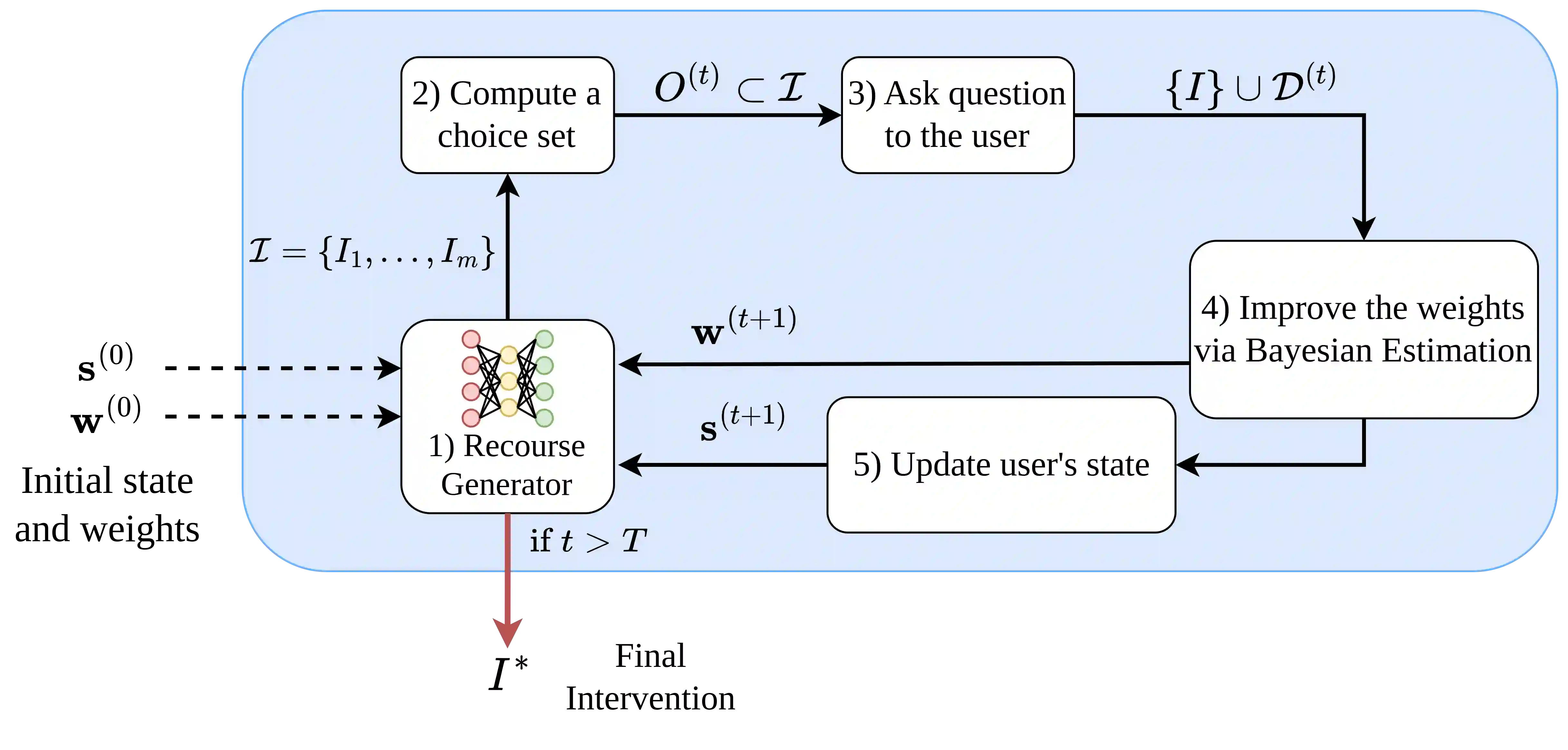
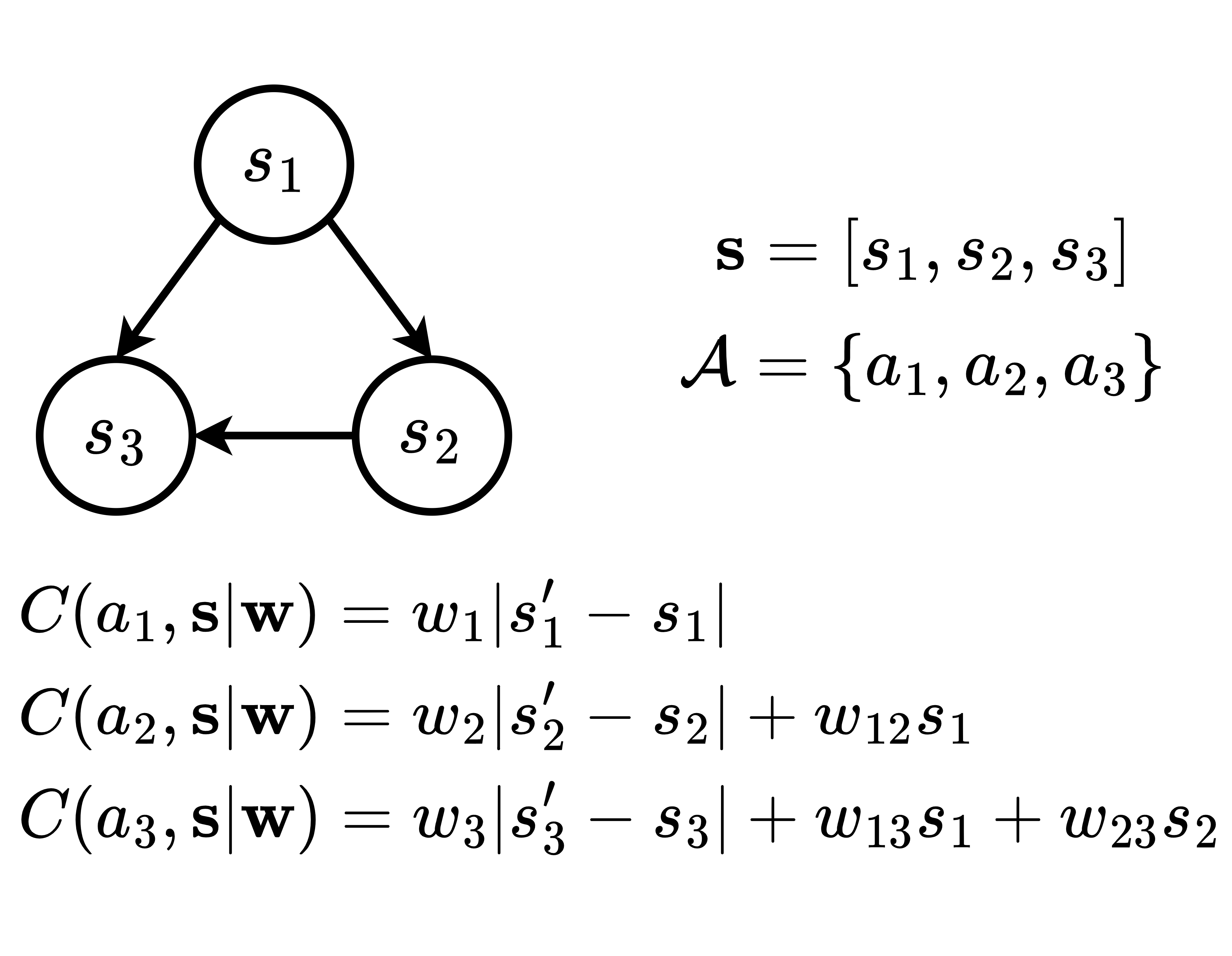
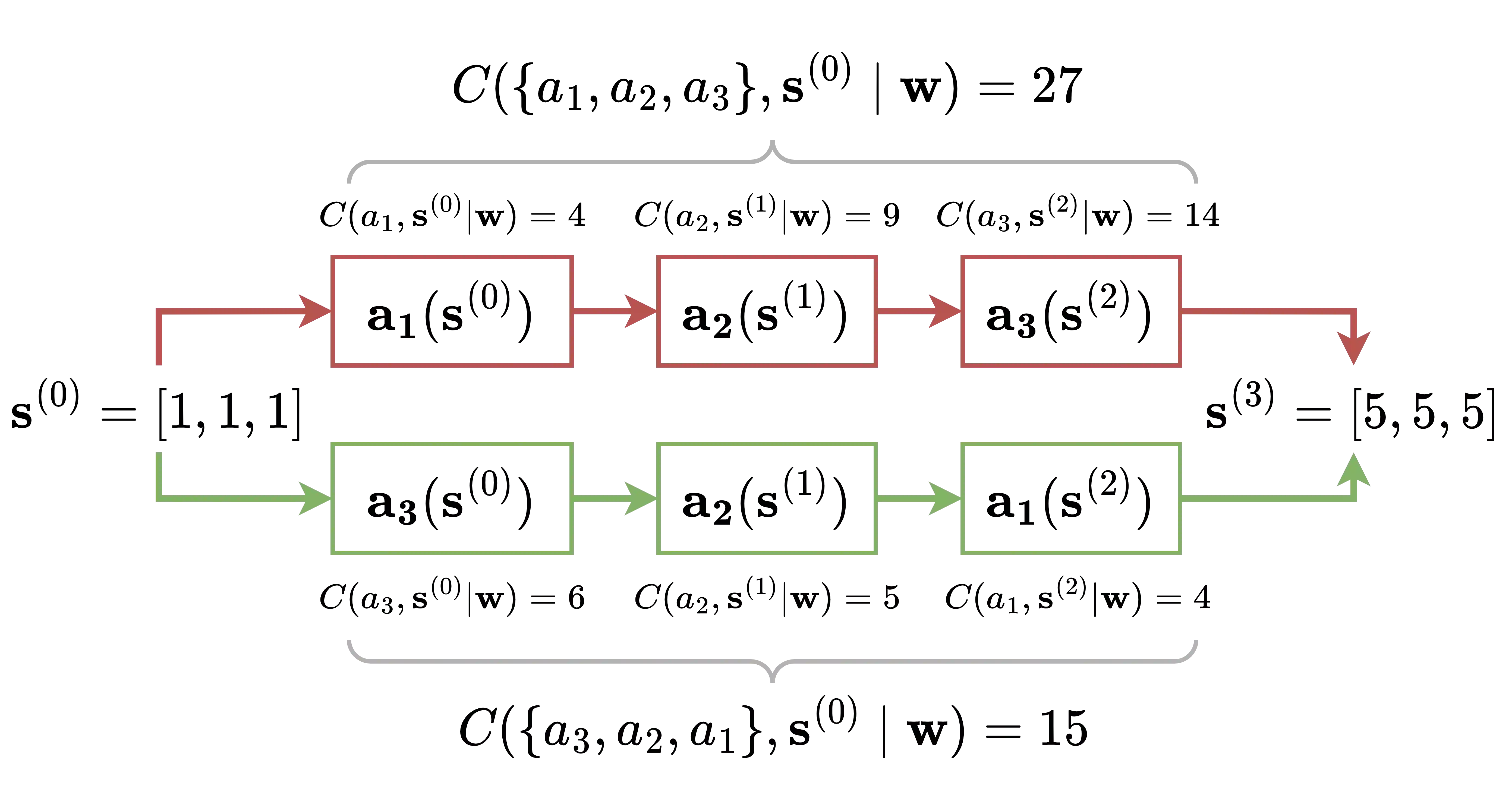
Algorithmic Recourse (AR) is the problem of computing a sequence of actions that -- once performed by a user -- overturns an undesirable machine decision. It is paramount that the sequence of actions does not require too much effort for users to implement. Yet, most approaches to AR assume that actions cost the same for all users, and thus may recommend unfairly expensive recourse plans to certain users. Prompted by this observation, we introduce