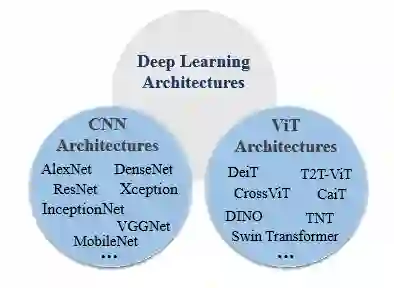
Our review explores the comparative analysis between Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in the domain of image classification, with a particular focus on clothing classification within the e-commerce sector. Utilizing the Fashion MNIST dataset, we delve into the unique attributes of CNNs and ViTs. While CNNs have long been the cornerstone of image classification, ViTs introduce an innovative self-attention mechanism enabling nuanced weighting of different input data components. Historically, transformers have primarily been associated with Natural Language Processing (NLP) tasks. Through a comprehensive examination of existing literature, our aim is to unveil the distinctions between ViTs and CNNs in the context of image classification. Our analysis meticulously scrutinizes state-of-the-art methodologies employing both architectures, striving to identify the factors influencing their performance. These factors encompass dataset characteristics, image dimensions, the number of target classes, hardware infrastructure, and the specific architectures along with their respective top results. Our key goal is to determine the most appropriate architecture between ViT and CNN for classifying images in the Fashion MNIST dataset within the e-commerce industry, while taking into account specific conditions and needs. We highlight the importance of combining these two architectures with different forms to enhance overall performance. By uniting these architectures, we can take advantage of their unique strengths, which may lead to more precise and reliable models for e-commerce applications. CNNs are skilled at recognizing local patterns, while ViTs are effective at grasping overall context, making their combination a promising strategy for boosting image classification performance.
翻译:本文综述了卷积神经网络(CNN)与视觉Transformer(ViT)在图像分类领域的对比分析,特别聚焦于电商领域的服装分类任务。基于Fashion MNIST数据集,我们深入探究了CNN与ViT的独特特性。尽管CNN长期以来一直是图像分类的基石,但ViT引入了一种创新的自注意力机制,能够对不同输入数据成分进行精细加权。从历史角度看,Transformer主要与自然语言处理(NLP)任务相关联。通过对现有文献的全面梳理,本文旨在揭示ViT与CNN在图像分类中的差异。我们的分析细致审视了采用这两种架构的最新方法,力图识别影响其性能的因素,包括数据集特征、图像尺寸、目标类别数量、硬件基础设施、具体架构及其各自的最优结果。核心目标是在电商行业的特定条件与需求下,确定ViT与CNN中更适合Fashion MNIST数据集图像分类的架构。我们强调了将这两种架构以不同形式结合以提升整体性能的重要性。通过融合这些架构,可以充分利用它们各自的独特优势,从而为电商应用开发更精确、更可靠的模型。CNN擅长识别局部模式,而ViT则能有效把握全局语境,因此二者的结合有望成为提升图像分类性能的有效策略。