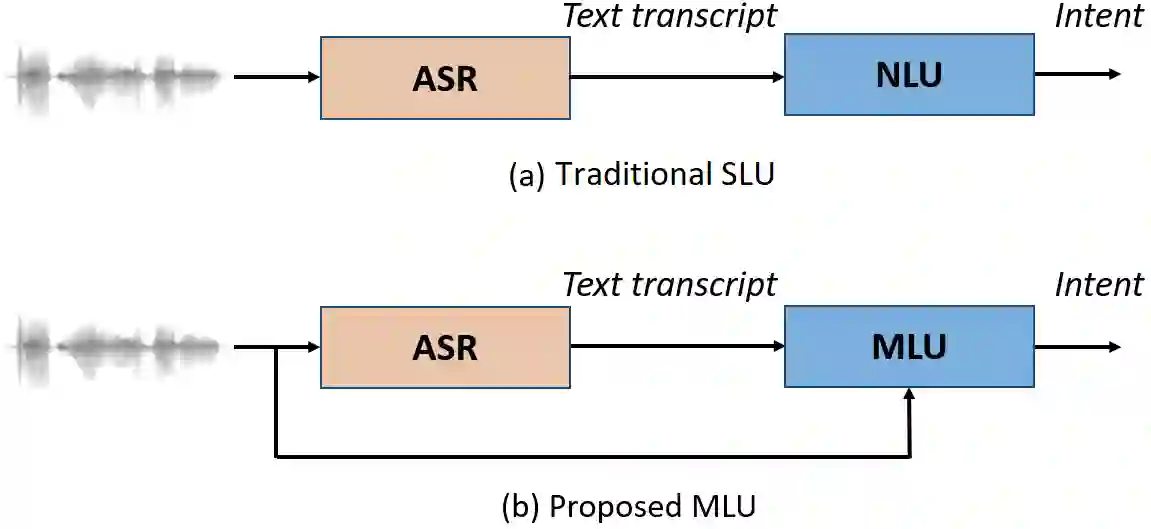
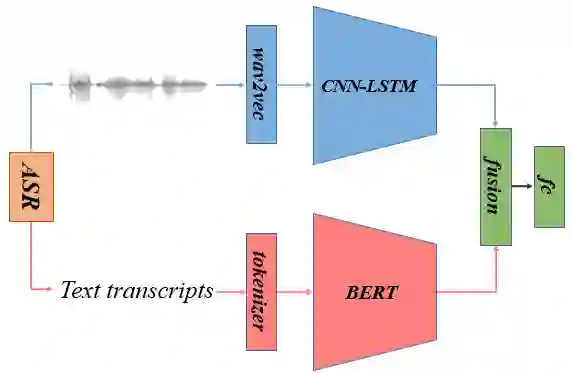
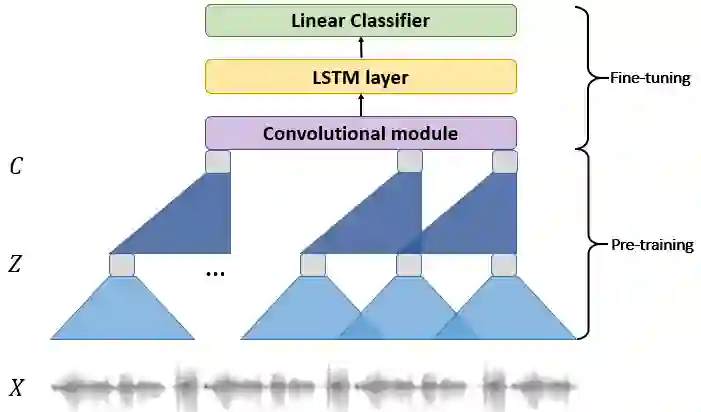
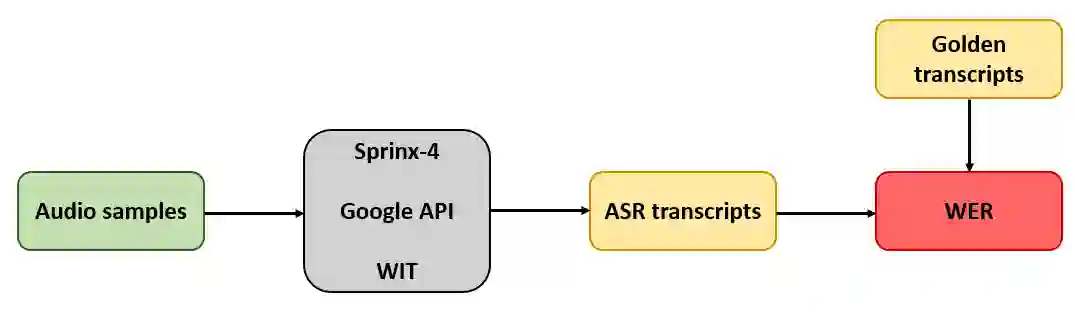
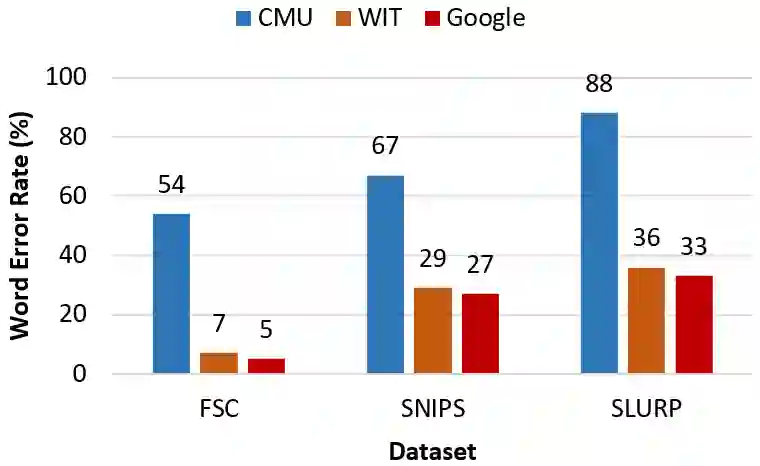
Recent voice assistants are usually based on the cascade spoken language understanding (SLU) solution, which consists of an automatic speech recognition (ASR) engine and a natural language understanding (NLU) system. Because such approach relies on the ASR output, it often suffers from the so-called ASR error propagation. In this work, we investigate impacts of this ASR error propagation on state-of-the-art NLU systems based on pre-trained language models (PLM), such as BERT and RoBERTa. Moreover, a multimodal language understanding (MLU) module is proposed to mitigate SLU performance degradation caused by errors present in the ASR transcript. The MLU benefits from self-supervised features learned from both audio and text modalities, specifically Wav2Vec for speech and Bert/RoBERTa for language. Our MLU combines an encoder network to embed the