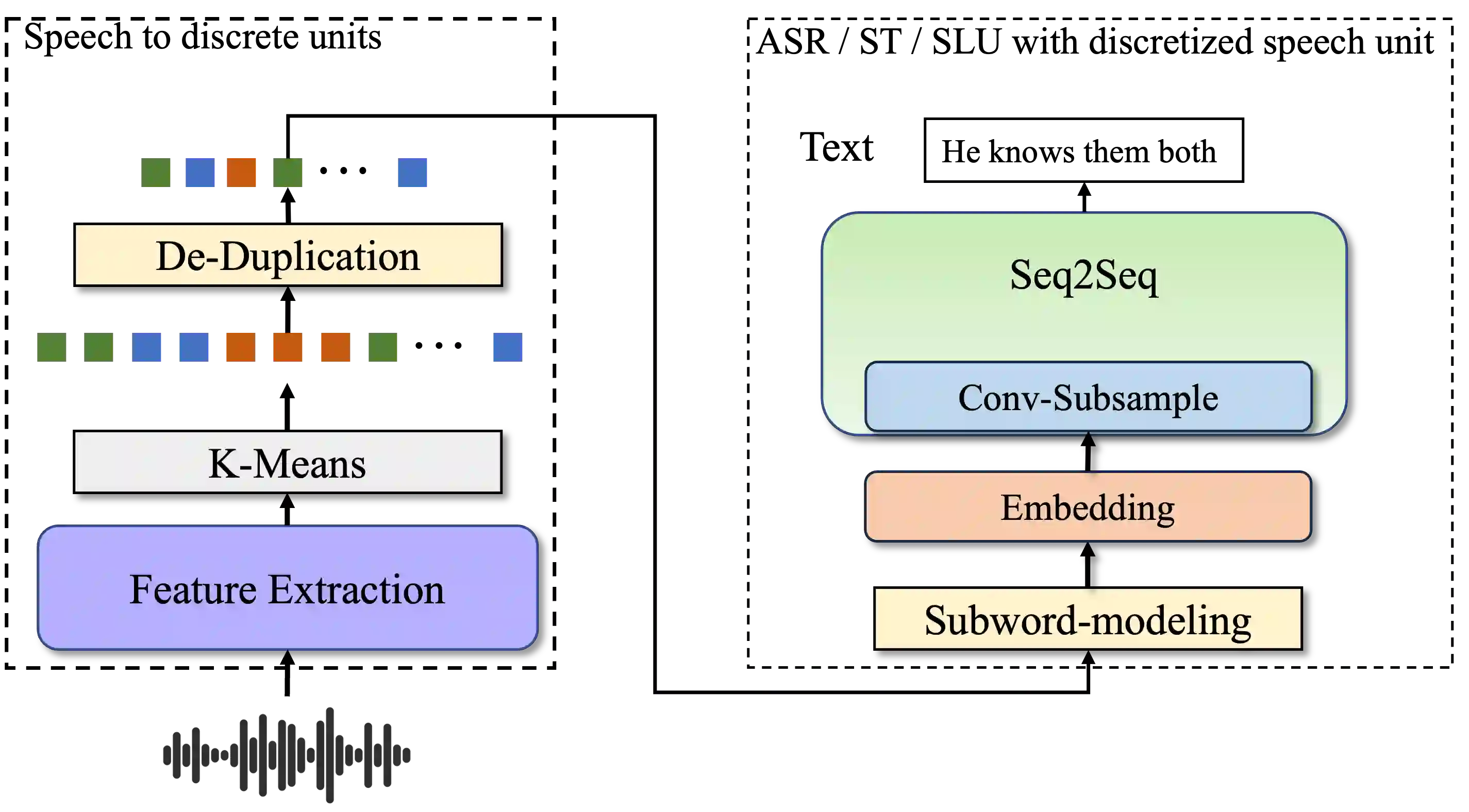
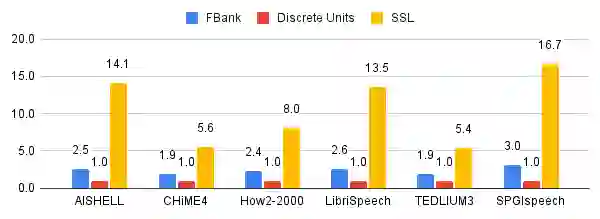
Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
翻译:语音信号通常以每秒数万次的速率采样,其中包含冗余信息,导致序列建模效率低下。诸如语谱图之类的高维语音特征常被用作后续模型的输入,但这些特征仍可能存在冗余。近年研究表明,使用从自监督学习表征中提取的离散语音单元,可显著压缩语音数据规模。通过应用去重和子词建模等多样化方法,还能进一步压缩语音序列长度,从而在保持显著性能的同时大幅缩短训练时间。本研究对离散单元在端到端语音处理模型中的应用进行了全面系统的探索。在12个自动语音识别数据集、3个语音翻译数据集和1个口语理解数据集上的实验表明,离散单元在几乎所有场景下均能取得较为理想的效果。我们计划公开发布实验配置与训练模型,以推动后续相关研究。