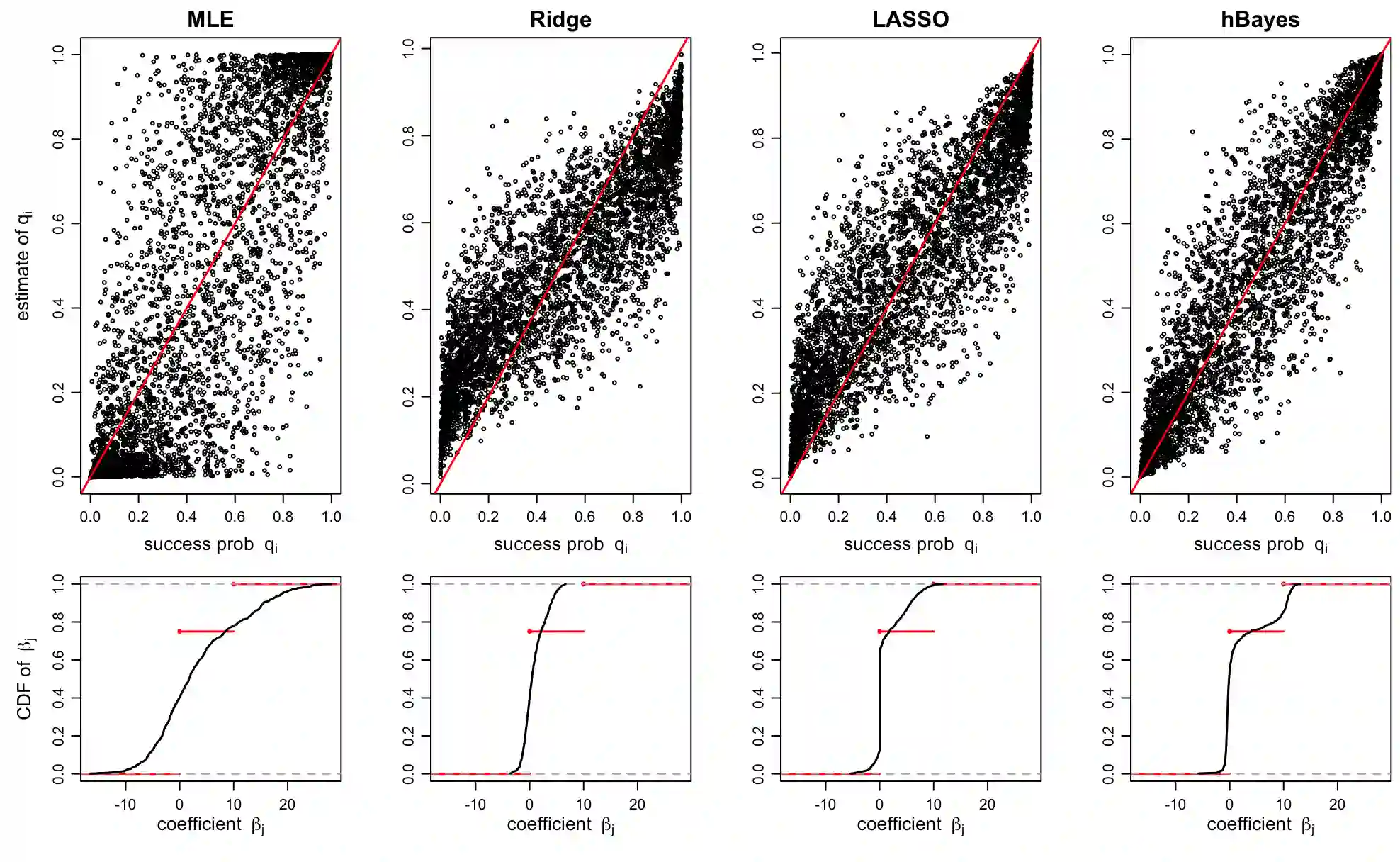
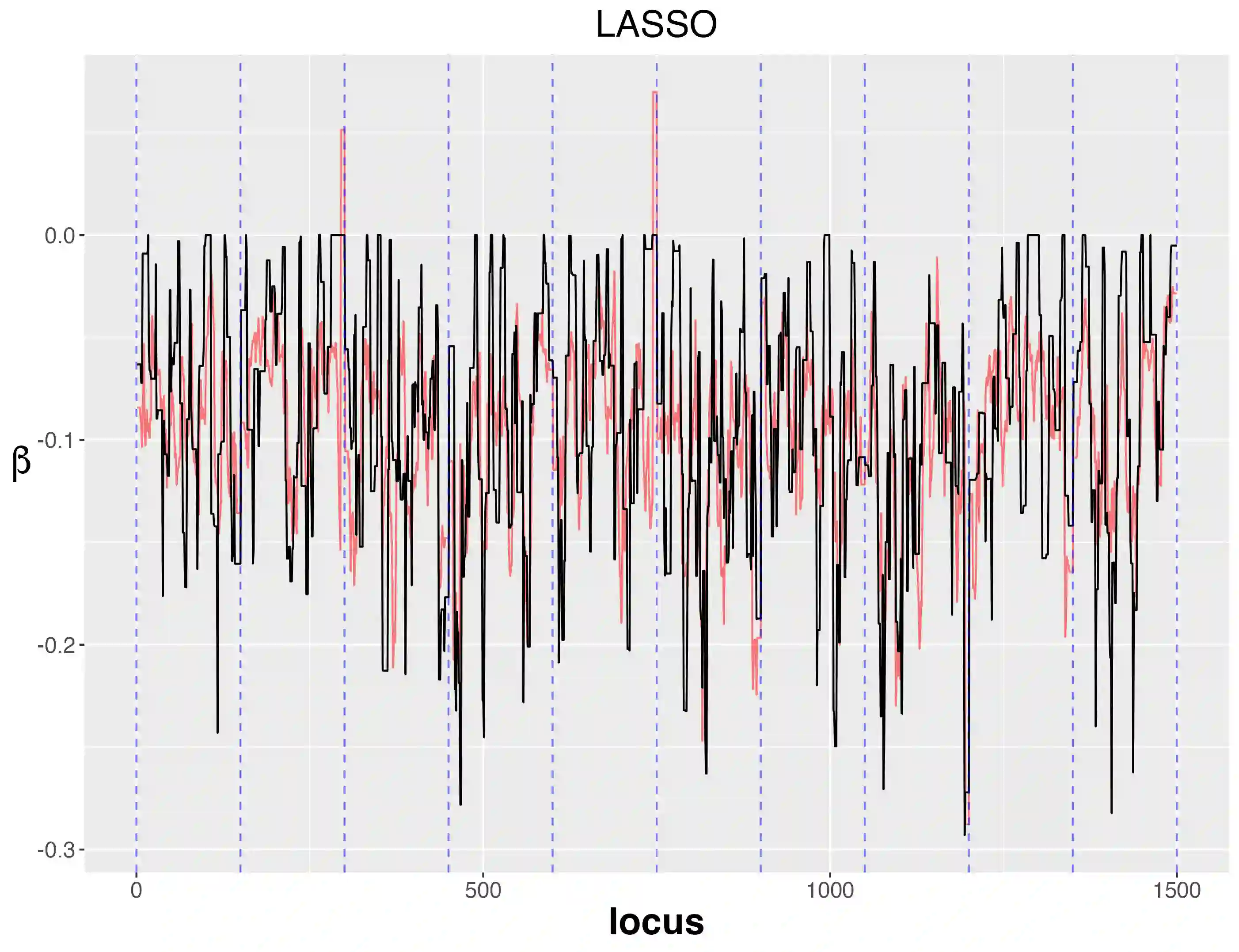
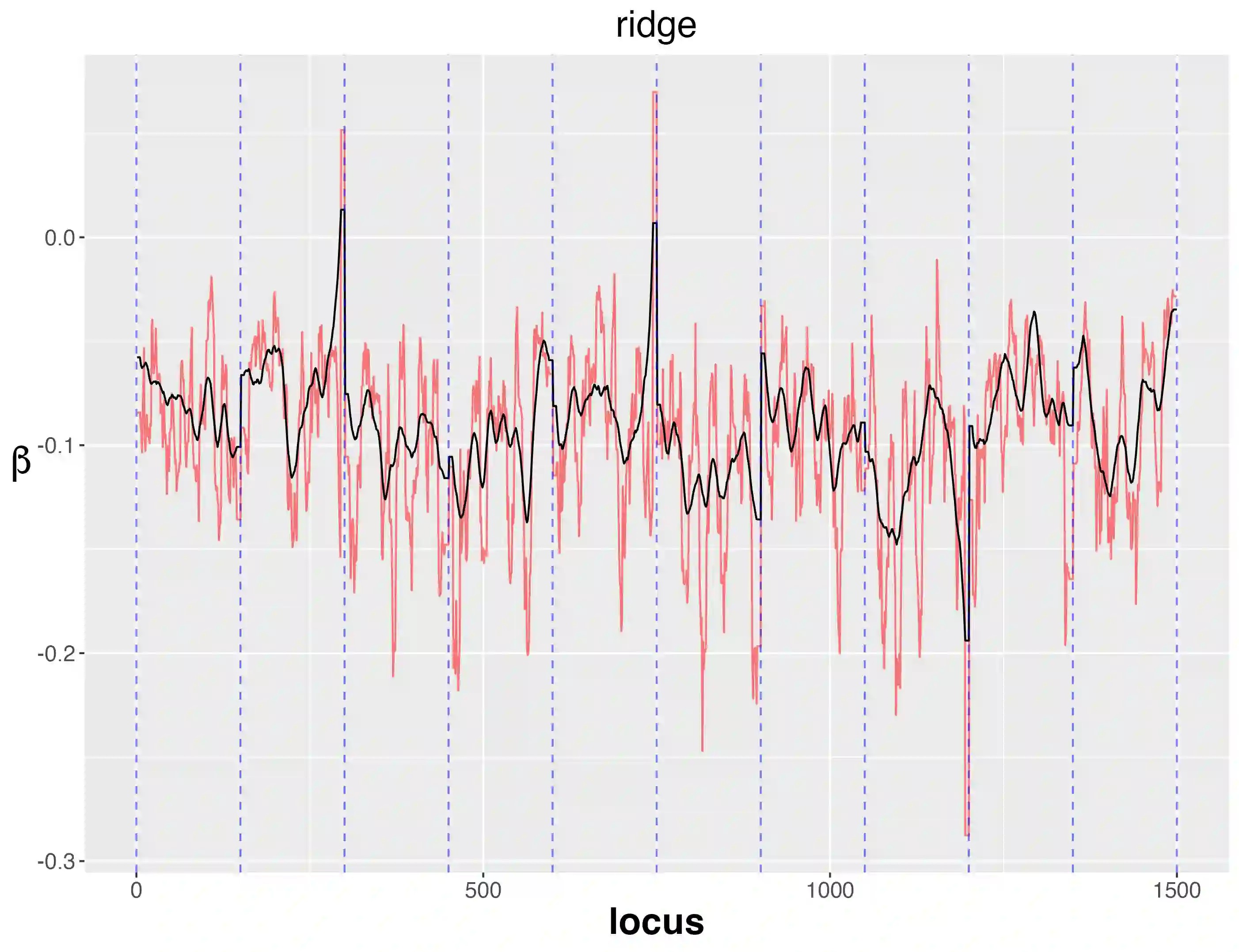
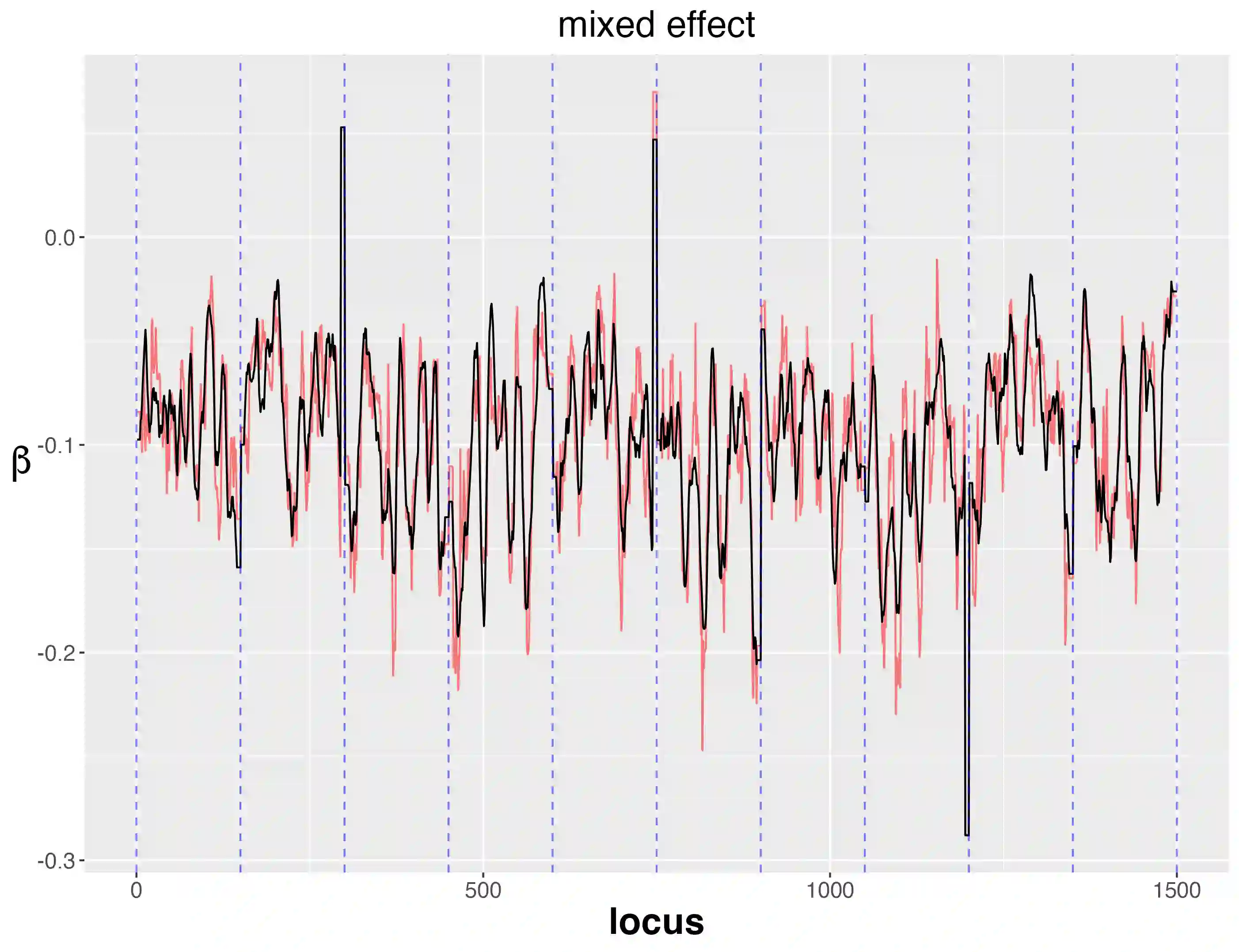
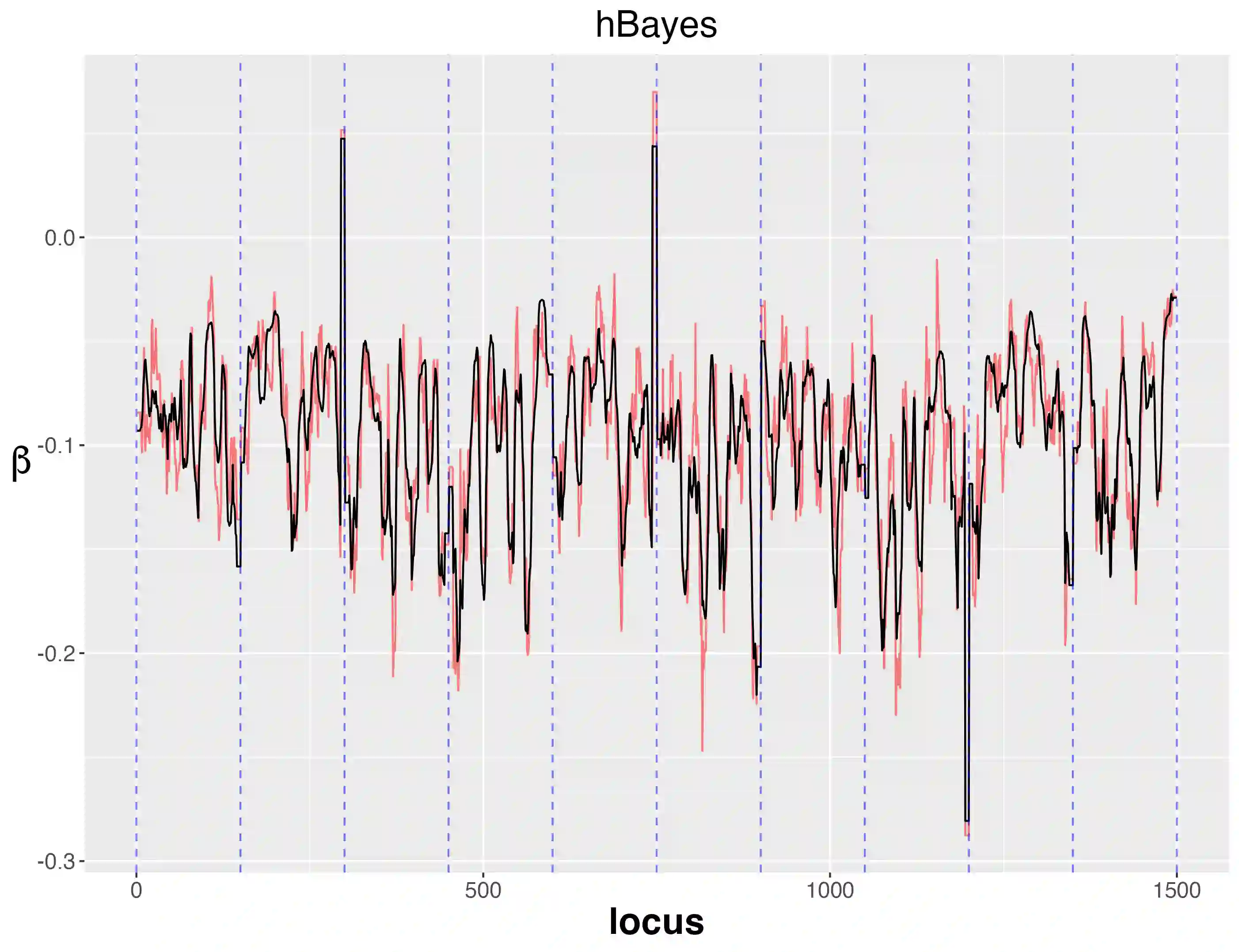
In a given generalized linear model with fixed effects, and under a specified loss function, what is the optimal estimator of the coefficients? We propose as a contender an ideal (oracle) shrinkage estimator, specifically, the Bayes estimator under the particular prior that assigns equal mass to every permutation of the