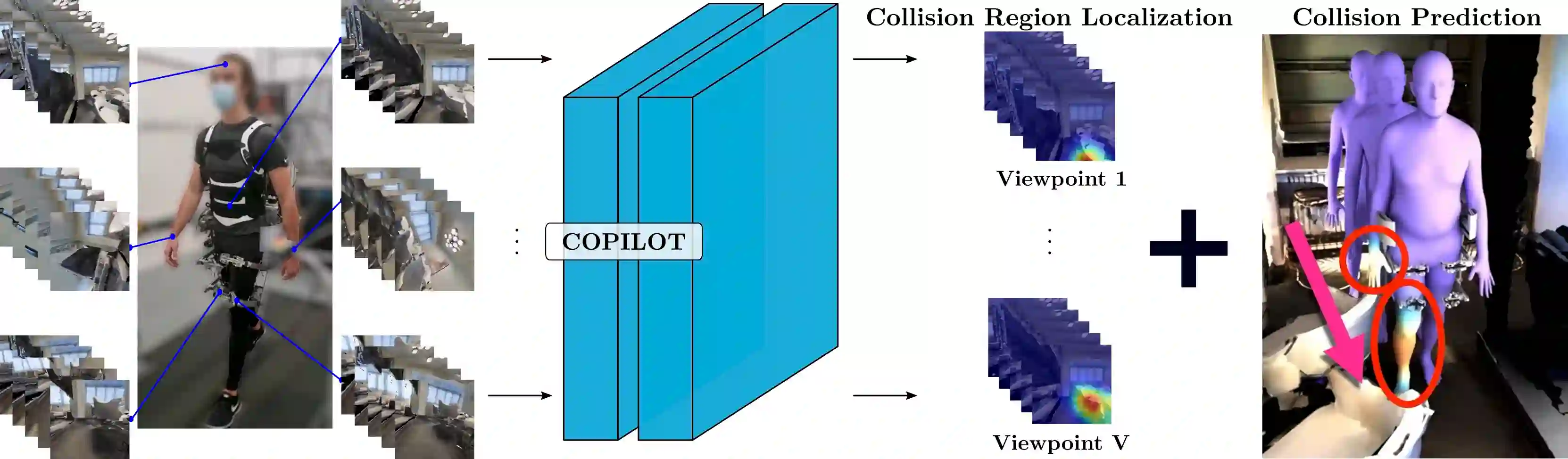
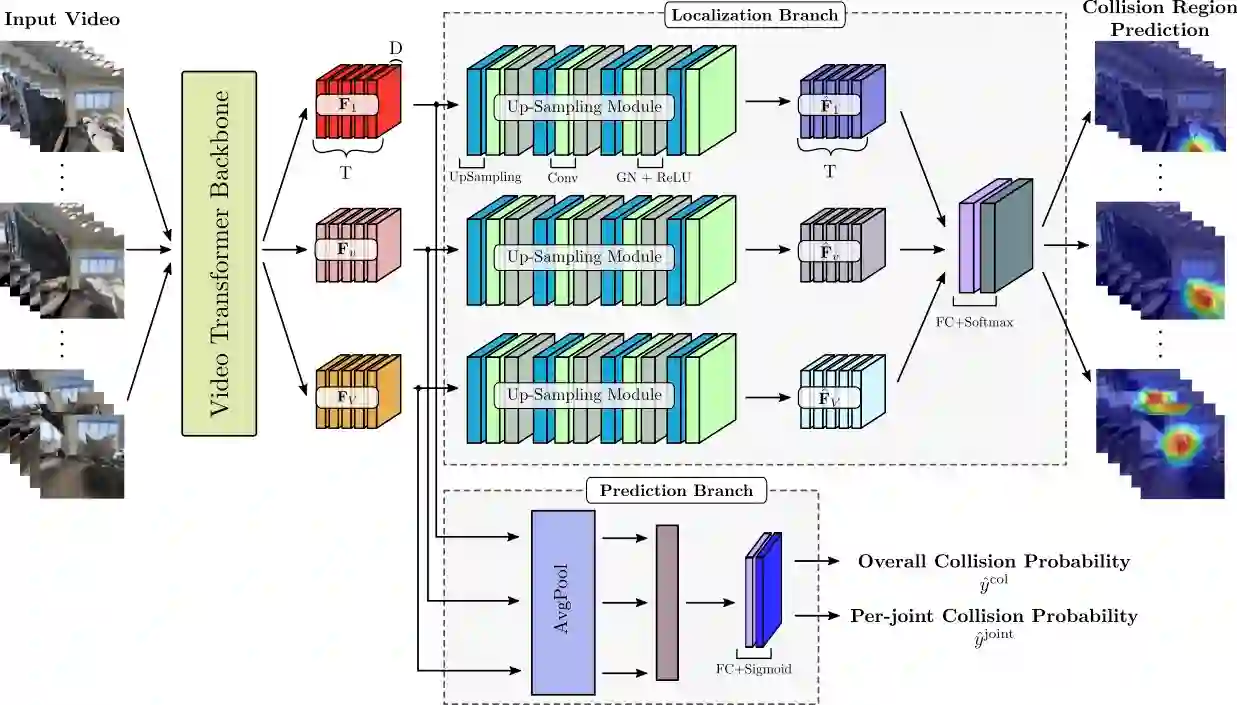
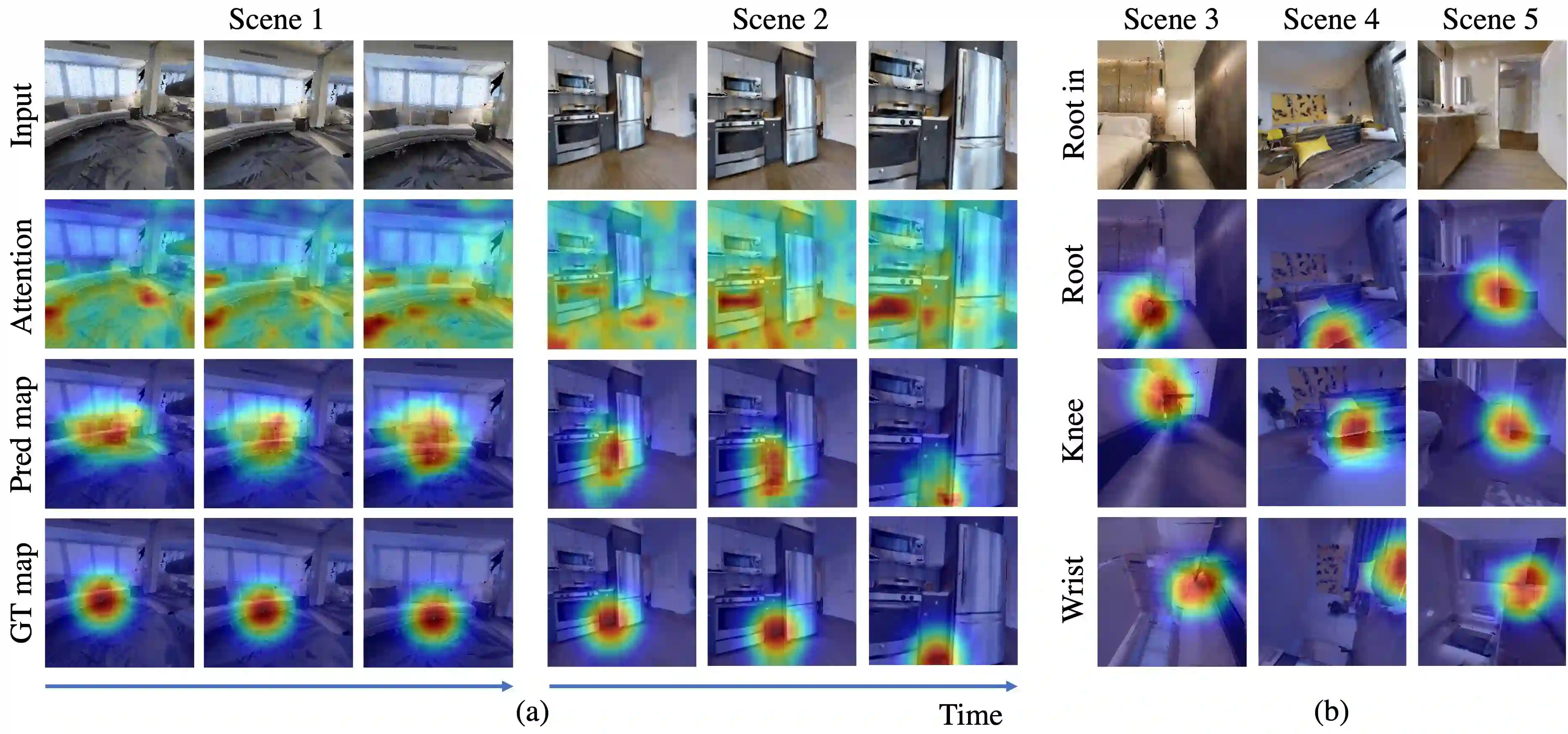
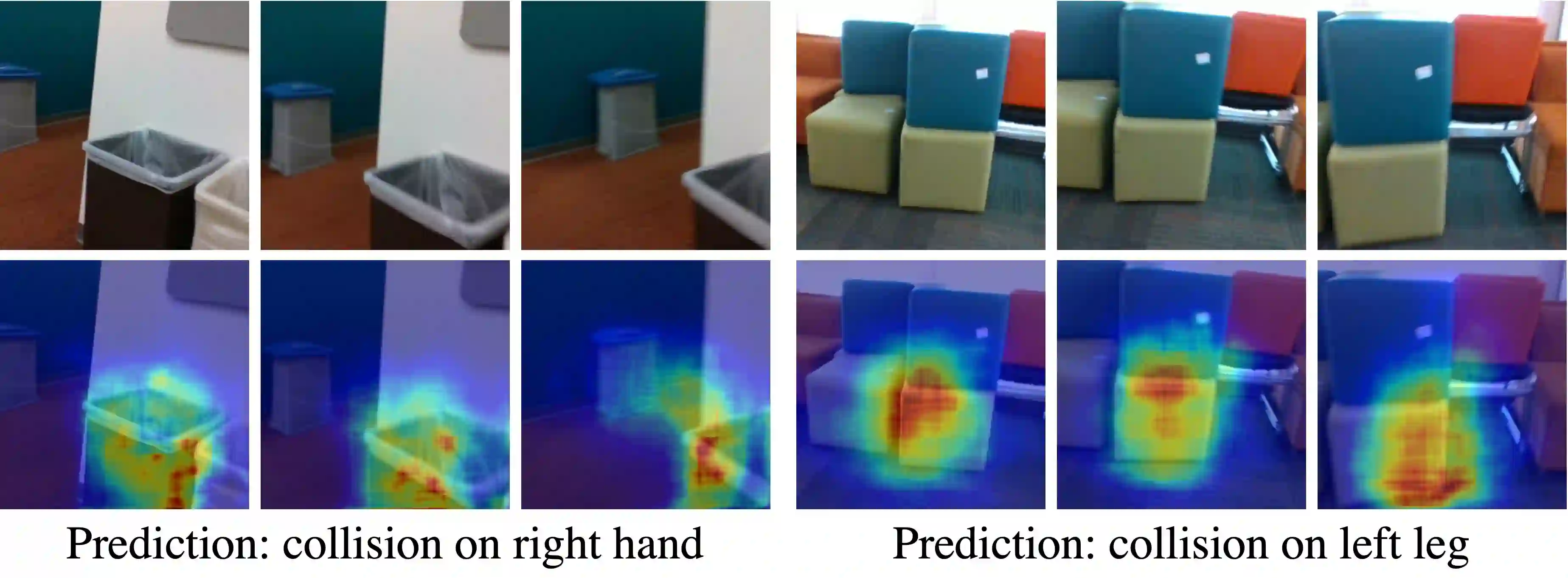
To produce safe human motions, assistive wearable exoskeletons must be equipped with a perception system that enables anticipating potential collisions from egocentric observations. However, previous approaches to exoskeleton perception greatly simplify the problem to specific types of environments, limiting their scalability. In this paper, we propose the challenging and novel problem of predicting human-scene collisions for diverse environments from multi-view egocentric RGB videos captured from an exoskeleton. By classifying which body joints will collide with the environment