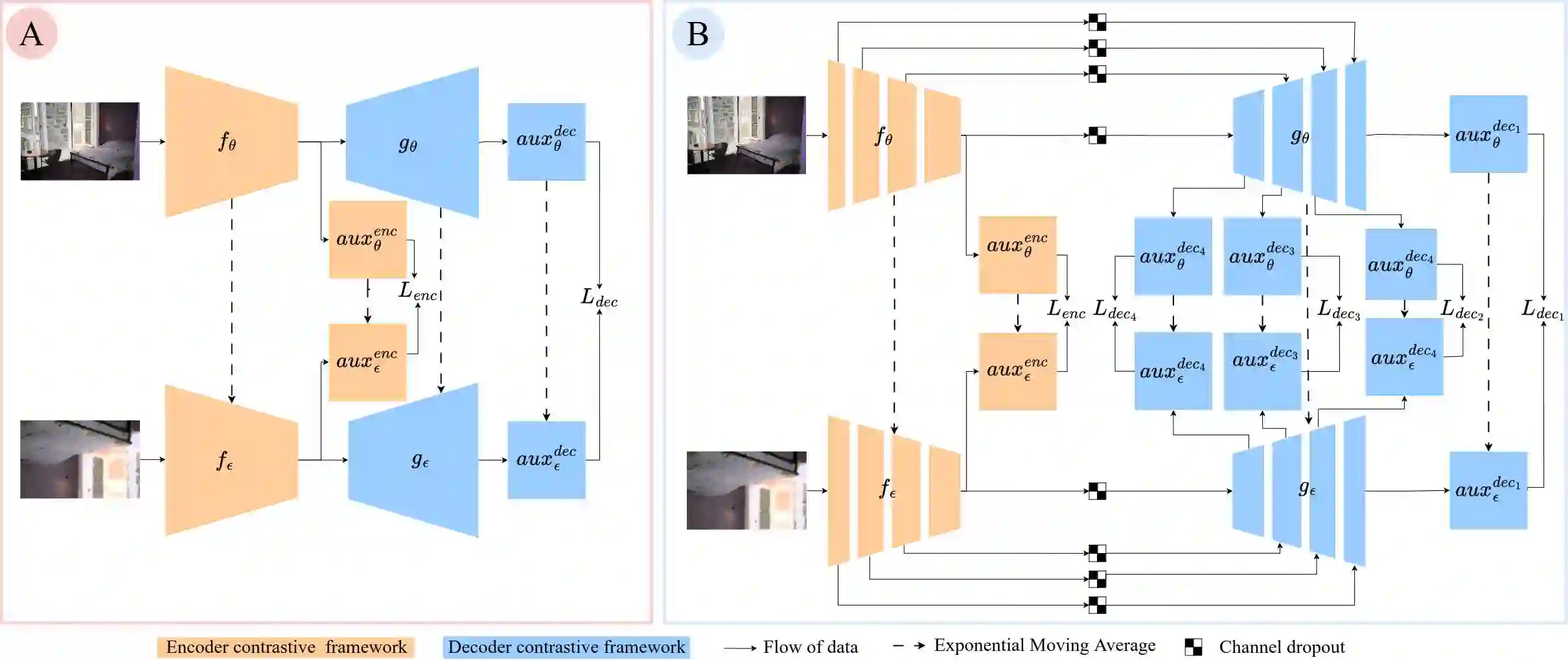
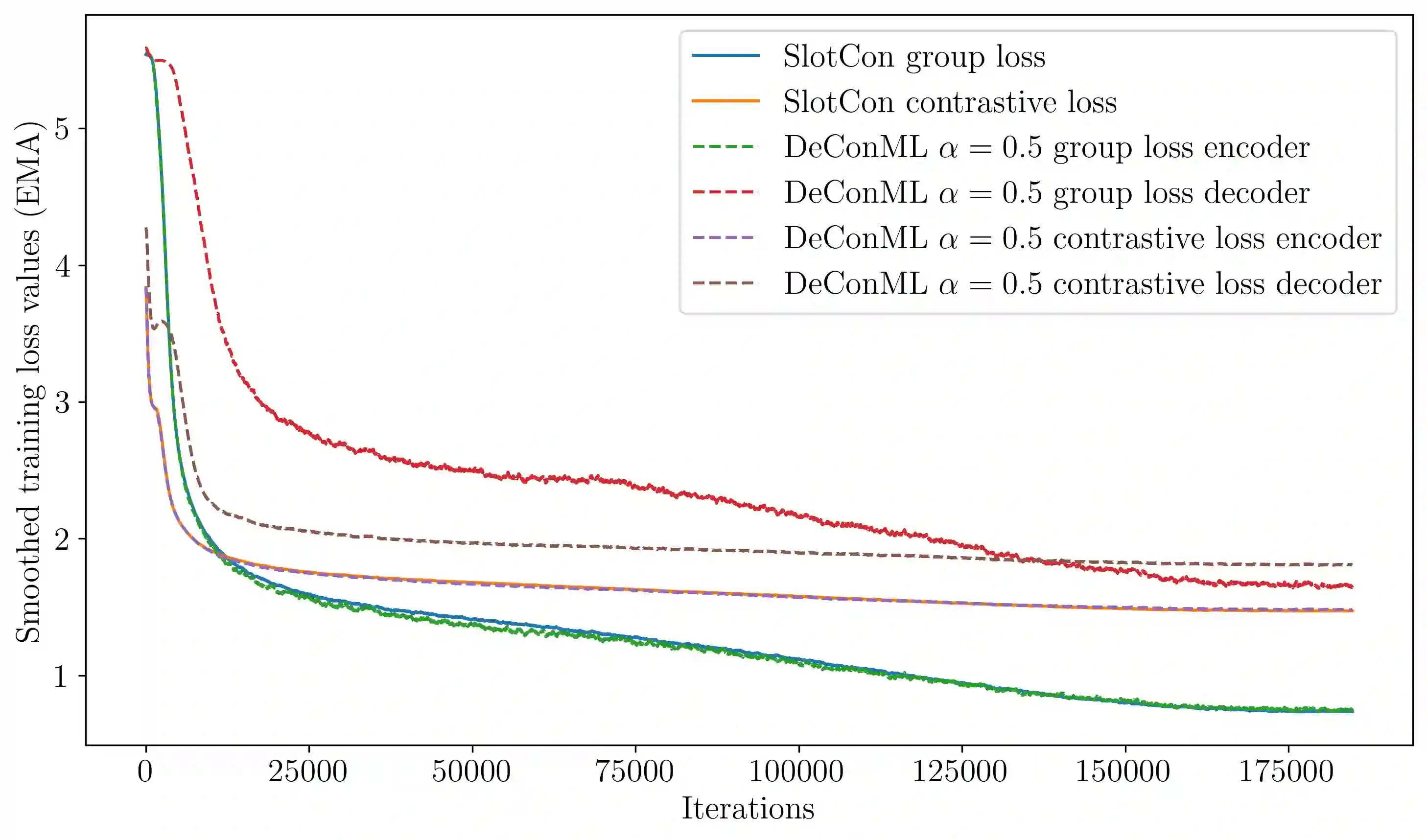
Contrastive learning methods in self-supervised settings have primarily focused on pre-training encoders, while decoders are typically introduced and trained separately for downstream dense prediction tasks. However, this conventional approach overlooks the potential benefits of jointly pre-training both encoder and decoder. In this paper, we propose DeCon, an efficient encoder-decoder self-supervised learning (SSL) framework that supports joint contrastive pre-training. We first extend existing SSL architectures to accommodate diverse decoders and their corresponding contrastive losses. Then, we introduce a weighted encoder-decoder contrastive loss with non-competing objectives to enable the joint pre-training of encoder-decoder architectures. By adapting a contrastive SSL framework for dense prediction, DeCon establishes consistent state-of-the-art performance on most of the evaluated tasks when pre-trained on Imagenet-1K, COCO and COCO+. Notably, when pre-training a ResNet-50 encoder on COCO dataset, DeCon improves COCO object detection