PEAR, the first human-in-the-loop approach capable of providing personalized algorithmic recourse tailored to the needs of any end-user. PEAR builds on insights from Bayesian Preference Elicitation to iteratively refine an estimate of the costs of actions by asking choice set queries to the target user. The queries themselves are computed by maximizing the Expected Utility of Selection, a principled measure of information gain accounting for uncertainty on both the cost estimate and the user's responses. PEAR integrates elicitation into a Reinforcement Learning agent coupled with Monte Carlo Tree Search to quickly identify promising recourse plans. Our empirical evaluation on real-world datasets highlights how PEAR produces high-quality personalized recourse in only a handful of iterations.
翻译:算法追索(AR)问题旨在计算一系列动作序列,用户执行该序列后可逆转不良的机器决策。确保动作序列对用户实施所需努力最小化至关重要。然而,现有AR方法大多假设所有用户的动作成本相同,可能导致某些用户被推荐不合理的昂贵的追索方案。基于这一观察,我们提出PEAR——首个能够根据终端用户需求提供个性化算法追索的人机协作方法。PEAR借鉴贝叶斯偏好诱导的思想,通过向目标用户提出选择集查询,迭代优化对动作成本的估计。这些查询通过最大化选择期望效用(一种考虑成本估计与用户响应不确定性的信息增益原则性度量)生成。PEAR将偏好诱导集成到强化学习智能体中,结合蒙特卡洛树搜索快速识别有前景的追索方案。在真实数据集上的实证评估表明,PEAR仅需少量迭代即可生成高质量的个性化追索。