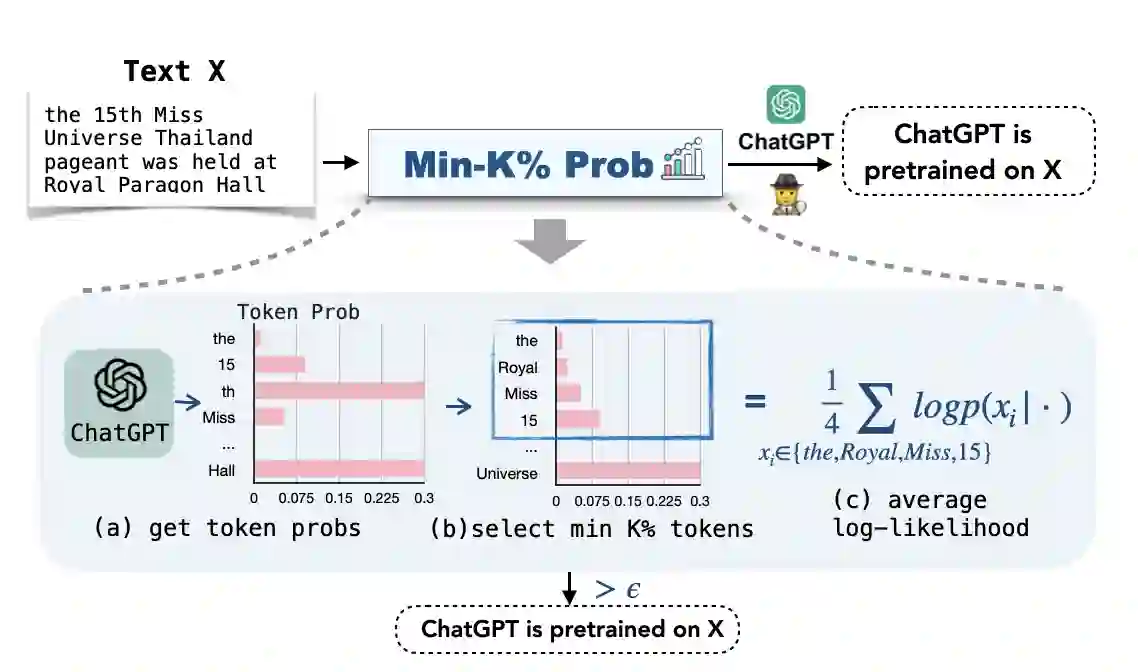
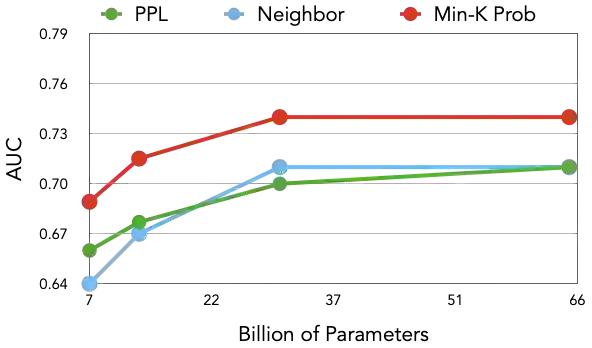
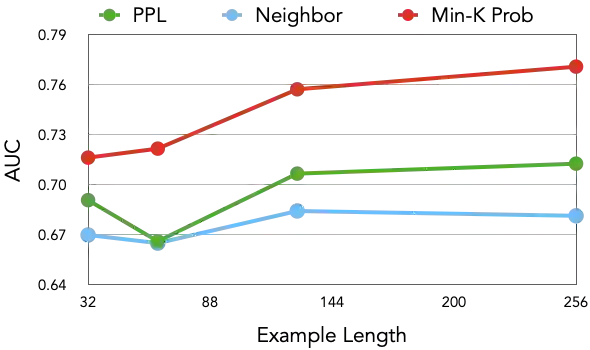
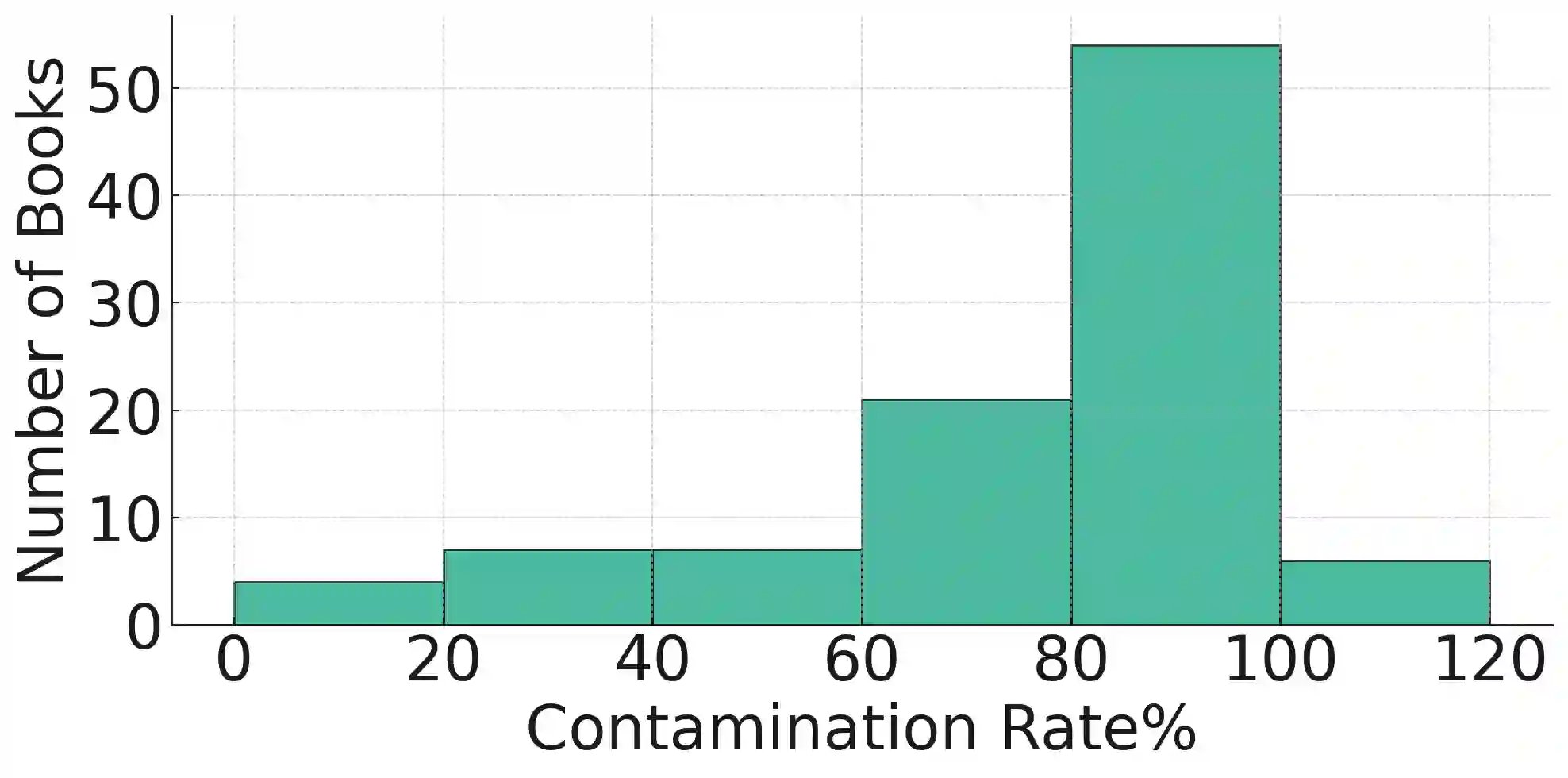
Although large language models (LLMs) are widely deployed, the data used to train them is rarely disclosed. Given the incredible scale of this data, up to trillions of tokens, it is all but certain that it includes potentially problematic text such as copyrighted materials, personally identifiable information, and test data for widely reported reference benchmarks. However, we currently have no way to know which data of these types is included or in what proportions. In this paper, we study the pretraining data detection problem: given a piece of text and black-box access to an LLM without knowing the pretraining data, can we determine if the model was trained on the provided text? To facilitate this study, we introduce a dynamic benchmark WIKIMIA that uses data created before and after model training to support gold truth detection. We also introduce a new detection method Min-K% Prob based on a simple hypothesis: an unseen example is likely to contain a few