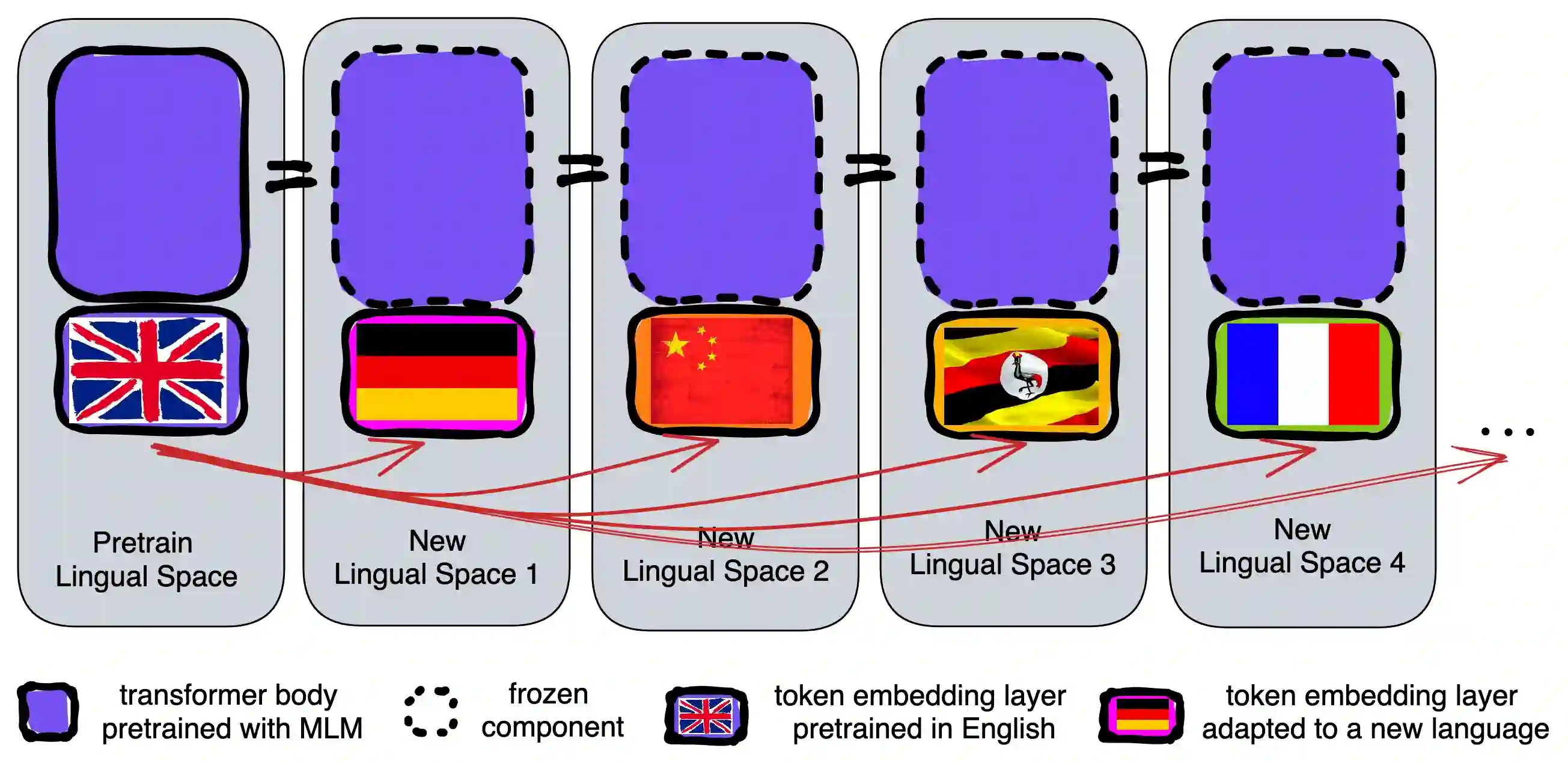
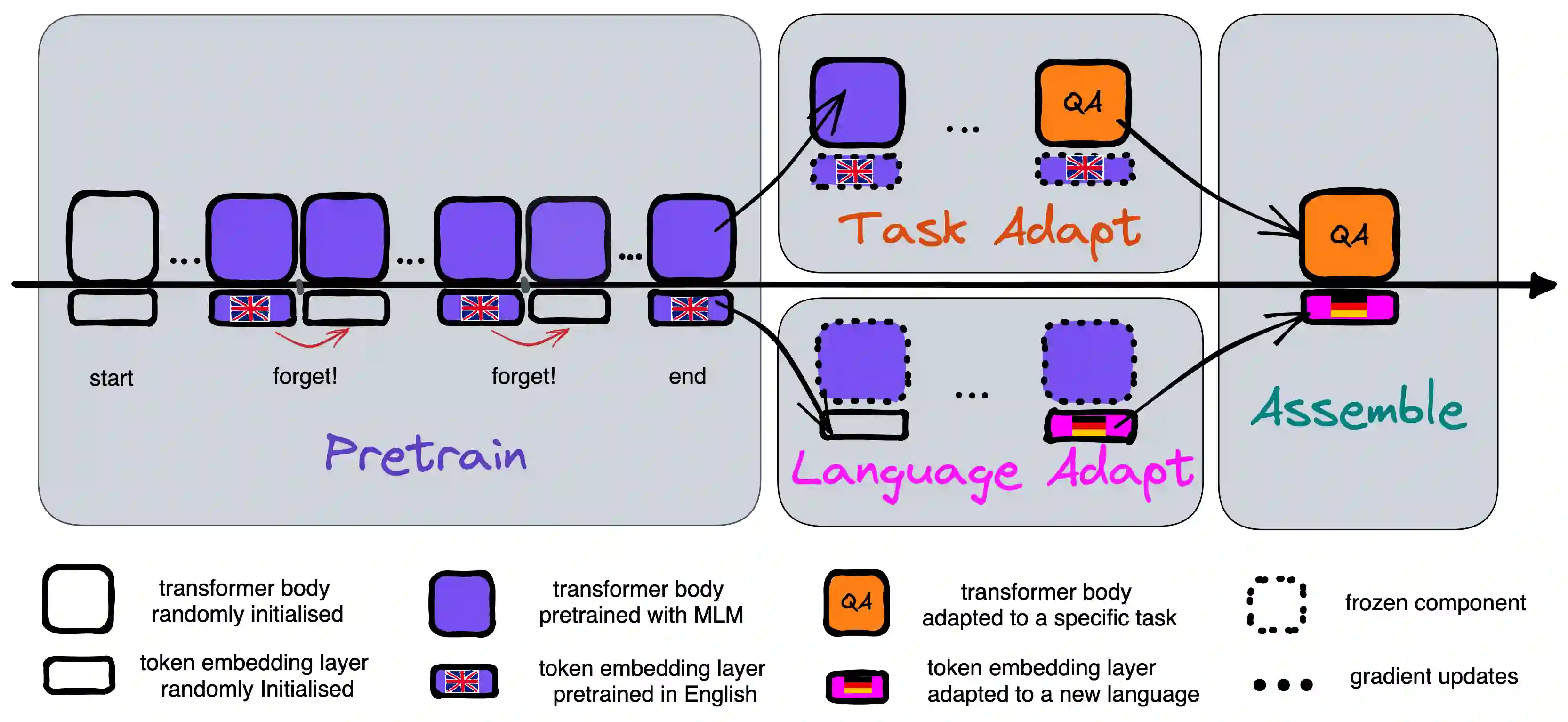
Pretrained language models (PLMs) are today the primary model for natural language processing. Despite their impressive downstream performance, it can be difficult to apply PLMs to new languages, a barrier to making their capabilities universally accessible. While prior work has shown it possible to address this issue by learning a new embedding layer for the new language, doing so is both data and compute inefficient. We propose to use an active forgetting mechanism during pretraining, as a simple way of creating PLMs that can quickly adapt to new languages. Concretely, by resetting the embedding layer every K updates during pretraining, we encourage the PLM to improve its ability of learning new embeddings within a limited number of updates, similar to a meta-learning effect. Experiments with RoBERTa show that models pretrained with our forgetting mechanism not only demonstrate faster convergence during language adaptation but also outperform standard ones in a low-data regime, particularly for languages that are distant from English.
翻译:预训练语言模型(PLM)已成为当今自然语言处理的主要模型。尽管其在下游任务中表现卓越,但将PLM应用于新语言仍面临困难,这阻碍了其功能的全球普及。虽然已有研究通过为新语言学习新的嵌入层来解决这一问题,但该方法在数据和计算上均效率低下。我们提出在预训练过程中引入主动遗忘机制,作为一种简单方法创建能快速适应新语言的PLM。具体而言,通过在预训练期间每K次更新重置嵌入层,我们促使PLM在有限更新次数内提升学习新嵌入的能力,类似于元学习效应。基于RoBERTa的实验表明,采用我们遗忘机制预训练的模型不仅在语言适应过程中表现出更快的收敛速度,还在低数据场景下(尤其是与英语距离较远的语言)优于标准模型。