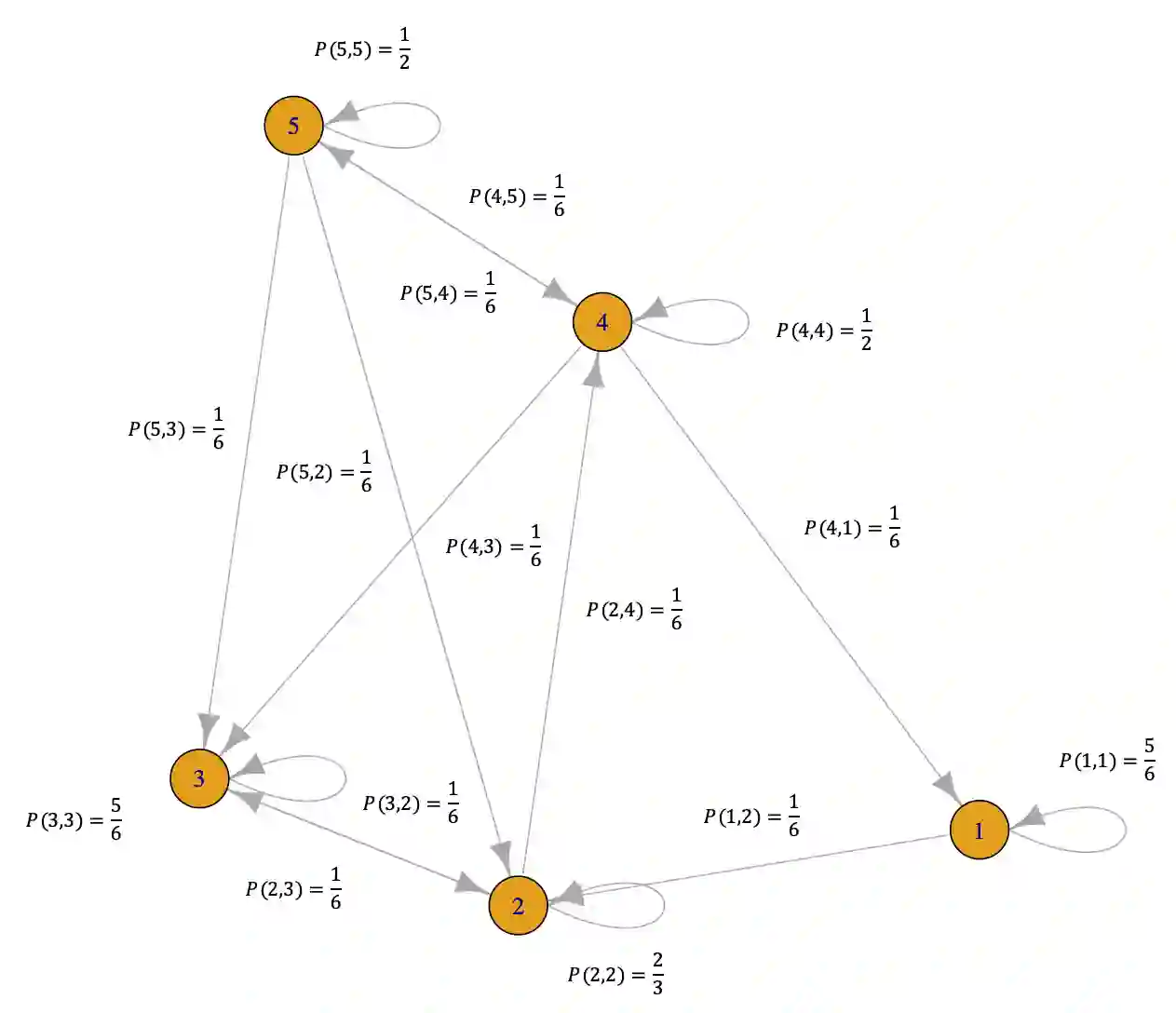
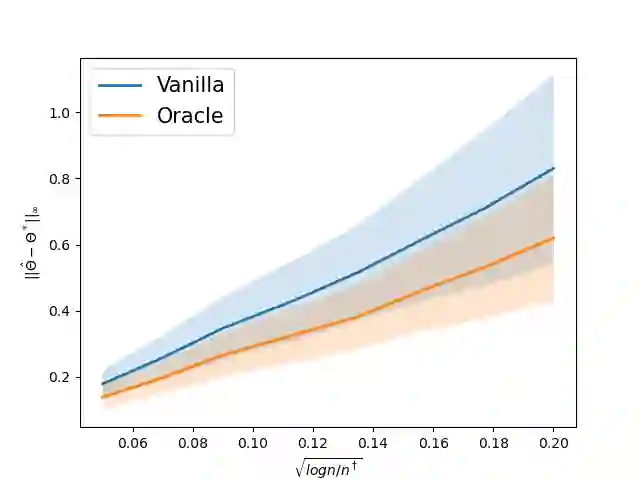
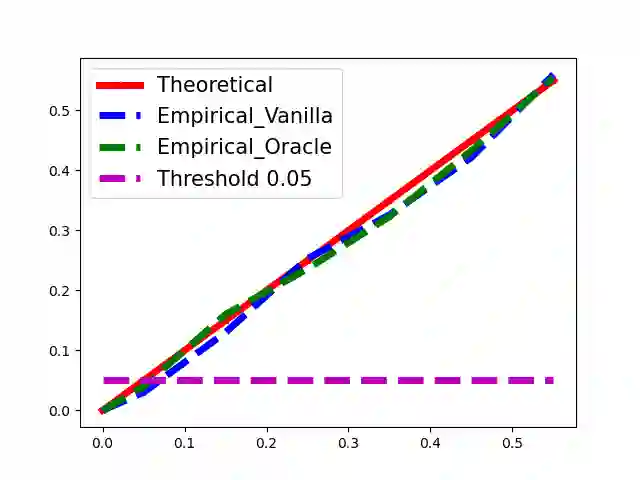
This paper studies the performance of the spectral method in the estimation and uncertainty quantification of the unobserved preference scores of compared entities in a very general and more realistic setup in which the comparison graph consists of hyper-edges of possible heterogeneous sizes and the number of comparisons can be as low as one for a given hyper-edge. Such a setting is pervasive in real applications, circumventing the need to specify the graph randomness and the restrictive homogeneous sampling assumption imposed in the commonly-used Bradley-Terry-Luce (BTL) or Plackett-Luce (PL) models. Furthermore, in the scenarios when the BTL or PL models are appropriate, we unravel the relationship between the spectral estimator and the Maximum Likelihood Estimator (MLE). We discover that a two-step spectral method, where we apply the optimal weighting estimated from the