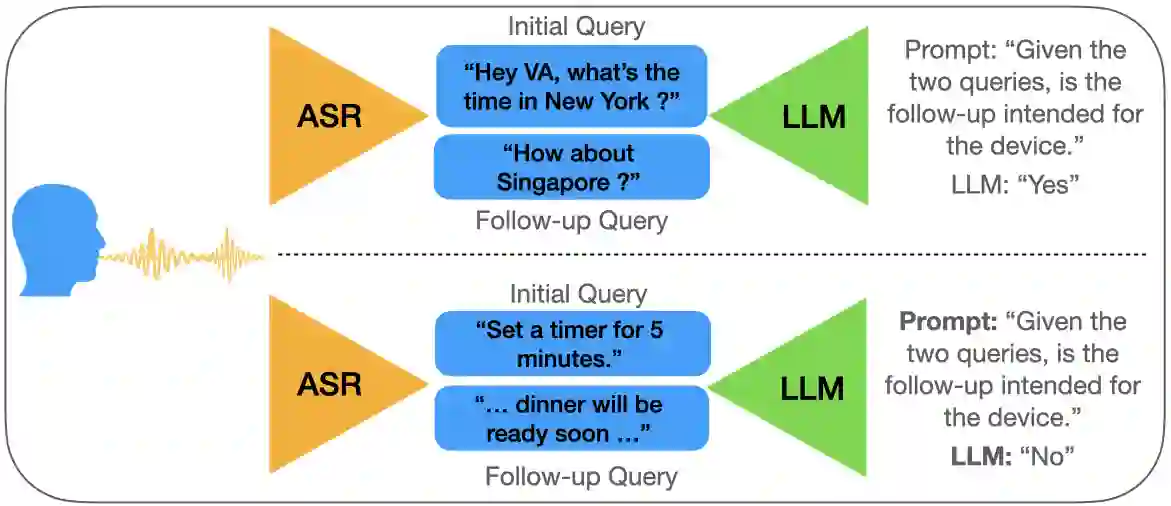
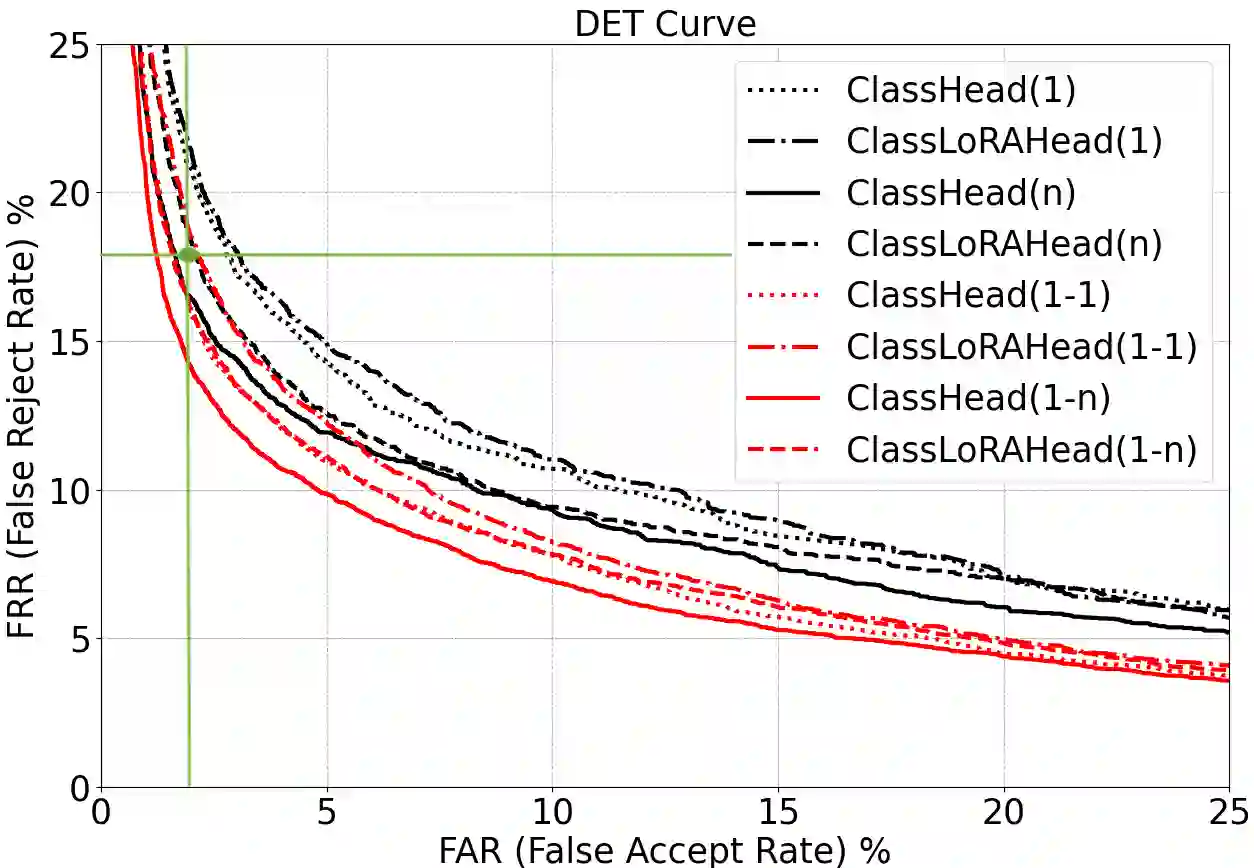
Follow-up conversations with virtual assistants (VAs) enable a user to seamlessly interact with a VA without the need to repeatedly invoke it using a keyword (after the first query). Therefore, accurate Device-directed Speech Detection (DDSD) from the follow-up queries is critical for enabling naturalistic user experience. To this end, we explore the notion of Large Language Models (LLMs) and model the first query when making inference about the follow-ups (based on the ASR-decoded text), via prompting of a pretrained LLM, or by adapting a binary classifier on top of the LLM. In doing so, we also exploit the ASR uncertainty when designing the LLM prompts. We show on the real-world dataset of follow-up conversations that this approach yields large gains (20-40% reduction in false alarms at 10% fixed false rejects) due to the joint modeling of the previous speech context and ASR uncertainty, compared to when follow-ups are modeled alone.
翻译:与虚拟助手(VAs)的后续对话使用户能够无缝地与VA交互,而无需在首次查询后重复使用关键词唤醒。因此,从后续查询中准确检测设备指向性语音(DDSD)对于实现自然的用户体验至关重要。为此,我们探索了大语言模型(LLMs)的应用,并在对后续查询(基于ASR解码文本)进行推理时,通过提示预训练的LLM或在LLM之上适配二元分类器,对首次查询进行建模。在此过程中,我们在设计LLM提示时也利用了ASR的不确定性。在真实世界的后续对话数据集上,我们证明,与单独对后续查询建模相比,由于联合建模了先前的语音上下文和ASR不确定性,该方法带来了显著的性能提升(在10%固定错误拒绝率下,错误警报减少了20-40%)。