and predicting a collision region heatmap that localizes potential collisions in the environment, we aim to develop an exoskeleton perception system that generalizes to complex real-world scenes and provides actionable outputs for downstream control. We propose COPILOT, a video transformer-based model that performs both collision prediction and localization simultaneously, leveraging multi-view video inputs via a proposed joint space-time-viewpoint attention operation. To train and evaluate the model, we build a synthetic data generation framework to simulate virtual humans moving in photo-realistic 3D environments. This framework is then used to establish a dataset consisting of 8.6M egocentric RGBD frames to enable future work on the problem. Extensive experiments suggest that our model achieves promising performance and generalizes to unseen scenes as well as real world. We apply COPILOT to a downstream collision avoidance task, and successfully reduce collision cases by 29% on unseen scenes using a simple closed-loop control algorithm.
翻译:为了产生安全的人类运动,辅助性磨损式外骨质素必须配备一个感知系统,以便预测自取中心观测的潜在碰撞。然而,以前对Exskeleton的感知将问题简化到特定类型的环境,限制其可缩放性。在本文中,我们提出一个具有挑战性和新颖的问题,即从从从外骨骼中捕获的多视角自我中心 RGB 视频中预测不同环境中的人类-皮肤碰撞。通过对哪个机构联结将与环境相碰撞,并预测一个碰撞区域热映图,将环境上的潜在碰撞本地化。我们的目标是开发一个外骨骼感知系统,将问题简单化到复杂的现实世界场景,为下游控制提供可操作的输出。我们提出一个基于视频变异模型,即同时进行碰撞预测和本地化,通过拟议的空间-时间模型关注操作来利用多视图视频输入。为了训练和评价模型,我们建立了一个合成数据生成框架,以模拟在光-现实-现实的三维同步环境中移动的虚拟人类。我们打算开发一个有希望的内心-核心任务框架,然后用来建立一个能成功实现数据,从而实现一个具有前景-核心-核心-核心-核心-核心-核心-核心-核心-框架。