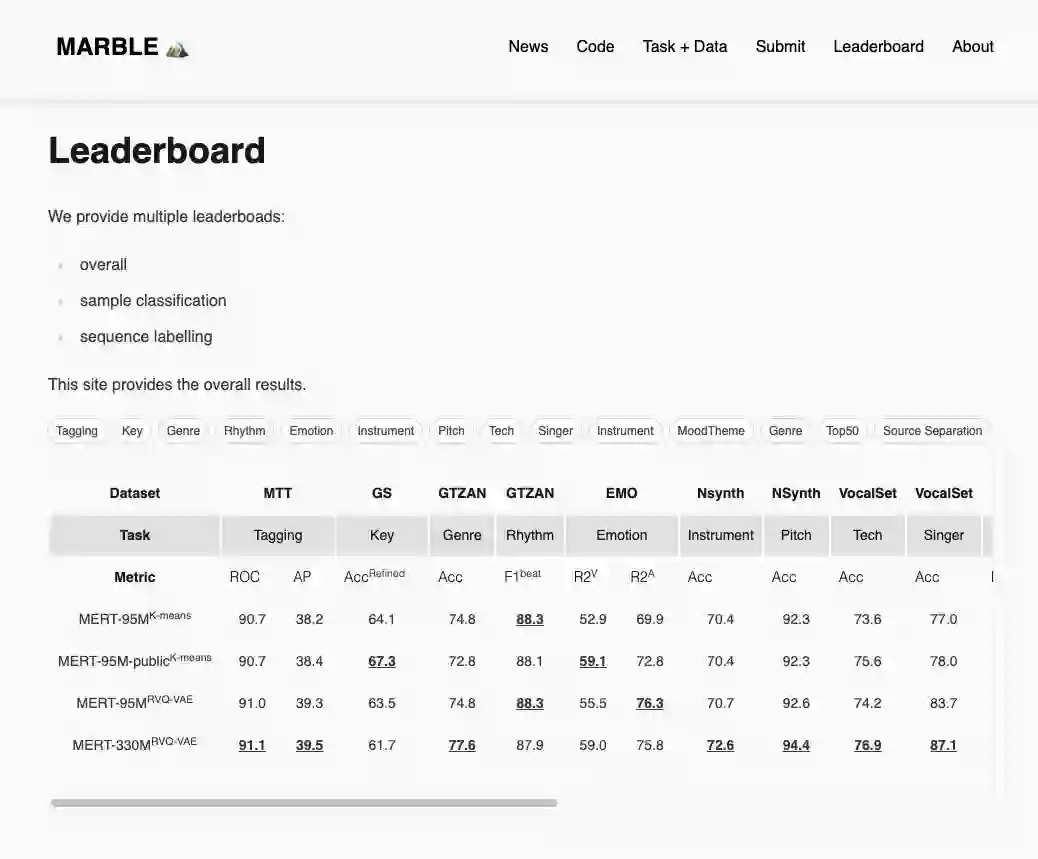
In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.
翻译:在艺术与人工智能深度交融的时代,如图像生成与小说协同创作等领域蓬勃发展,而音乐领域的人工智能研究仍相对初阶,尤其在音乐理解方面。其现状表现为:深度音乐表示研究尚不充分、大规模数据集匮乏,且缺乏通用且社区驱动的基准测试。为解决这一问题,我们提出通用评估音乐音频表示基准(Music Audio Representation Benchmark for universaL Evaluation,简称MARBLE)。该基准通过定义涵盖声学、演奏、乐谱与高层级描述的四个层级综合分类法,为多种音乐信息检索(MIR)任务提供评估标准。基于8个公开数据集构建的14项任务统一协议,我们为所有基于音乐录音开发的开源预训练模型提供了公平、标准的表示评估基线。此外,MARBLE为社区提供了一套易用、可扩展且可复现的工具包,并清晰声明数据集版权问题。结果表明,近期提出的大规模预训练音乐语言模型在大多数任务中表现最优,但仍存在进一步改进空间。排行榜与工具包仓库已发布于https://marble-bm.shef.ac.uk,以推动未来音乐人工智能研究。