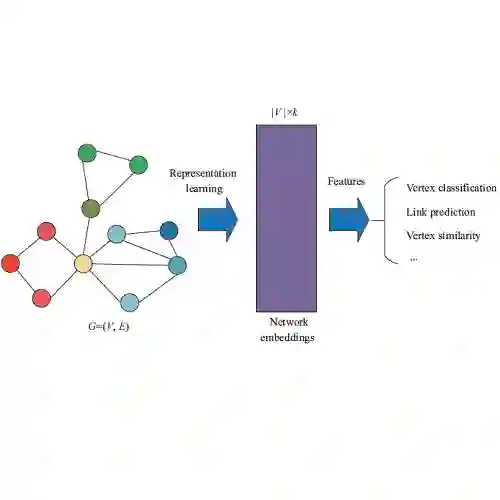
There has been rapid growth in biomedical literature, yet capturing the heterogeneity of the bibliographic information of these articles remains relatively understudied. Although graph mining research via heterogeneous graph neural networks has taken center stage, it remains unclear whether these approaches capture the heterogeneity of the PubMed database, a vast digital repository containing over 33 million articles. We introduce PubMed Graph Benchmark (PGB), a new benchmark dataset for evaluating heterogeneous graph embeddings for biomedical literature. The benchmark contains rich metadata including abstract, authors, citations, MeSH terms, MeSH hierarchy, and some other information. The benchmark contains three different evaluation tasks encompassing systematic reviews, node classification, and node clustering. In PGB, we aggregate the metadata associated with the biomedical articles from PubMed into a unified source and make the benchmark publicly available for any future works.
翻译:生物医学文献数量快速增长,然而对这些文献书目信息异质性的捕捉仍相对研究不足。尽管基于异质图神经网络的图挖掘研究已占据核心地位,但这些方法能否有效捕捉PubMed数据库(包含超过3300万篇文章的庞大数字文献库)的异质性仍不明确。我们提出PubMed图基准(PGB),这是一个用于评估生物医学文献异质图嵌入的新基准数据集。该基准包含丰富的元数据,包括摘要、作者、引用信息、MeSH术语、MeSH层次结构及其他信息。基准包含三个不同的评估任务:系统综述、节点分类和节点聚类。在PGB中,我们将PubMed生物医学文献的相关元数据整合为统一资源,并公开该基准供未来研究使用。