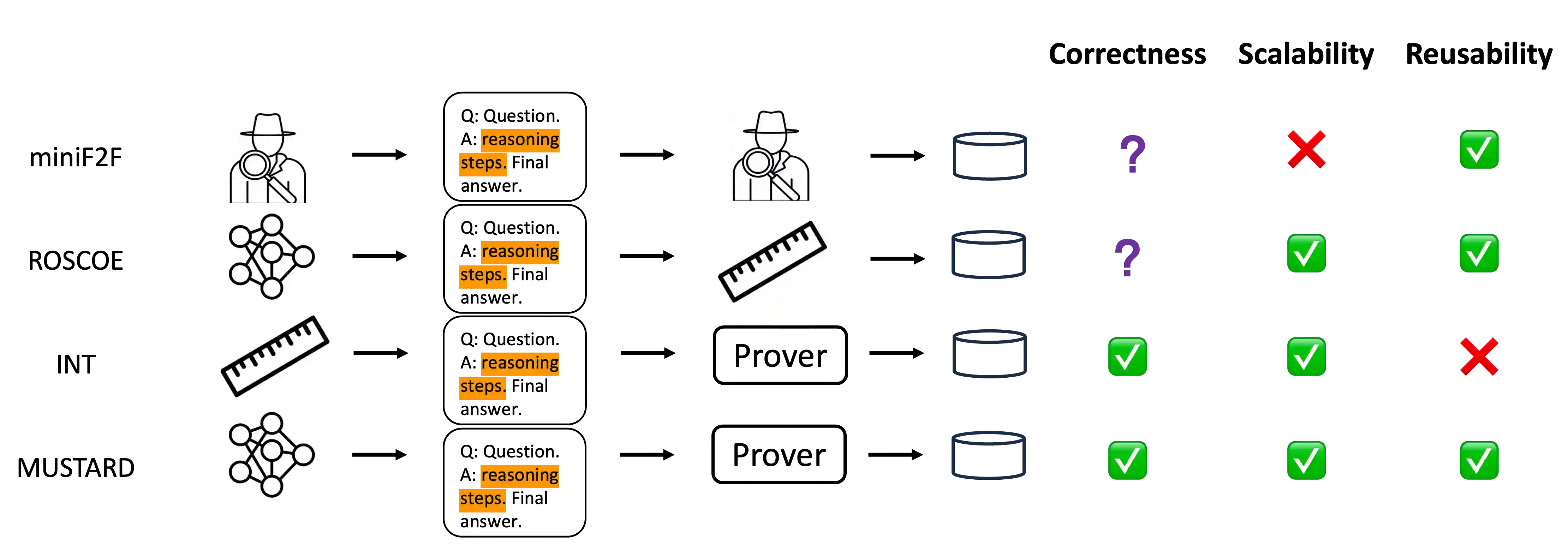
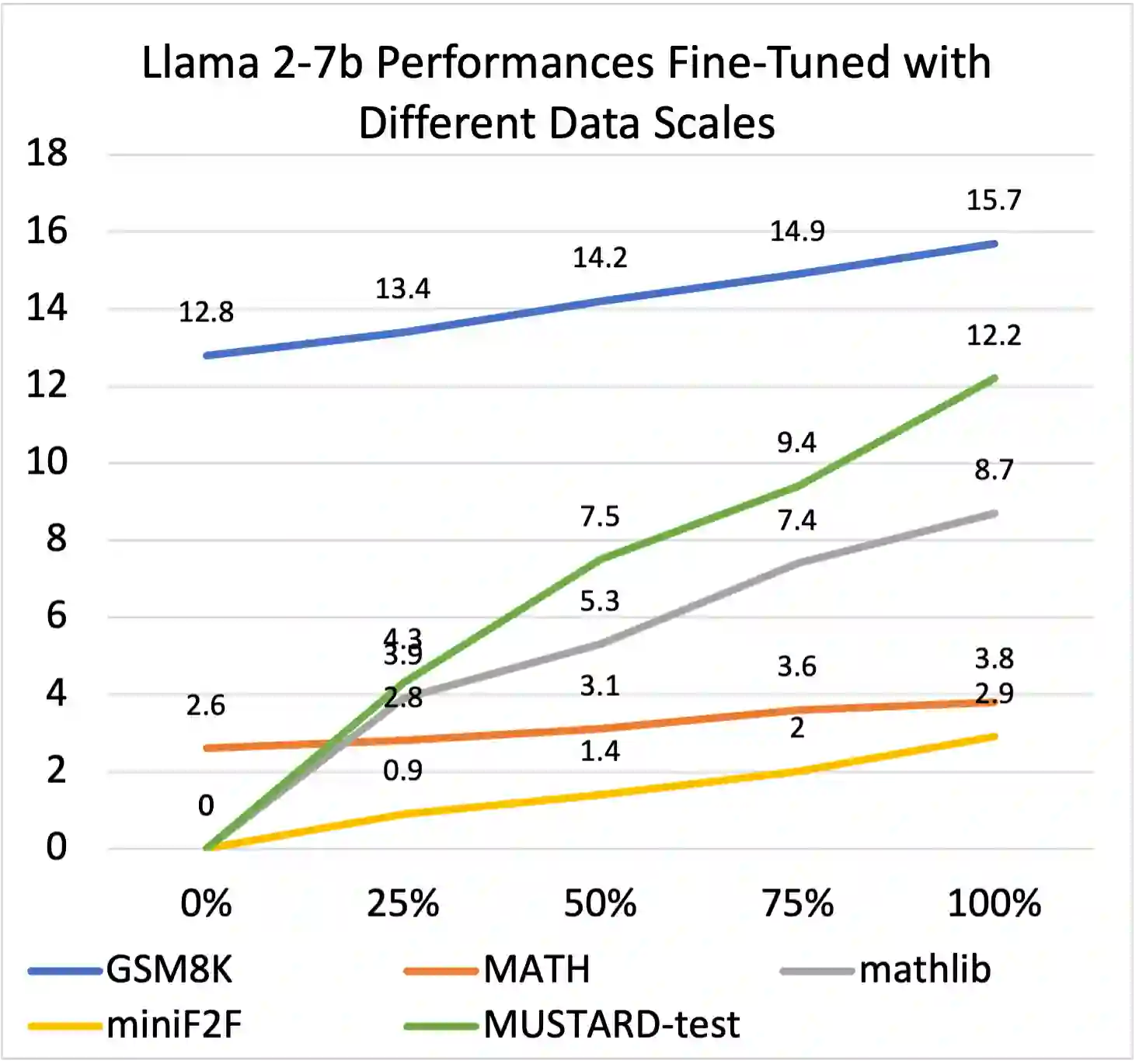
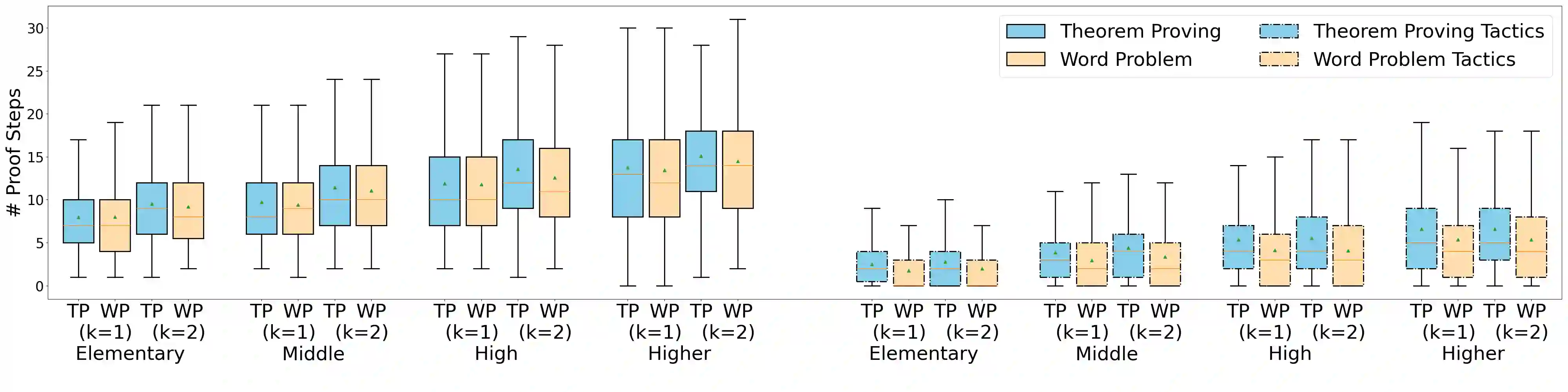
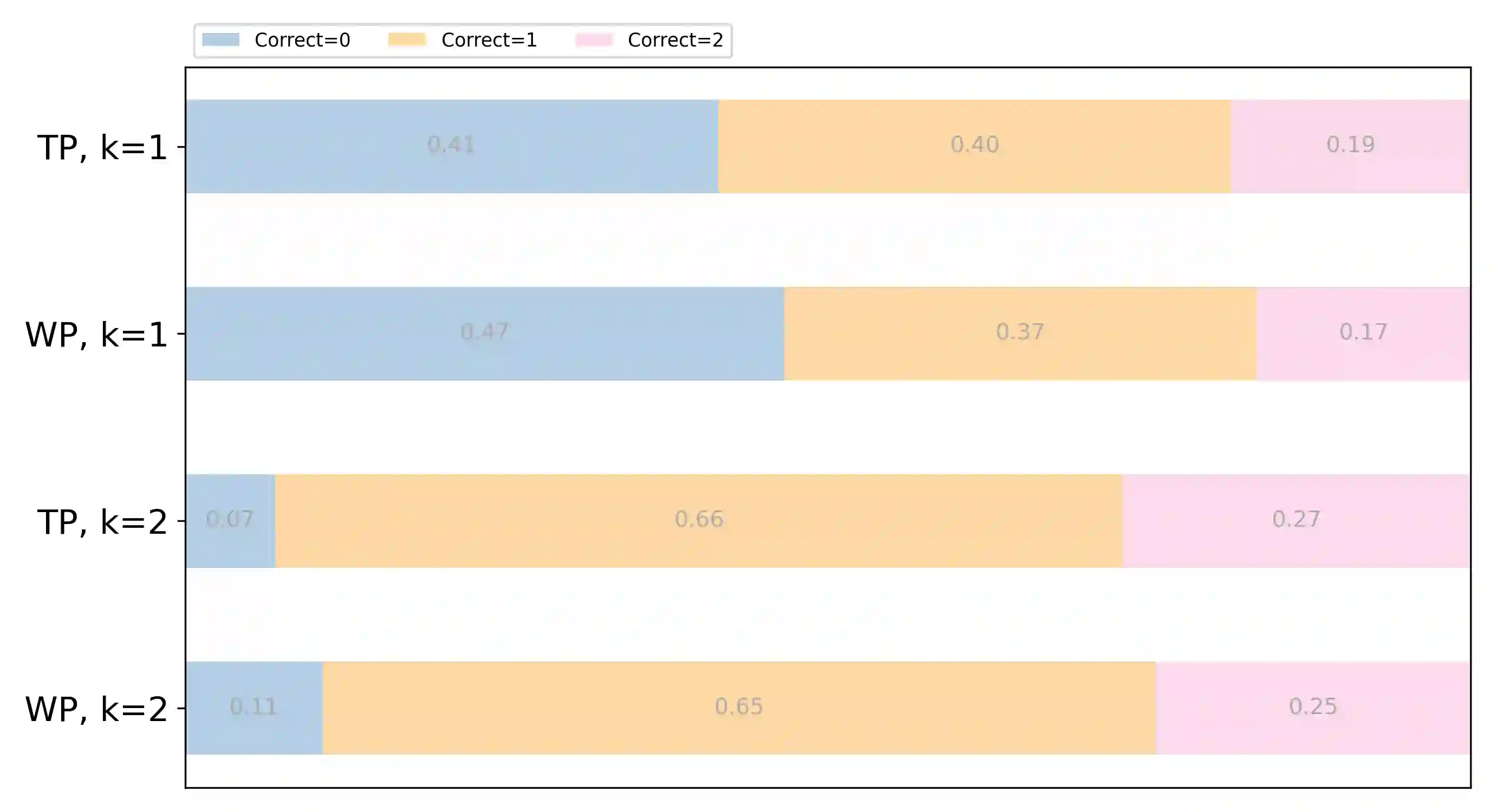
Recent large language models (LLMs) have witnessed significant advancement in various tasks, including mathematical reasoning and theorem proving. As these two tasks require strict and formal multi-step inference, they are appealing domains for exploring the reasoning ability of LLMs but still face important challenges. Previous studies such as Chain-of-Thought (CoT) have revealed the effectiveness of intermediate steps guidance. However, such step-wise annotation requires heavy labor, leading to insufficient training steps for current benchmarks. To fill this gap, this work introduces MUSTARD, a data generation framework that masters