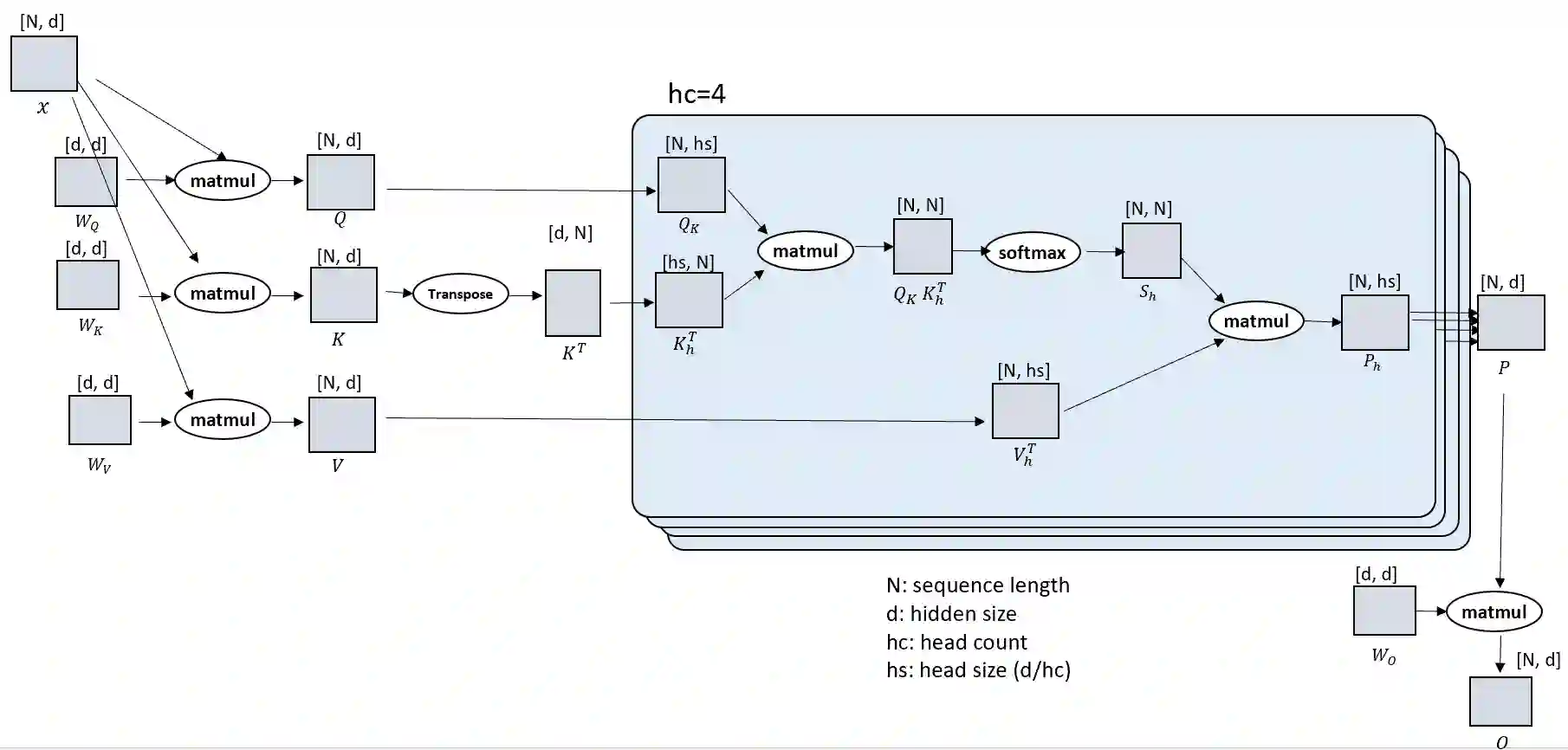