equal weighting vanilla spectral method, can achieve the same asymptotic efficiency as the MLE. Given the asymptotic distributions of the estimated preference scores, we also introduce a comprehensive framework to carry out both one-sample and two-sample ranking inferences, applicable to both fixed and random graph settings. It is noteworthy that it is the first time effective two-sample rank testing methods are proposed. Finally, we substantiate our findings via comprehensive numerical simulations and subsequently apply our developed methodologies to perform statistical inferences on statistics journals and movie rankings.
翻译:本文研究了谱方法在未观测偏好分数估计与不确定性量化中的性能,所采用的设定极为通用且更贴近实际:比较图由可能大小不一的超边构成,且给定超边的比较次数可低至一次。此类设定广泛存在于实际应用中,无需指定图的随机性,也无需施加布拉德利-特里-卢斯(BTL)或普莱克特-卢斯(PL)模型中常见的同质抽样假设。进一步地,在BTL或PL模型适用时,我们揭示了谱估计量与最大似然估计量(MLE)之间的关联。研究发现,两步谱方法——先用等权重朴素谱方法估计最优权重,再应用该权重——能够达到与MLE相同的渐近效率。基于估计偏好得分的渐近分布,我们还引入了一个综合框架,可执行单样本和双样本排序推断,适用于固定图和随机图设定。值得注意的是,这是首次提出有效的双样本排序检验方法。最后,我们通过大量数值模拟验证了理论发现,并将所开发的方法应用于统计学期刊排名和电影排名的统计推断。