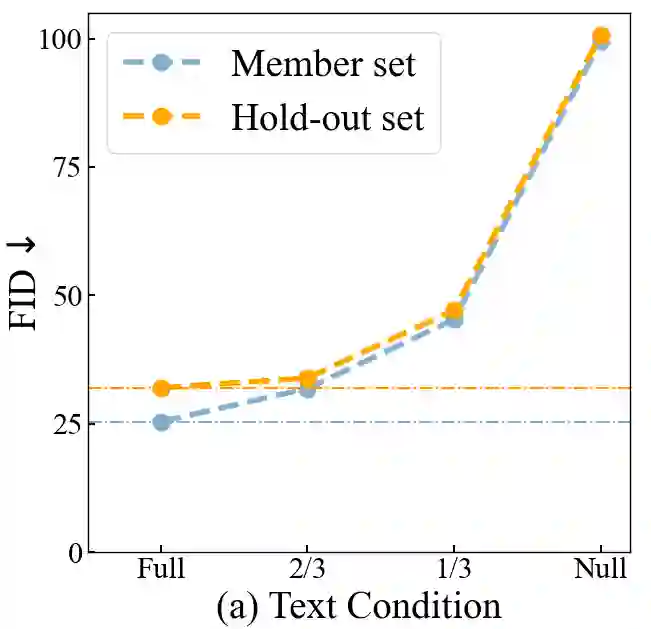
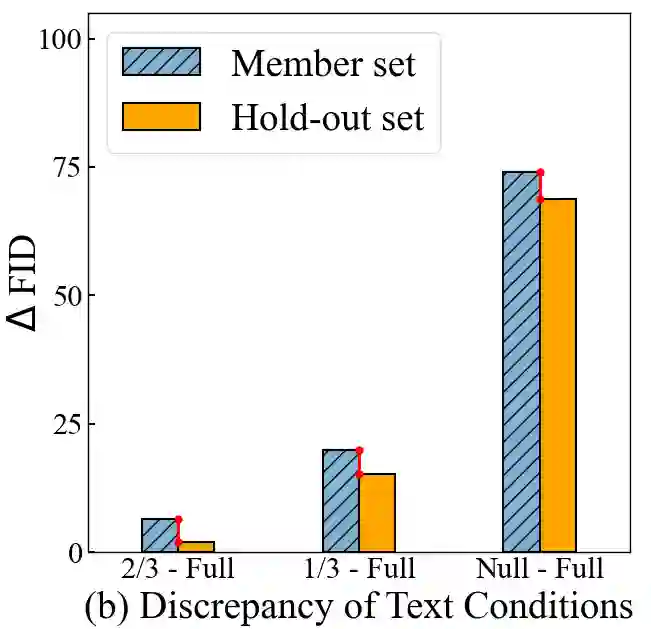
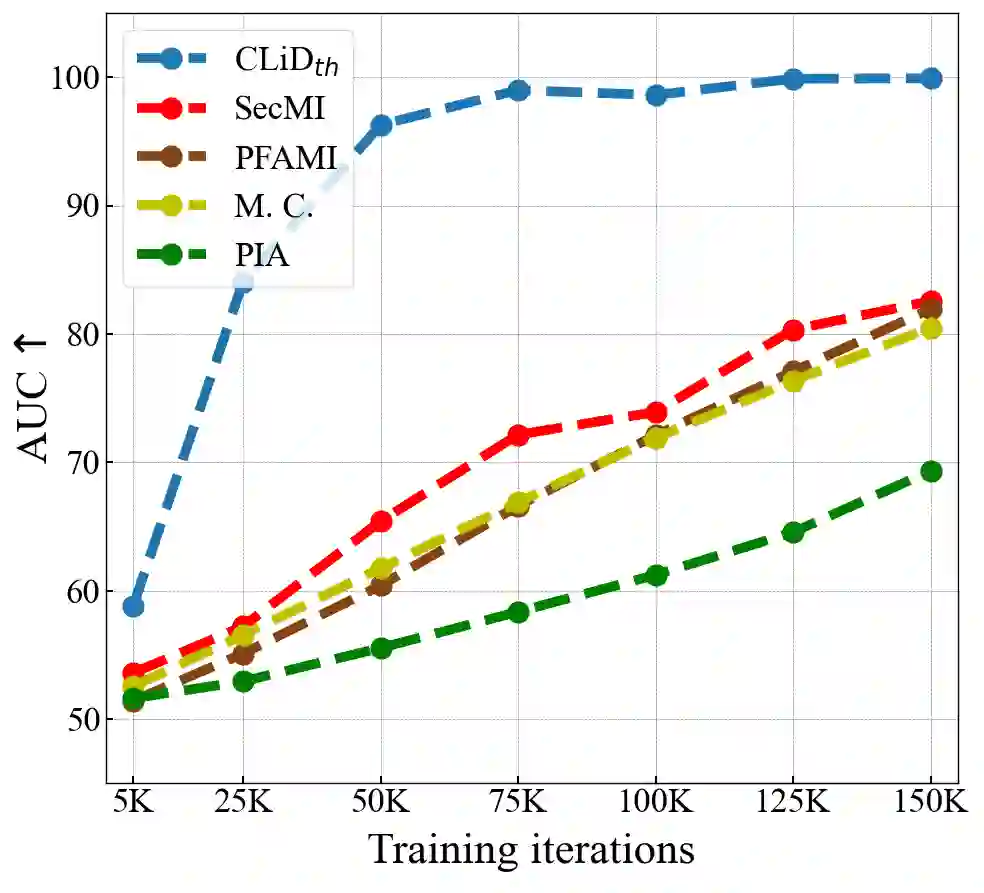
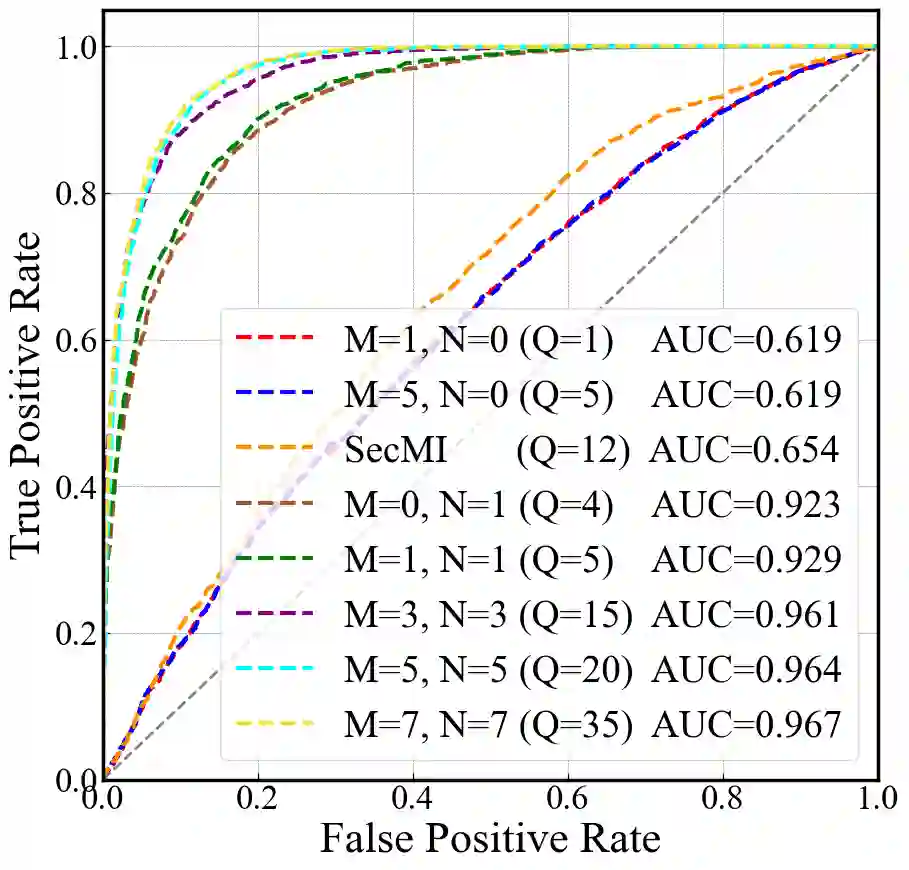
Text-to-image diffusion models have achieved tremendous success in the field of controllable image generation, while also coming along with issues of privacy leakage and data copyrights. Membership inference arises in these contexts as a potential auditing method for detecting unauthorized data usage. While some efforts have been made on diffusion models, they are not applicable to text-to-image diffusion models due to the high computation overhead and enhanced generalization capabilities. In this paper, we first identify a conditional overfitting phenomenon in text-to-image diffusion models, indicating that these models tend to overfit the conditional distribution of images given the text rather than the