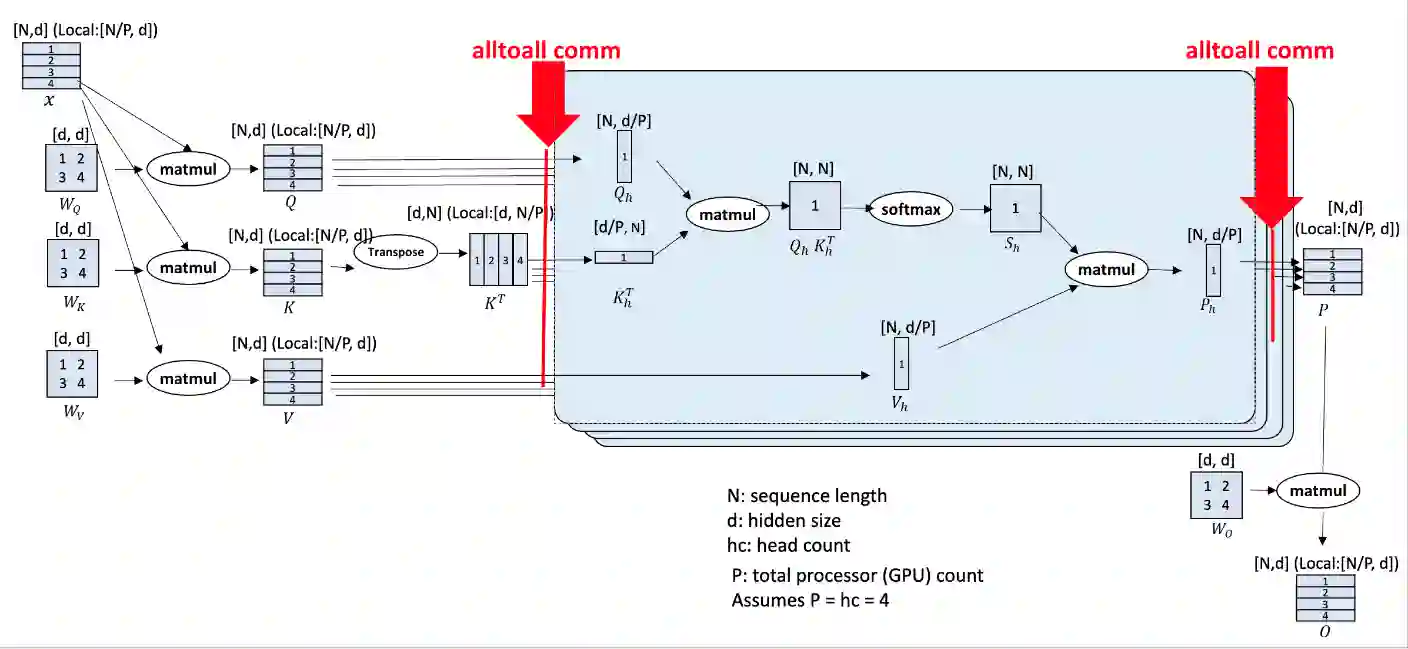
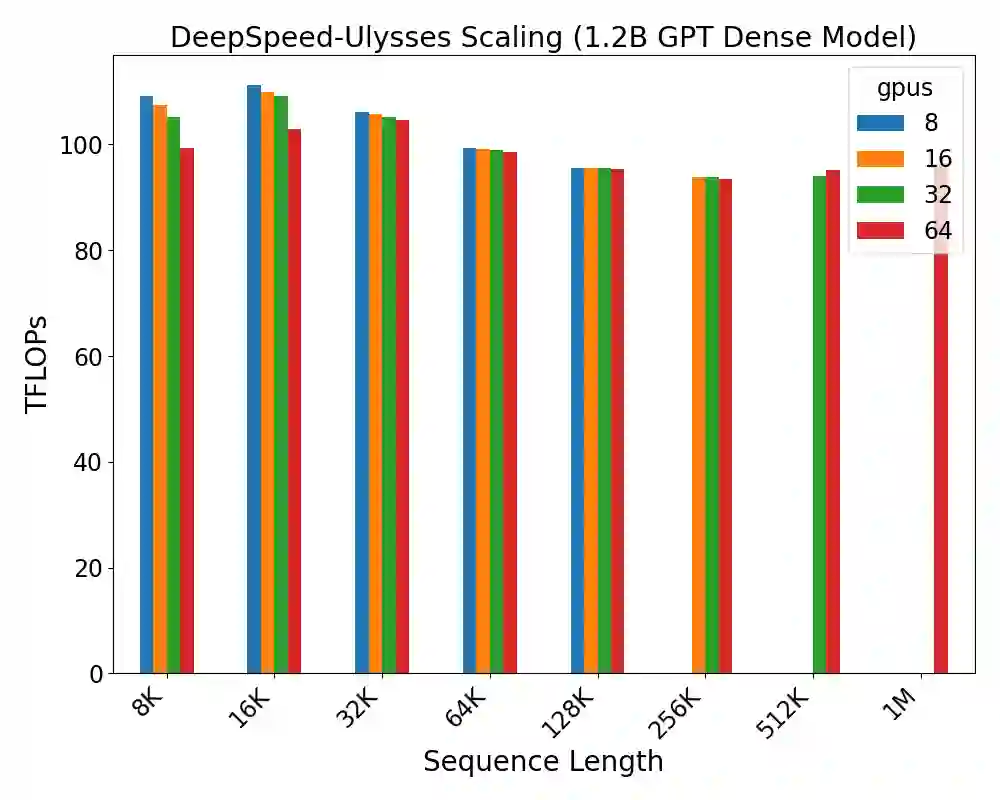
