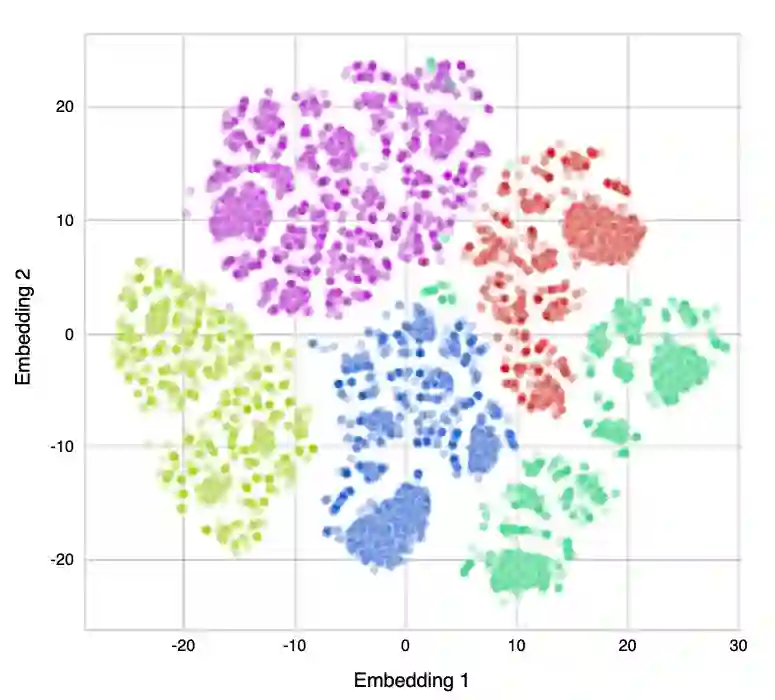
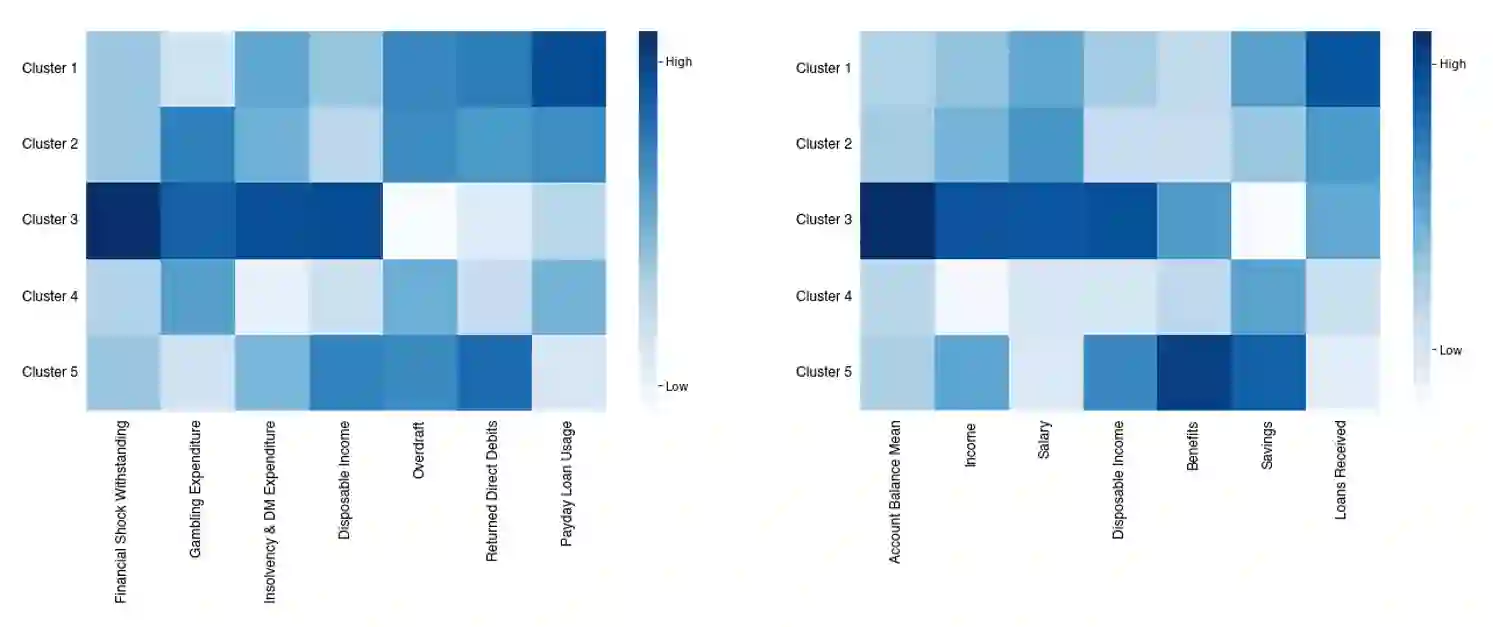
This research article analyses and demonstrates the hidden implications for fairness of seemingly neutral data coupled with powerful technology, such as machine learning (ML), using Open Banking as an example. Open Banking has ignited a revolution in financial services, opening new opportunities for customer acquisition, management, retention, and risk assessment. However, the granularity of transaction data holds potential for harm where unnoticed proxies for sensitive and prohibited characteristics may lead to indirect discrimination. Against this backdrop, we investigate the dimensions of financial vulnerability (FV), a global concern resulting from COVID-19 and rising inflation. Specifically, we look to understand the behavioral elements leading up to FV and its impact on at-risk, disadvantaged groups through the lens of fair interpretation. Using a unique dataset from a UK FinTech lender, we demonstrate the power of fine-grained transaction data while simultaneously cautioning its safe usage. Three ML classifiers are compared in predicting the likelihood of FV, and groups exhibiting different magnitudes and forms of FV are identified via clustering to highlight the effects of feature combination. Our results indicate that engineered features of financial behavior can be predictive of omitted personal information, particularly sensitive or protected characteristics, shedding light on the hidden dangers of Open Banking data. We discuss the implications and conclude fairness via unawareness is ineffective in this new technological environment.
翻译:本研究以开放银行为例,分析并论证了看似中性的数据与机器学习等强大技术相结合时对公平性产生的隐性影响。开放银行引发了金融服务领域的革命,为获客、客户管理、客户留存及风险评估开辟了新机遇。然而,交易数据的精细粒度也潜藏风险——被忽视的敏感及受保护特征代理变量可能导致间接歧视。在此背景下,我们探究了财务脆弱性(COVID-19与通胀上升引发的全球性议题)的维度。具体而言,我们旨在通过公平性解释的视角,理解导致财务脆弱性的行为要素及其对高风险弱势群体的影响。基于英国一家金融科技贷款机构的独特数据集,我们既展示了精细交易数据的强大效能,也警示了其安全使用的重要性。通过对比三种机器学习分类器预测财务脆弱性可能性的表现,并利用聚类分析识别具有不同财务脆弱性程度与形态的群体,揭示了特征组合的影响效应。研究结果表明,经工程化处理的财务行为特征可预测被省略的个人信息(尤其是敏感或受保护特征),揭示了开放银行数据的隐性风险。我们讨论了相关影响,并得出结论:在新技术环境下,基于“无意识即公平”的策略已失效。