marginal distribution of images. Based on this observation, we derive an analytical indicator, namely Conditional Likelihood Discrepancy (CLiD), to perform membership inference. This indicator reduces the stochasticity in estimating the memorization of individual samples. Experimental results demonstrate that our method significantly outperforms previous methods across various data distributions and scales. Additionally, our method shows superior resistance to overfitting mitigation strategies such as early stopping and data augmentation.
翻译:文本到图像扩散模型在可控图像生成领域取得了巨大成功,同时也伴随着隐私泄露和数据版权问题。成员推断在此背景下作为一种潜在的审计方法出现,用于检测未经授权的数据使用。尽管已有一些针对扩散模型的研究工作,但由于高计算开销和增强的泛化能力,它们并不适用于文本到图像扩散模型。本文首先识别了文本到图像扩散模型中存在的一种条件过拟合现象,表明这些模型倾向于过拟合给定文本条件下的图像条件分布,而非图像的边缘分布。基于这一观察,我们推导出一个解析性指标,即条件似然差异,用于执行成员推断。该指标降低了在估计单个样本记忆程度时的随机性。实验结果表明,我们的方法在各种数据分布和规模下均显著优于先前方法。此外,我们的方法对早期停止和数据增强等过拟合缓解策略表现出优异的抵抗能力。