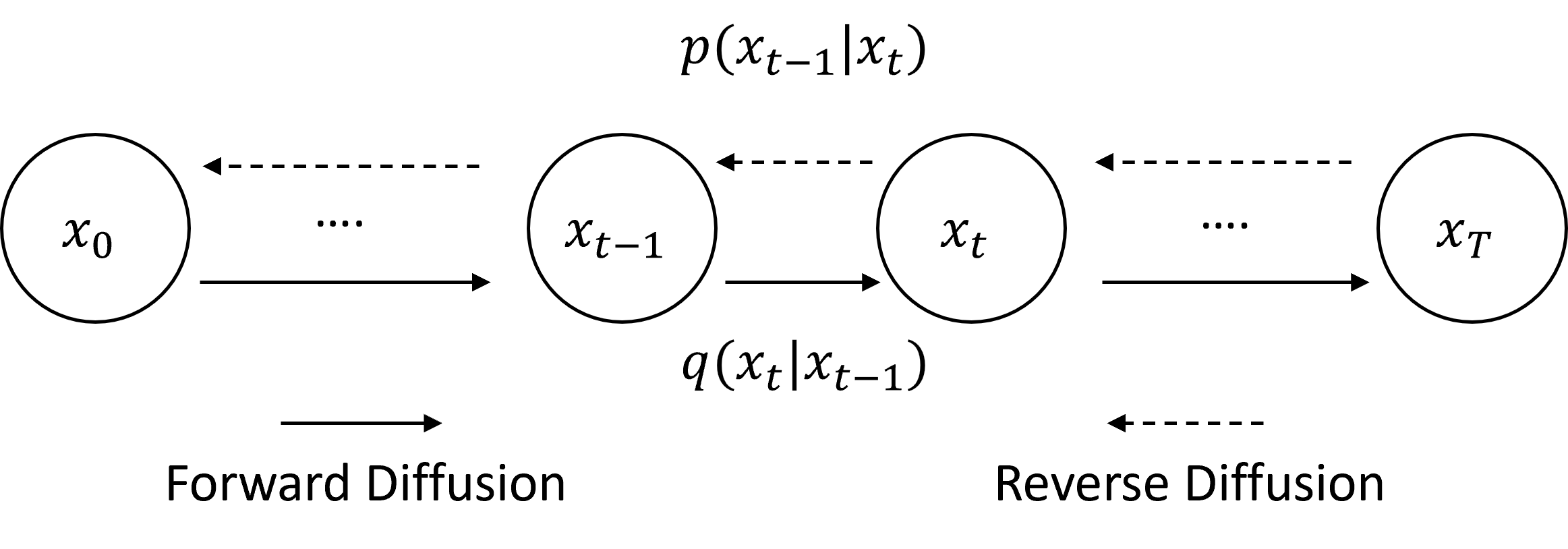
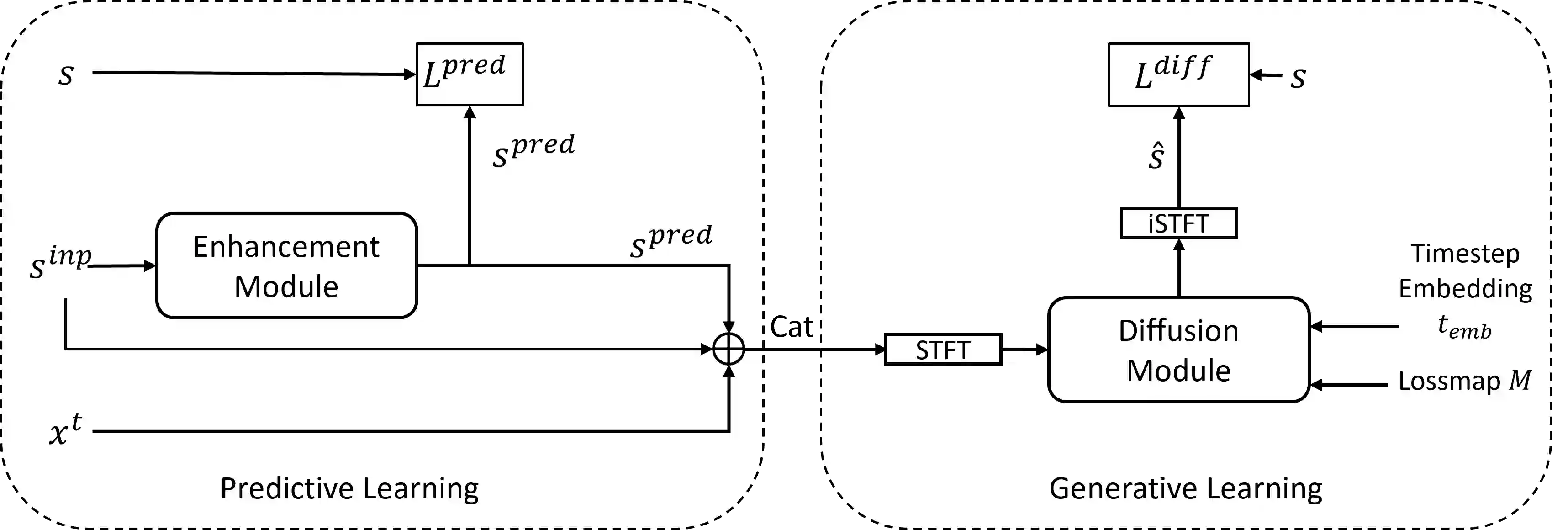
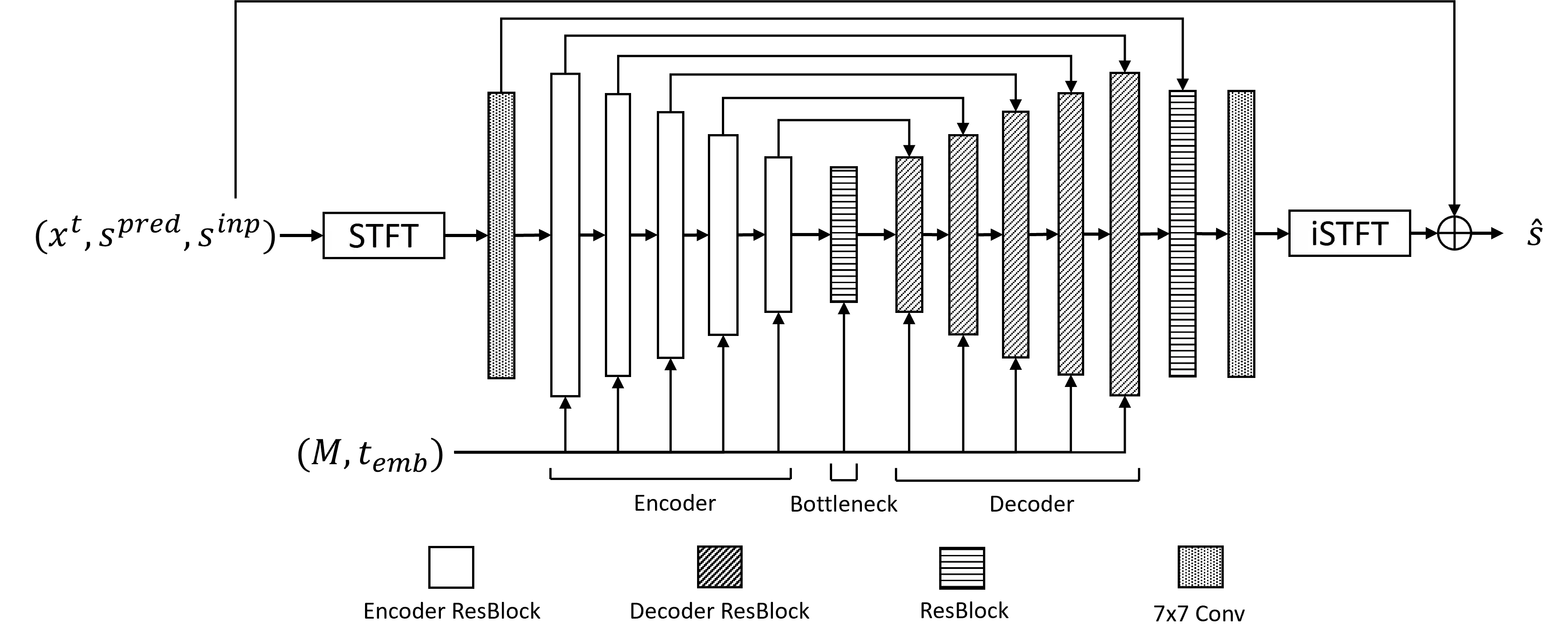
Speech super-resolution (SR) is the task that restores high-resolution speech from low-resolution input. Existing models employ simulated data and constrained experimental settings, which limit generalization to real-world SR. Predictive models are known to perform well in fixed experimental settings, but can introduce artifacts in adverse conditions. On the other hand, generative models learn the distribution of target data and have a better capacity to perform well on unseen conditions. In this study, we propose a novel two-stage approach that combines the strengths of predictive and generative models. Specifically, we employ a diffusion-based model that is conditioned on the output of a predictive model. Our experiments demonstrate that the model significantly