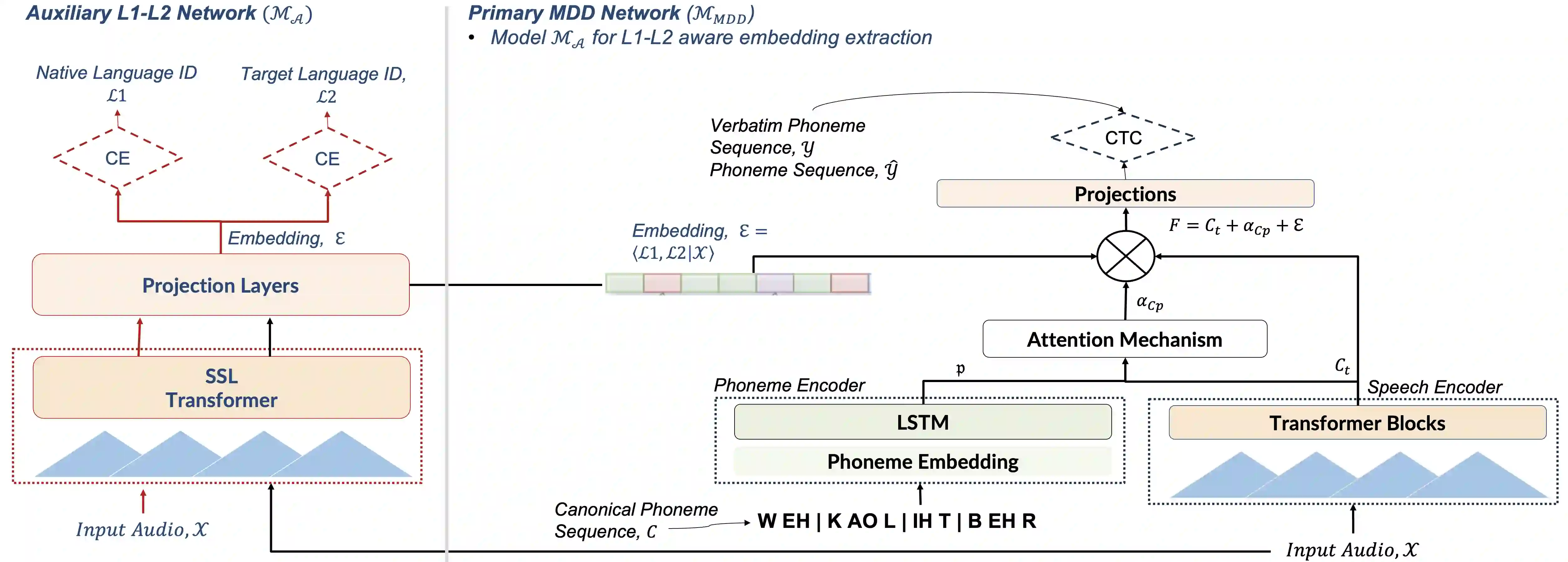
The phonological discrepancies between a speaker's native (L1) and the non-native language (L2) serves as a major factor for mispronunciation. This paper introduces a novel multilingual MDD architecture, L1-MultiMDD, enriched with L1-aware speech representation. An end-to-end speech encoder is trained on the input signal and its corresponding reference phoneme sequence. First, an attention mechanism is deployed to align the input audio with the reference phoneme sequence. Afterwards, the L1-L2-speech embedding are extracted from an auxiliary model, pretrained in a multi-task setup identifying L1 and L2 language, and are infused with the primary network. Finally, the L1-MultiMDD is then optimized for a unified multilingual phoneme recognition task using connectionist temporal classification (CTC) loss for the target languages: English, Arabic, and Mandarin. Our experiments demonstrate the effectiveness of the proposed L1-MultiMDD framework on both seen -- L2-ARTIC, LATIC, and AraVoiceL2v2; and unseen -- EpaDB and Speechocean762 datasets. The consistent gains in PER, and false rejection rate (FRR) across all target languages confirm our approach's robustness, efficacy, and generalizability.
翻译:说话者母语(L1)与非母语(L2)之间的音系差异是导致发音错误的主要因素。本文提出了一种新颖的多语言发音错误检测架构L1-MultiMDD,该架构融入了L1感知的语音表征。我们采用端到端语音编码器对输入信号及其对应的参考音素序列进行训练。首先,利用注意力机制将输入音频与参考音素序列对齐;随后,从辅助模型中提取L1-L2语音嵌入(该辅助模型通过多任务预训练识别L1和L2语言),并将其注入主网络。最终,L1-MultiMDD通过连接时序分类损失函数针对目标语言(英语、阿拉伯语和汉语普通话)进行统一多语言音素识别任务的优化。实验证明,所提出的L1-MultiMDD框架在已见数据集(L2-ARTIC、LATIC、AraVoiceL2v2)和未见数据集(EpaDB、Speechocean762)上均表现出有效性。在所有目标语言上,音素错误率和错误拒绝率的持续提升证实了本方法的稳健性、有效性和泛化能力。