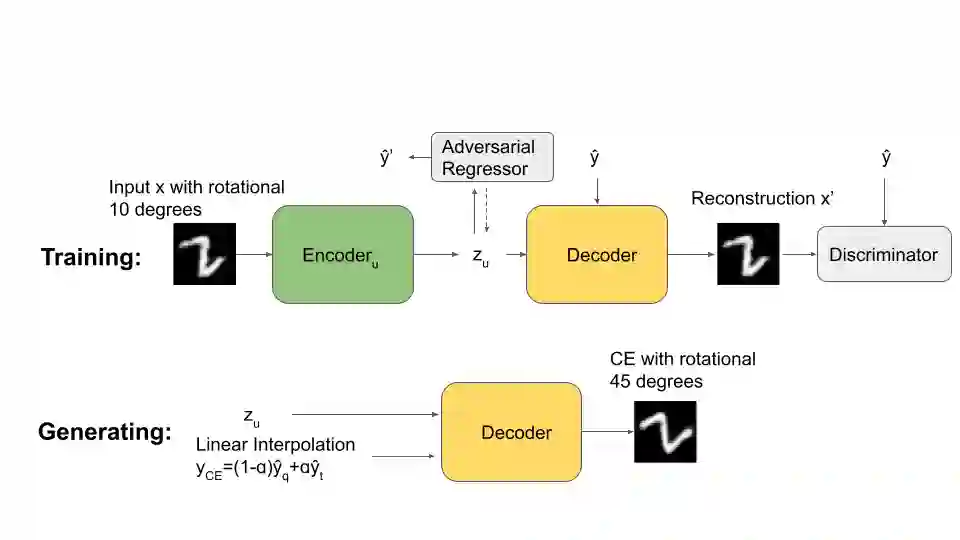
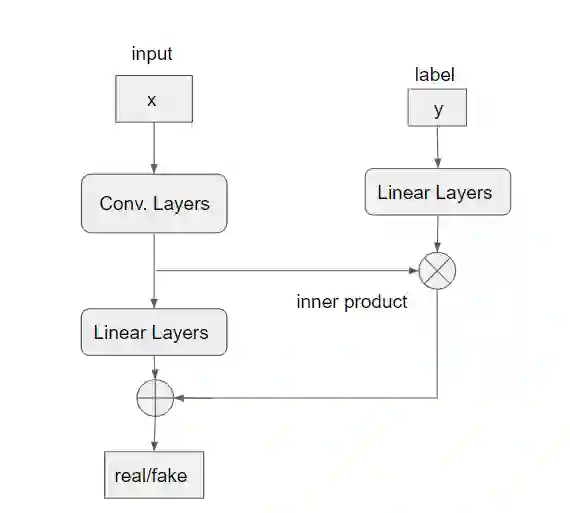
Counterfactual Explanations (CEs) help address the question: How can the factors that influence the prediction of a predictive model be changed to achieve a more favorable outcome from a user's perspective? Thus, they bear the potential to guide the user's interaction with AI systems since they represent easy-to-understand explanations. To be applicable, CEs need to be realistic and actionable. In the literature, various methods have been proposed to generate CEs. However, the majority of research on CEs focuses on classification problems where questions like "What should I do to get my rejected loan approved?" are raised. In practice, answering questions like "What should I do to increase my salary?" are of a more regressive nature. In this paper, we introduce a novel method to generate CEs for a pre-trained regressor by first disentangling the label-relevant from the label-irrelevant dimensions in the latent space. CEs are then generated by combining the label-irrelevant dimensions and the predefined output. The intuition behind this approach is that the ideal counterfactual search should focus on the label-irrelevant characteristics of the input and suggest changes toward target-relevant characteristics. Searching in the latent space could help achieve this goal. We show that our method maintains the characteristics of the query sample during the counterfactual search. In various experiments, we demonstrate that the proposed method is competitive based on different quality measures on image and tabular datasets in regression problem settings. It efficiently returns results closer to the original data manifold compared to three state-of-the-art methods, which is essential for realistic high-dimensional machine learning applications. Our code will be made available as an open-source package upon the publication of this work.
翻译:反事实解释(CEs)有助于回答以下问题:如何改变影响预测模型的因素,以从用户视角获得更有利的结果?因此,它们具备引导用户与AI系统交互的潜力,因为它们提供了易于理解的解释。为具备实用性,CEs需要是现实且可操作的。文献中已有多种生成CEs的方法,但大多数研究聚焦于分类问题,例如“如何让被拒的贷款申请获得批准?”这类问题。在实践中,回答“如何提高我的薪资?”这类问题更具回归性质。本文提出一种新颖方法,通过首先在潜在空间中分离标签相关维度与标签无关维度,为预训练回归器生成CEs。随后,通过组合标签无关维度和预设输出生成CEs。该方法的直觉在于:理想的反事实搜索应聚焦于输入的标签无关特征,并向目标相关特征方向提出改变建议。在潜在空间中搜索有助于实现这一目标。我们证明该方法在反事实搜索过程中保留了查询样本的特征。通过多项实验,我们展示了所提方法在回归问题场景下,基于图像和表格数据集的不同质量评估指标均具有竞争力。与三种最先进方法相比,该方法能高效返回更接近原始数据流形的结果,这对高维度机器学习应用的实际性至关重要。本工作发表后,相关代码将以开源包形式发布。