and instance segmentation compared to the baseline framework by +0.37 AP and +0.32 AP, respectively, and boosts semantic segmentation by +1.42 mIoU on Pascal VOC and by +0.50 mIoU on Cityscapes. These improvements generalize across recent backbones, decoders, datasets, and dense tasks beyond segmentation and object detection, and persist in out-of-domain scenarios, including limited-data settings, demonstrating that joint pre-training significantly enhances representation quality for dense prediction. Code is available at https://github.com/sebquetin/DeCon.git.
翻译:自监督环境下的对比学习方法主要集中于编码器的预训练,而解码器通常为下游密集预测任务单独引入和训练。然而,这种传统方法忽视了联合预训练编码器与解码器的潜在优势。本文提出DeCon,一种高效的编码器-解码器自监督学习框架,支持联合对比预训练。我们首先扩展现有自监督学习架构以适配多种解码器及其对应的对比损失函数。随后,我们引入一种具有非竞争目标的加权编码器-解码器对比损失,以实现编码器-解码器架构的联合预训练。通过将对比自监督学习框架适配于密集预测任务,DeCon在ImageNet-1K、COCO和COCO+数据集上进行预训练后,在大多数评估任务中取得了持续领先的性能表现。值得注意的是,在COCO数据集上对ResNet-50编码器进行预训练时,DeCon相较于基线框架将COCO目标检测和实例分割性能分别提升+0.37 AP和+0.32 AP,并在Pascal VOC和Cityscapes数据集上将语义分割性能分别提升+1.42 mIoU和+0.50 mIoU。这些改进在不同骨干网络、解码器、数据集以及分割与目标检测之外的密集任务中均具有普适性,并在包括有限数据场景在内的域外场景中持续有效,证明联合预训练能显著提升密集预测的表征质量。代码发布于https://github.com/sebquetin/DeCon.git。