uniform synthesis of theorem and proof data of high quality and diversity. MUSTARD synthesizes data in three stages: (1) It samples a few mathematical concept seeds as the problem category. (2) Then, it prompts a generative language model with the sampled concepts to obtain both the problems and their step-wise formal solutions. (3) Lastly, the framework utilizes a proof assistant (e.g., Lean Prover) to filter the valid proofs. With the proposed MUSTARD, we present a theorem-and-proof benchmark MUSTARDSAUCE with 5,866 valid data points. Each data point contains an informal statement, an informal proof, and a translated formal proof that passes the prover validation. We perform extensive analysis and demonstrate that MUSTARD generates validated high-quality step-by-step data. We further apply the MUSTARDSAUCE for fine-tuning smaller language models. The fine-tuned Llama 2-7B achieves a 15.41% average relative performance gain in automated theorem proving, and 8.18% in math word problems. Codes and data are available at https://github.com/Eleanor-H/MUSTARD.
翻译:近期大语言模型(LLMs)在数学推理和定理证明等任务中取得了显著进展。由于这两项任务需要严格且形式化的多步推理,成为探索LLMs推理能力的重要领域,但仍面临关键挑战。以往研究(如思维链CoT)揭示了中间步骤引导的有效性,但此类逐步骤注释需要大量人工成本,导致当前基准训练步骤不足。为此,本文提出MUSTARD——一种掌握高质量、多样性定理与证明数据统一合成的数据生成框架。MUSTARD通过三个阶段合成数据:(1)采样少量数学概念种子作为问题类别;(2)基于采样概念引导生成式语言模型同时生成问题及其逐步形式化解法;(3)利用证明助手(如Lean Prover)筛选有效证明。通过所提出的MUSTARD,我们构建了包含5,866个有效数据点的定理证明基准MUSTARDSAUCE。每个数据点包含非正式陈述、非正式证明及通过验证器检验的形式化证明译文。我们进行了广泛分析,证明MUSTARD能生成经验证的高质量逐步数据。进一步将MUSTARDSAUCE用于微调小型语言模型,微调后的Llama 2-7B在自动定理证明中平均相对性能提升15.41%,在数学文字题中提升8.18%。代码与数据见https://github.com/Eleanor-H/MUSTARD。