audio signal and a text encoder to process text transcripts followed by a late fusion layer to fuse audio and text logits. We found that the proposed MLU showed to be robust towards poor quality ASR transcripts, while the performance of BERT and RoBERTa are severely compromised. Our model is evaluated on five tasks from three SLU datasets and robustness is tested using ASR transcripts from three ASR engines. Results show that the proposed approach effectively mitigates the ASR error propagation problem, surpassing the PLM models' performance across all datasets for the academic ASR engine.
翻译:近期语音助手通常基于级联式口语理解(SLU)解决方案,该方案包含自动语音识别(ASR)引擎和自然语言理解(NLU)系统。由于此类方法依赖于ASR输出,常面临所谓的ASR错误传播问题。本研究探讨了ASR错误传播对基于预训练语言模型(PLM)的先进NLU系统(如BERT和RoBERTa)的影响。此外,我们提出了一种多模态语言理解(MLU)模块,以缓解ASR转录文本中错误导致的SLU性能下降。MLU受益于从音频和文本两种模态中学习的自监督特征,具体而言,音频模态采用Wav2Vec,文本模态采用BERT/RoBERTa。我们的MLU结合了编码音频信号的编码器网络和处理文本转录的文本编码器,并通过后融合层融合音频与文本logits。研究发现,所提出的MLU对低质量ASR转录文本具有鲁棒性,而BERT和RoBERTa的性能则严重受损。模型在三个SLU数据集的五个任务上进行了评估,并使用三个ASR引擎生成的转录文本测试了鲁棒性。结果表明,该方法有效缓解了ASR错误传播问题,在学术ASR引擎下,所有数据集上的性能均超越了PLM模型。