outperforms single-stage counterparts and existing strong baselines on benchmark SR datasets. Furthermore, we introduce a repainting technique during the inference of the diffusion process, enabling the proposed model to regenerate high-frequency components even in mismatched conditions. An additional contribution is the collection of and evaluation on real SR recordings, using the same microphone at different native sampling rates. We make this dataset freely accessible, to accelerate progress towards real-world speech super-resolution.
翻译:语音超分辨率(SR)是指从低分辨率输入中恢复高分辨率语音的任务。现有模型采用模拟数据及受限的实验设置,这限制了其在真实场景SR中的泛化能力。预测模型在固定实验设置下表现出色,但在不利条件下可能引入伪影。另一方面,生成模型学习目标数据的分布,并具备在未见条件下良好表现的更强能力。本研究提出一种新颖的两阶段方法,融合了预测模型与生成模型的优势。具体而言,我们采用基于扩散的模型,并以预测模型的输出作为条件。实验表明,该模型在基准SR数据集上显著优于单阶段模型及现有强基线方法。此外,我们在扩散过程推理阶段引入重绘技术,使所提模型即使在条件不匹配的情况下也能重建高频成分。另一贡献是使用同一麦克风以不同原生采样率采集真实SR录音并进行评估。我们免费开放该数据集,以推动真实场景语音超分辨率的研究进展。