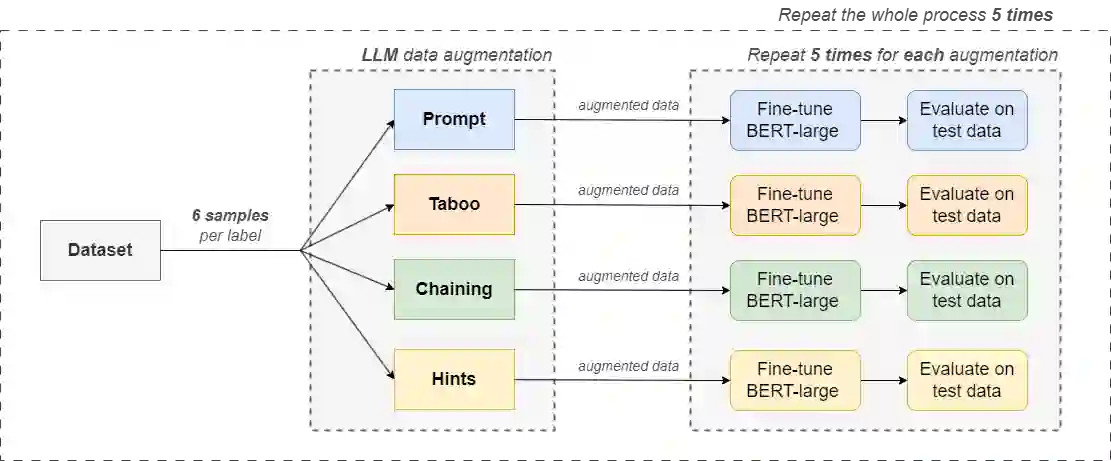
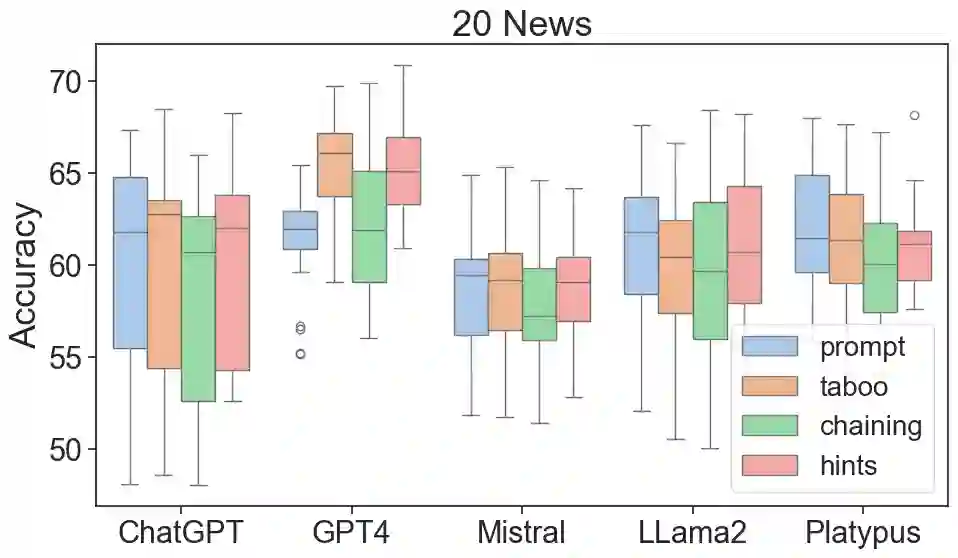
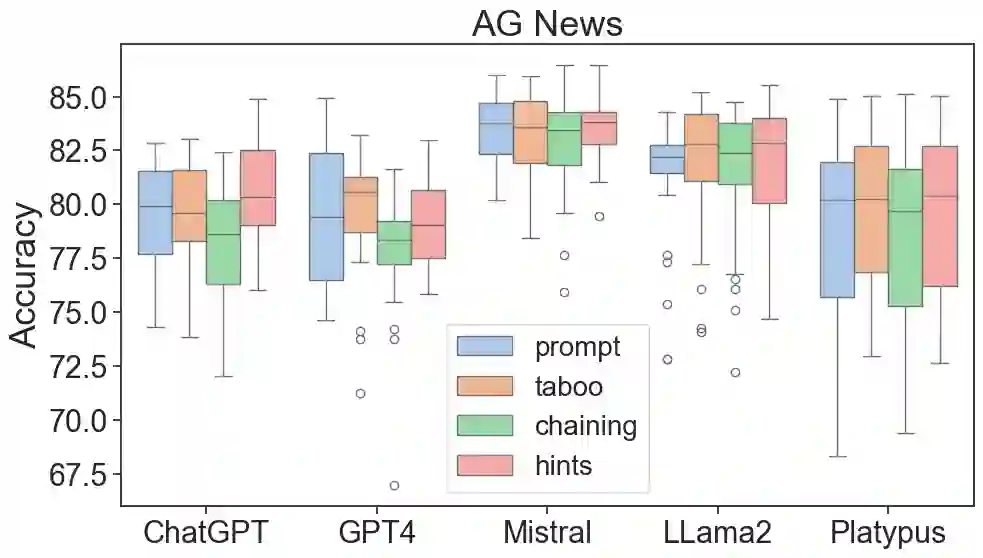
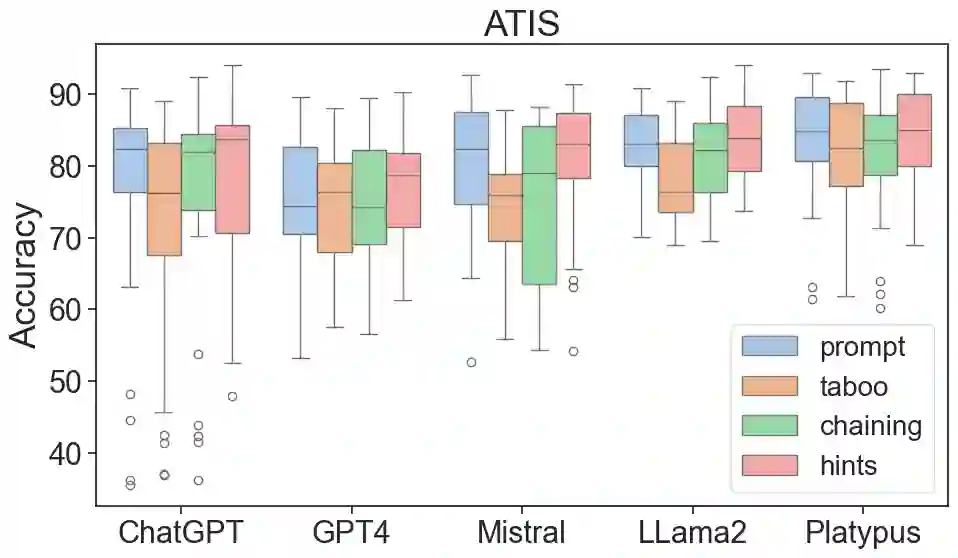
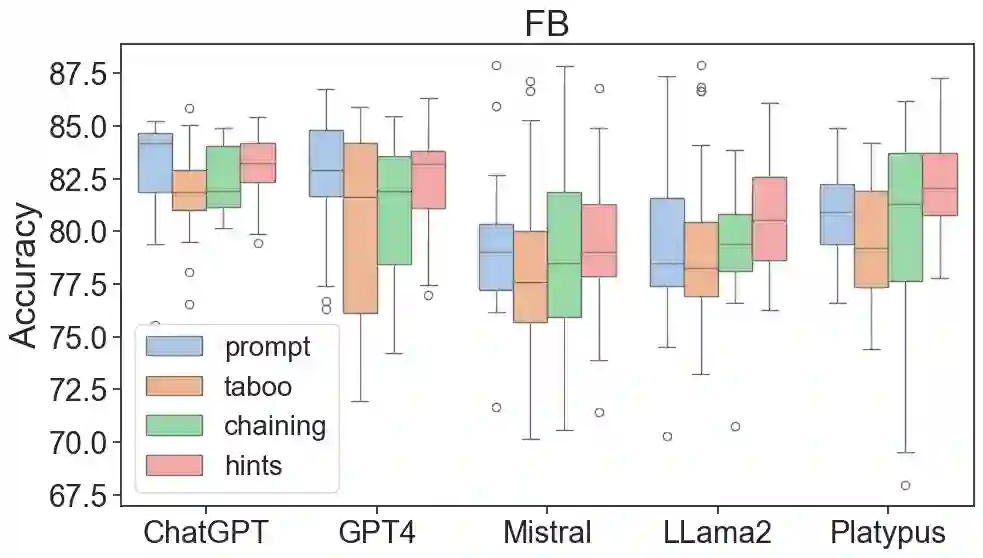
The latest generative large language models (LLMs) have found their application in data augmentation tasks, where small numbers of text samples are LLM-paraphrased and then used to fine-tune the model. However, more research is needed to assess how different prompts, seed data selection strategies, filtering methods, or model settings affect the quality of paraphrased data (and downstream models). In this study, we investigate three text diversity incentive methods well established in crowdsourcing: taboo words, hints by previous outlier solutions, and chaining on previous outlier solutions. Using these incentive methods as part of instructions to LLMs augmenting text datasets, we measure their effects on generated texts' lexical diversity and downstream model performance. We compare the effects over 5 different LLMs and 6 datasets. We show that diversity is most increased by taboo words, while downstream model performance is highest when previously created paraphrases are used as hints.
翻译:最新生成式大语言模型(LLMs)已被应用于数据增强任务,即通过对少量文本样本进行LLM重述,再用于微调模型。然而,目前尚需更多研究评估不同提示词、种子数据选择策略、过滤方法或模型设置对重述数据(及下游模型)质量的影响。本研究探讨了众包领域三种成熟的文本多样性激励方法:禁用词、基于先前异常解法的提示,以及基于先前异常解法的链式生成。通过将这些激励方法融入LLM文本增强的指令中,我们测量了它们对生成文本词汇多样性及下游模型性能的影响。我们基于5种不同LLM和6个数据集进行了效果对比。结果表明,禁用词对多样性的提升最为显著,而将先前生成的重述作为提示时,下游模型性能达到最高。