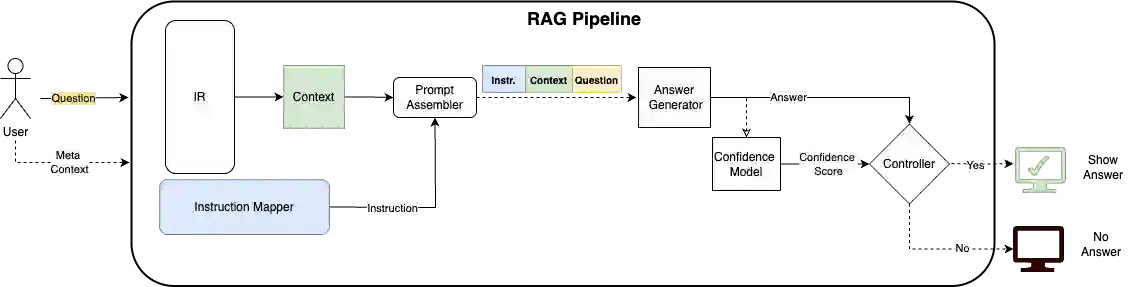
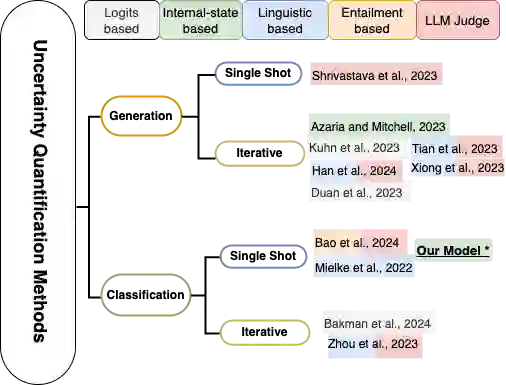
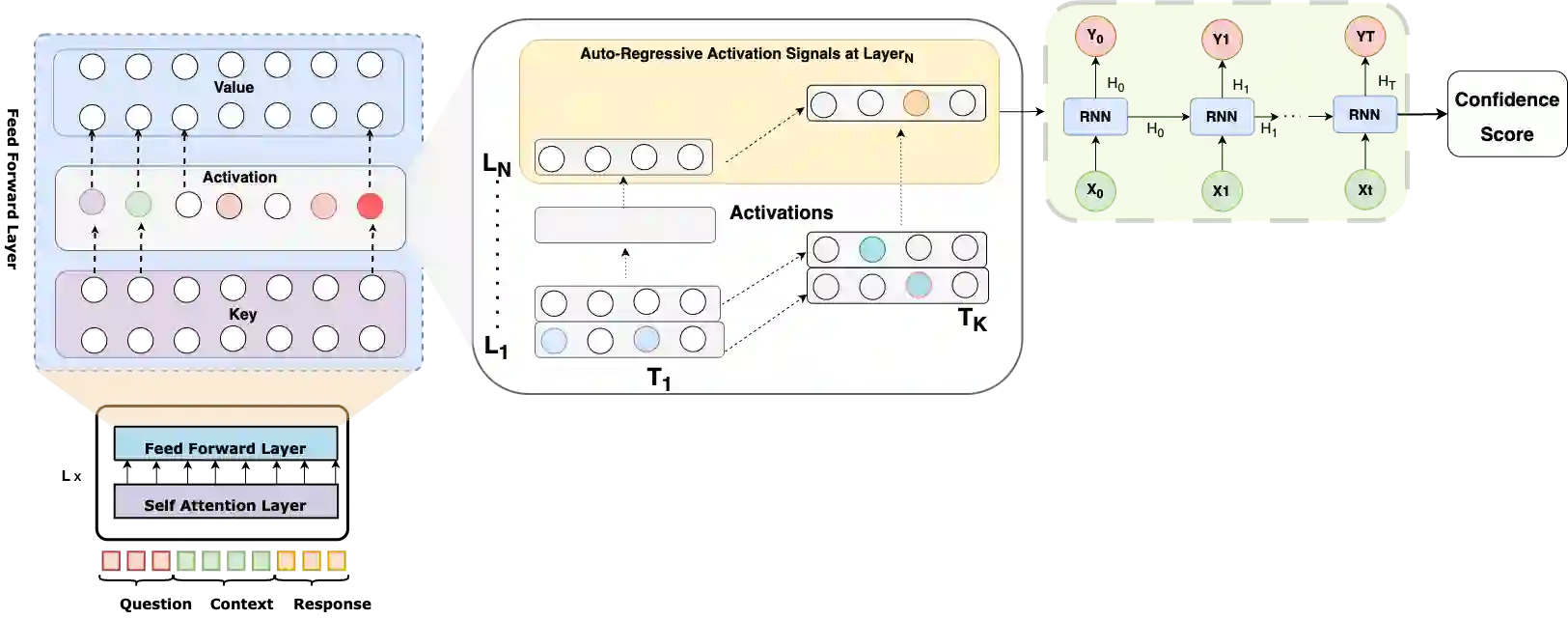
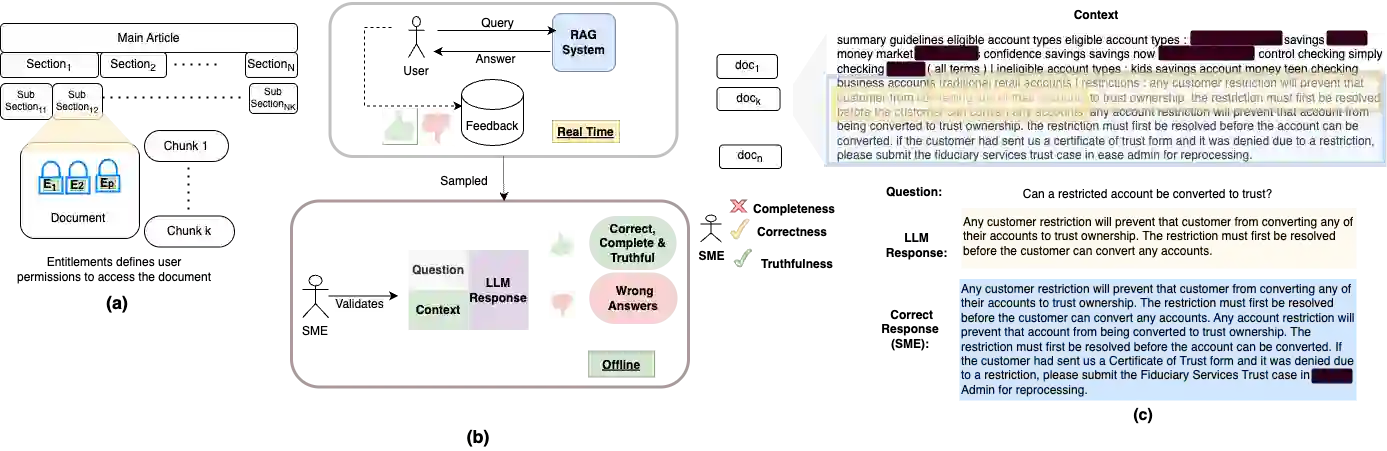
We propose a method for confidence estimation in retrieval-augmented generation (RAG) systems that aligns closely with the correctness of large language model (LLM) outputs. Confidence estimation is especially critical in high-stakes domains such as finance and healthcare, where the cost of an incorrect answer outweighs that of not answering the question. Our approach extends prior uncertainty quantification methods by leveraging raw feed-forward network (FFN) activations as auto-regressive signals, avoiding the information loss inherent in token logits and probabilities after projection and softmax normalization. We model confidence prediction as a sequence classification task, and regularize training with a Huber loss term to