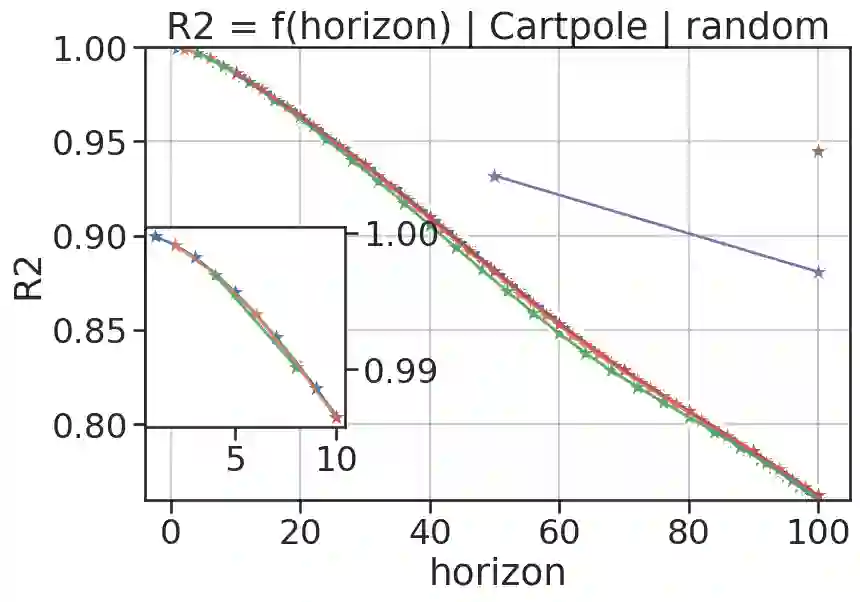
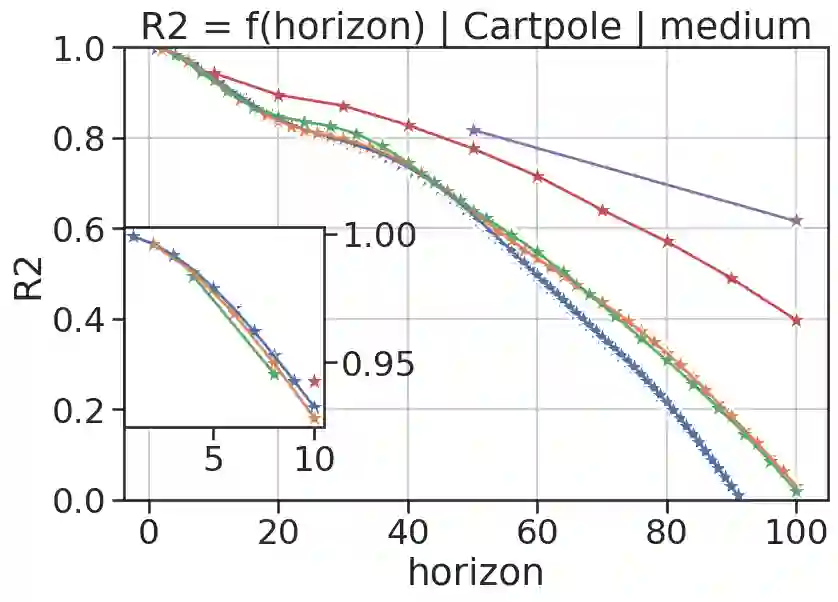
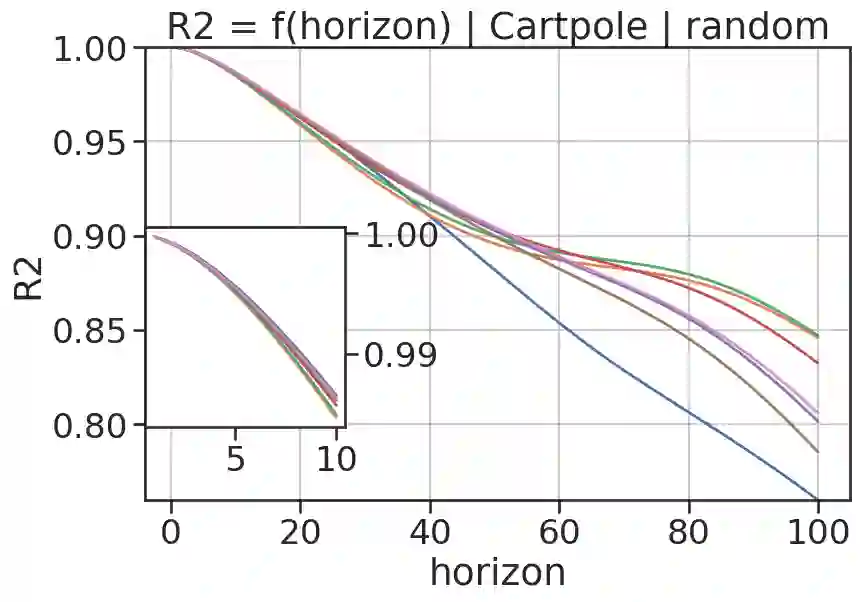
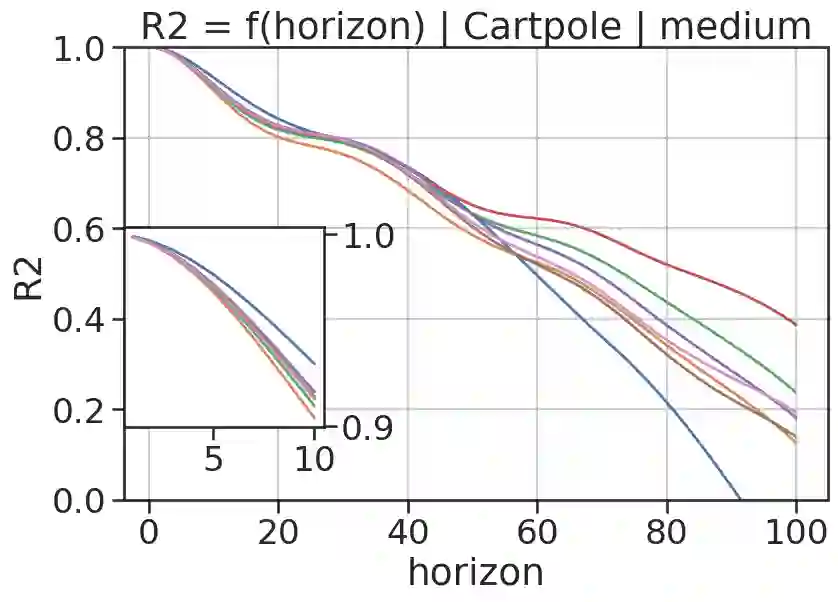
In model-based reinforcement learning (MBRL), most algorithms rely on simulating trajectories from one-step dynamics models learned on data. A critical challenge of this approach is the compounding of one-step prediction errors as length of the trajectory grows. In this paper we tackle this issue by using a multi-timestep objective to train one-step models. Our objective is a weighted sum of a loss function (e.g., negative log-likelihood) at various future horizons. We explore and test a range of weights profiles. We find that exponentially decaying weights lead to models that significantly improve the long-horizon R2 score. This improvement is particularly noticeable when the models were evaluated on noisy data. Finally, using a soft actor-critic (SAC) agent in pure batch reinforcement learning (RL) and iterated batch RL scenarios, we found that our multi-timestep models outperform or match standard one-step models. This was especially evident in a noisy variant of the considered environment, highlighting the potential of our approach in real-world applications.
翻译:在基于模型的强化学习(MBRL)中,大多数算法依赖于从数据学习的一步动力学模型模拟轨迹。该方法的一个关键挑战是,随着轨迹长度增长,一步预测误差会累积。本文通过使用多时间步目标训练一步模型来解决这一问题。我们的目标是未来不同时间跨度上损失函数(如负对数似然)的加权和。我们探索并测试了多种权重分布,发现指数衰减权重可使模型在长期预测的R²分数上显著提升,尤其是在噪声数据评估时效果更为明显。最后,在纯批量强化学习(RL)和迭代批量强化学习场景中使用软演员-评论家(SAC)算法时,我们发现所提出的多时间步模型在性能上优于或匹配标准一步模型,这在所考虑环境的噪声变体中尤为突出,凸显了该方法在实际应用中的潜力。