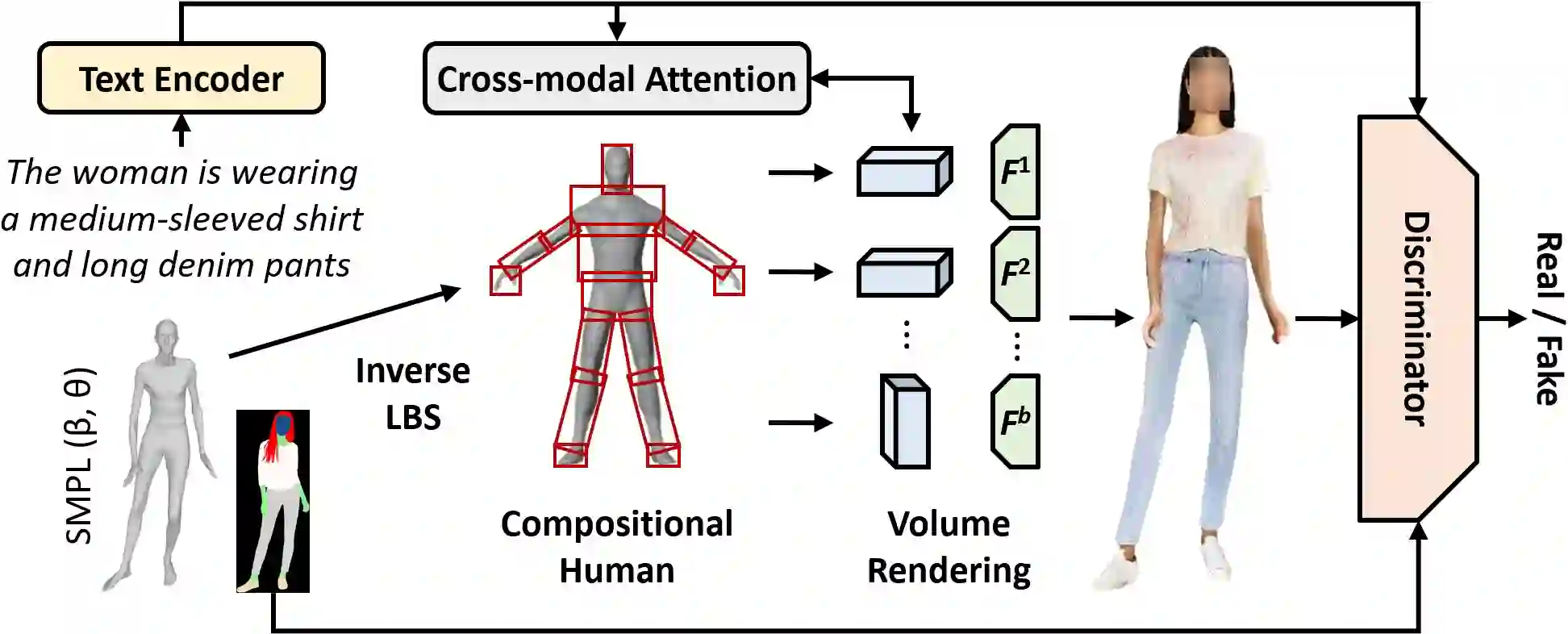
3D human modeling has been widely used for engaging interaction in gaming, film, and animation. The customization of these characters is crucial for creativity and scalability, which highlights the importance of controllability. In this work, we introduce Text-guided 3D Human Generation (\texttt{T3H}), where a model is to generate a 3D human, guided by the fashion description. There are two goals: 1) the 3D human should render articulately, and 2) its outfit is controlled by the given text. To address this \texttt{T3H} task, we propose Compositional Cross-modal Human (CCH). CCH adopts cross-modal attention to fuse compositional human rendering with the extracted fashion semantics. Each human body part perceives relevant textual guidance as its visual patterns. We incorporate the human prior and semantic discrimination to enhance 3D geometry transformation and fine-grained consistency, enabling it to learn from 2D collections for data efficiency. We conduct evaluations on DeepFashion and SHHQ with diverse fashion attributes covering the shape, fabric, and color of upper and lower clothing. Extensive experiments demonstrate that CCH achieves superior results for \texttt{T3H} with high efficiency.
翻译:三维人体建模已广泛应用于游戏、电影和动画中的交互体验。角色定制化对于提升创造力和可扩展性至关重要,这凸显了可控性的重要性。本文提出文本引导的三维人体生成(T3H)任务,旨在根据服装描述生成三维人体,其目标有二:1)生成的三维人体应能实现关节化渲染;2)其着装需受给定文本控制。针对T3H任务,我们提出组合式跨模态人体生成模型(CCH)。CCH采用跨模态注意力机制,将组合式人体渲染与提取的服装语义特征相融合,使各人体部位能感知对应文本引导的视觉模式。我们引入人体先验与语义判别机制,以增强三维几何变换与细粒度一致性,从而仅通过二维数据集训练即可实现高效学习。在DeepFashion和SHHQ数据集上,我们针对涵盖上下装形状、面料、颜色的多样化服装属性进行评估。大量实验表明,CCH能以高效方式在T3H任务中取得优异表现。