outlier words with low probabilities under the LLM, while a seen example is less likely to have words with such low probabilities. Min-K% Prob can be applied without any knowledge about the pretraining corpus or any additional training, departing from previous detection methods that require training a reference model on data that is similar to the pretraining data. Moreover, our experiments demonstrate that Min-K% Prob achieves a 7.4% improvement on WIKIMIA over these previous methods. We apply Min-K% Prob to two real-world scenarios, copyrighted book detection, and contaminated downstream example detection, and find it a consistently effective solution.
翻译:尽管大型语言模型(LLM)已广泛部署,但其训练所使用的数据却鲜少公开。考虑到这些数据规模之庞大(可达数万亿词元),几乎可以确定其中包含有问题的文本,例如受版权保护的材料、个人身份信息以及广泛报道的参考基准测试数据。然而,目前我们无法得知这些数据类型具体包含哪些内容或占比多少。本文研究预训练数据检测问题:在未知预训练数据的情况下,给定一段文本并仅能黑盒访问LLM,能否判断该模型是否在给定文本上训练过?为便于研究,我们引入动态基准WIKIMIA,利用模型训练前后创建的数据支持真实标注检测。同时提出新检测方法Min-K% Prob,其基于简单假设:未见过样本中可能包含几个在LLM下概率极低的异常词,而见过样本中这类低概率词出现可能性较小。Min-K% Prob无需预训练语料库知识或额外训练即可应用,这与先前需在类似预训练数据上训练参考模型的检测方法不同。此外,实验表明,Min-K% Prob在WIKIMIA上相较先前方法提升7.4%的检测性能。我们将Min-K% Prob应用于受版权书籍检测和受污染下游示例检测两个真实场景,发现其始终是有效的解决方案。