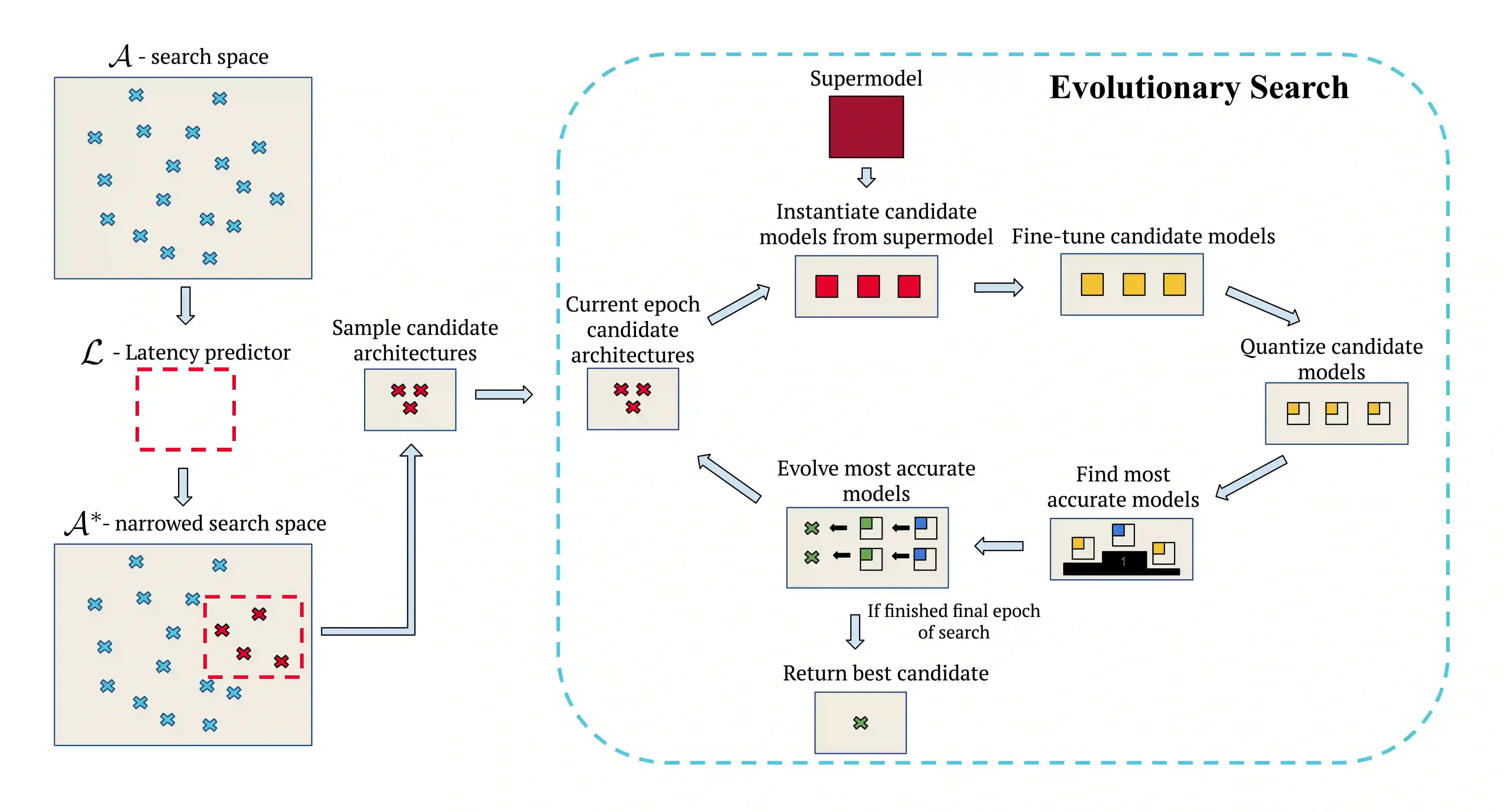
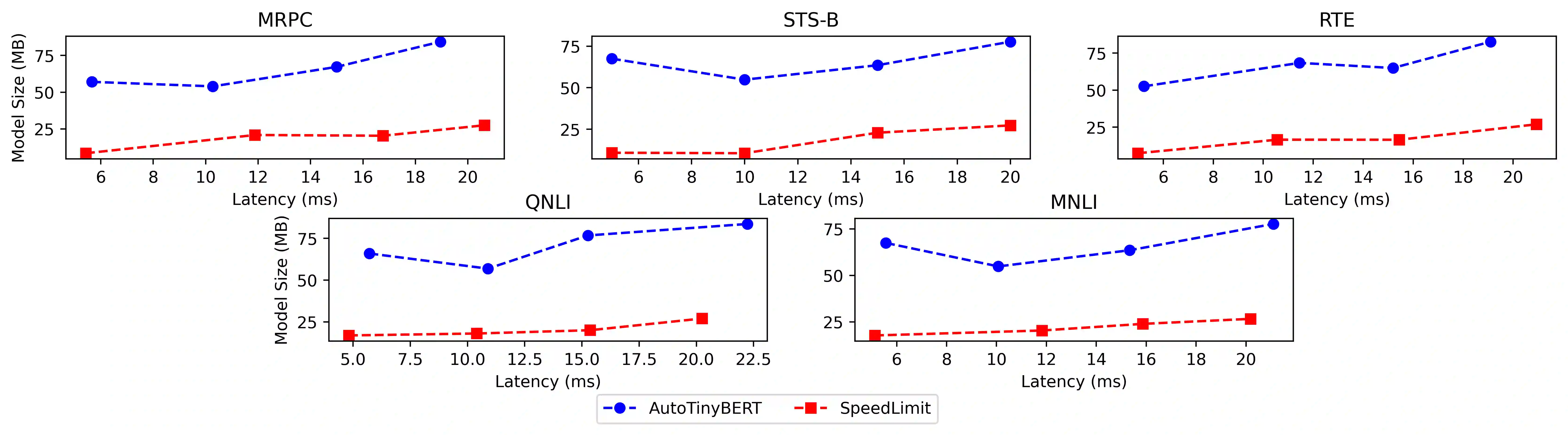
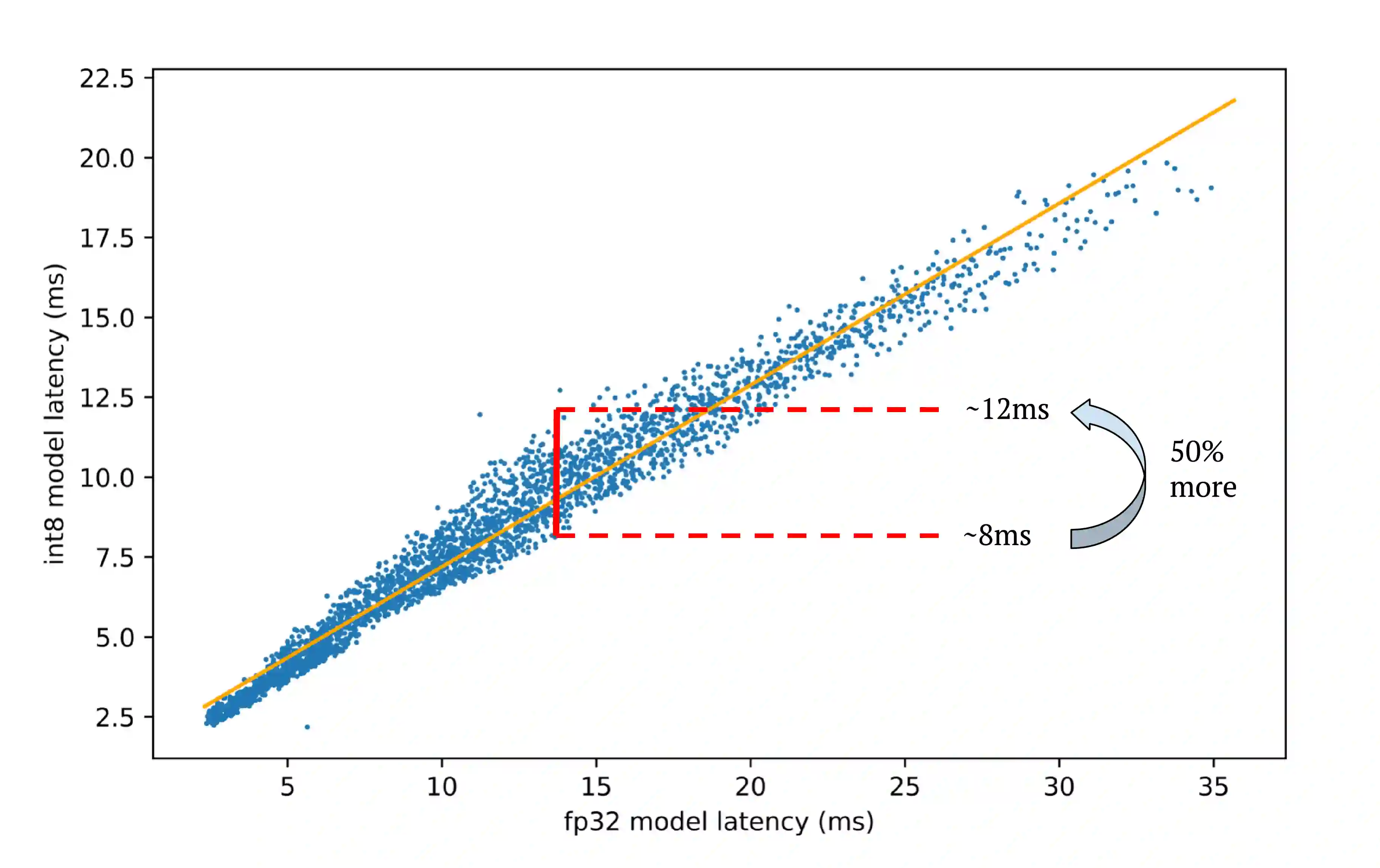
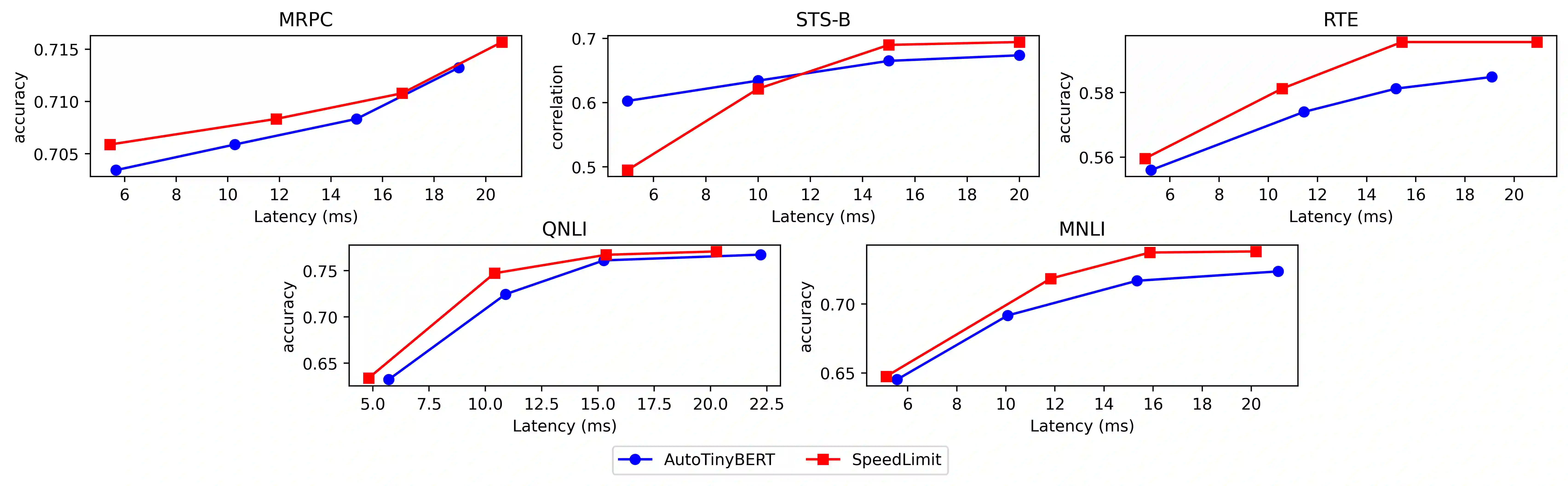
While research in the field of transformer models has primarily focused on enhancing performance metrics such as accuracy and perplexity, practical applications in industry often necessitate a rigorous consideration of inference latency constraints. Addressing this challenge, we introduce SpeedLimit, a novel Neural Architecture Search (NAS) technique that optimizes accuracy whilst adhering to an upper-bound latency constraint. Our method incorporates 8-bit integer quantization in the search process to outperform the current state-of-the-art technique. Our results underline the feasibility and efficacy of seeking an optimal balance between performance and latency, providing new avenues for deploying state-of-the-art transformer models in latency-sensitive environments.
翻译:尽管Transformer模型领域的研究主要聚焦于提升准确率、困惑度等性能指标,但工业界的实际应用往往需要严格考虑推理延迟约束。针对这一挑战,我们提出SpeedLimit——一种新颖的神经架构搜索(NAS)技术,该技术能在满足延迟上限约束的同时优化模型准确率。我们的方法在搜索过程中引入8位整数量化机制,以此超越当前最先进的技术水平。实验结果证实了在性能与延迟之间寻求最优平衡的可行性与有效性,为在延迟敏感场景中部署先进Transformer模型开辟了新途径。