true coefficient vector. We first study this ideal shrinker, showing some optimality properties in both frequentist and Bayesian frameworks by extending notions from Robbins's compound decision theory. To compete with the ideal estimator, taking advantage of the fact that it depends on the true coefficients only through their {\it empirical distribution}, we postulate a hierarchical Bayes model, that can be viewed as a nonparametric counterpart of the usual Gaussian hierarchical model. More concretely, the individual coefficients are modeled as i.i.d.~draws from a common distribution $\pi$, which is itself modeled as random and assigned a Polya tree prior to reflect indefiniteness. We show in simulations that the posterior mean of $\pi$ approximates well the empirical distribution of the true, {\it fixed} coefficients, effectively solving a nonparametric deconvolution problem. This allows the posterior estimates of the coefficient vector to learn the correct shrinkage pattern without parametric restrictions. We compare our method with popular parametric alternatives on the challenging task of gene mapping in the presence of polygenic effects. In this scenario, the regressors exhibit strong spatial correlation, and the signal consists of a dense polygenic component along with several prominent spikes. Our analysis demonstrates that, unlike standard high-dimensional methods such as ridge regression or Lasso, the proposed approach recovers the intricate signal structure, and results in better estimation and prediction accuracy in supporting simulations.
翻译:在给定固定效应的广义线性模型中,在特定损失函数下,系数的最优估计量是什么?我们提出了一种理想(神谕)收缩估计量作为竞争者,具体而言,该估计量是在给真实系数向量的每个排列赋予相等质量的特定期望分布下的贝叶斯估计。我们首先研究这一理想收缩估计量,通过扩展罗宾斯复合决策理论的概念,在频率派和贝叶斯框架下展示了其最优性。为了与理想估计量竞争,利用其仅取决于真实系数的经验分布这一事实,我们假设了一个分层贝叶斯模型,该模型可被视为通常高斯分层模型的非参数对应物。具体而言,个体系数被建模为来自共同分布π的独立同分布抽样,而π本身被建模为随机分布,并赋予Polya树先验以反映不确定性。模拟实验表明,π的后验均值能很好地逼近真实固定系数的经验分布,从而有效解决了非参数反卷积问题。这使得系数向量的后验估计能够无需参数限制地学习正确的收缩模式。我们将我们的方法与流行的参数替代方法在多基因效应存在下具有挑战性的基因图谱任务上进行了比较。在此场景中,回归变量呈现强空间相关性,信号由密集的多基因成分和若干显著尖峰构成。我们的分析表明,与岭回归或Lasso等标准高维方法不同,所提出的方法能够恢复复杂的信号结构,并在支持性模拟中取得了更好的估计和预测精度。