improve robustness against noisy supervision. Applied in a real-world financial industry customer-support setting with complex knowledge bases, our method outperforms strong baselines and maintains high accuracy under strict latency constraints. Experiments on Llama 3.1 8B model show that using activations from only the 16th layer preserves accuracy while reducing response latency. Our results demonstrate that activation-based confidence modeling offers a scalable, architecture-aware path toward trustworthy RAG deployment.
翻译:本文提出了一种检索增强生成(RAG)系统中的置信度估计方法,该方法与大语言模型(LLM)输出的正确性高度对齐。在金融和医疗等高风险领域,错误答案的代价远高于不回答问题,因此置信度估计尤为重要。我们的方法通过利用原始前馈网络(FFN)激活作为自回归信号,扩展了先前的不确定性量化方法,避免了投影和softmax归一化后标记对数概率和概率中固有的信息损失。我们将置信度预测建模为序列分类任务,并采用Huber损失项对训练进行正则化,以提高对噪声监督的鲁棒性。在具有复杂知识库的真实金融行业客户支持场景中,本方法优于强基线模型,并在严格的延迟约束下保持高精度。基于Llama 3.1 8B模型的实验表明,仅使用第16层的激活即可保持精度,同时降低响应延迟。我们的结果表明,基于激活的置信度建模为可信赖的RAG部署提供了一条可扩展、架构感知的路径。