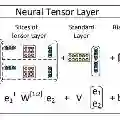
In this investigation, we delve into the automated detection of speculative language within biomedical articles by utilizing distributed sentence representations and advanced deep learning techniques. The implications of such identification extend to information retrieval, multi-document summarization, and the exploration of new knowledge. Our exploration encompasses two distinct approaches for acquiring distributed sentence representations: the Paragraph Vector model and the Recursive Neural Tensor Network. These methodologies are then rigorously compared against three foundational baseline algorithms: Support Vector Machines, Naive Bayes, and pattern matching. Our findings reveal that the Recursive Neural Tensor Network (RNTN) demonstrates a slight performance edge (F1 = 0.885) over the top-performing baseline, the linear bigram SVM (F1 = 0.881). Meanwhile, the Paragraph Vector model proves less effective (F1 = 0.368), even after extensive training using an expansive, unlabeled dataset. We engage in a comprehensive discourse on the factors influencing these performance disparities and provide insightful recommendations for future research directions.
翻译:本研究探讨了通过分布式句子表示和先进深度学习技术,自动检测生物医学文献中推测性语言的问题。此类识别对信息检索、多文档摘要及新知识探索具有重要价值。我们探索了两种获取分布式句子表示的不同方法:段落向量模型和循环神经张量网络。随后,将这些方法与三种基础基线算法(支持向量机、朴素贝叶斯和模式匹配)进行了严格比较。研究结果表明,循环神经张量网络(RNTN)的表现(F1=0.885)略优于表现最佳的基线算法——线性二元组支持向量机(F1=0.881)。而段落向量模型即使在使用大规模未标注数据集进行广泛训练后,效果仍较差(F1=0.368)。我们全面讨论了影响这些性能差异的因素,并为未来研究方向提供了建设性建议。