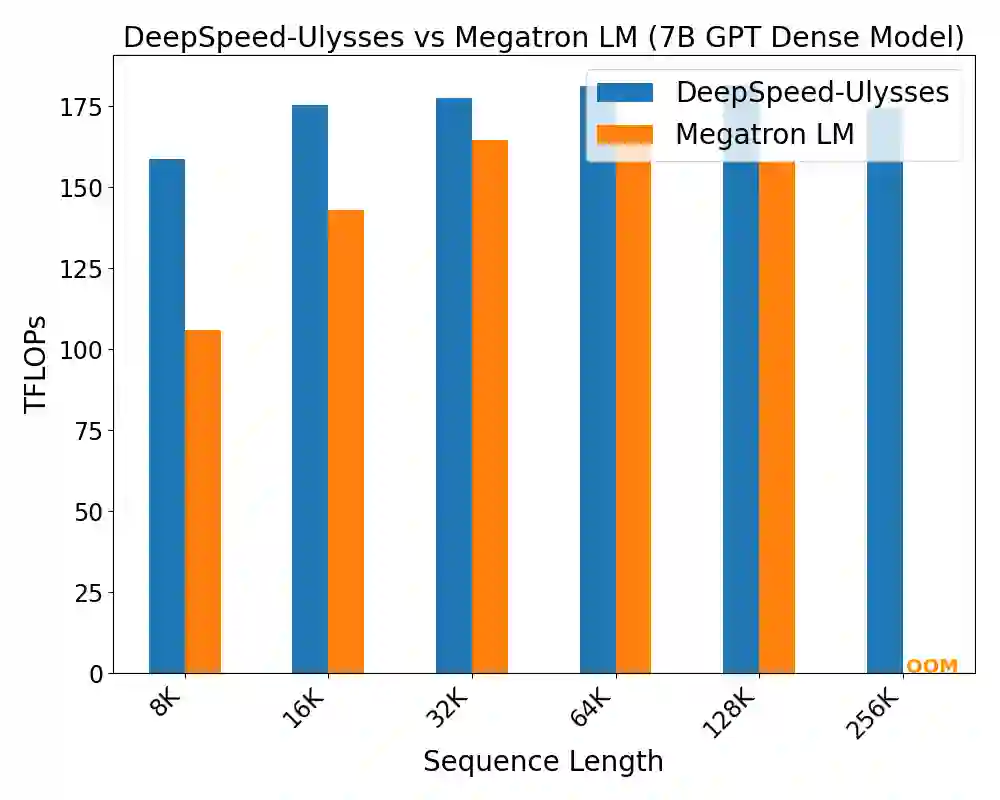
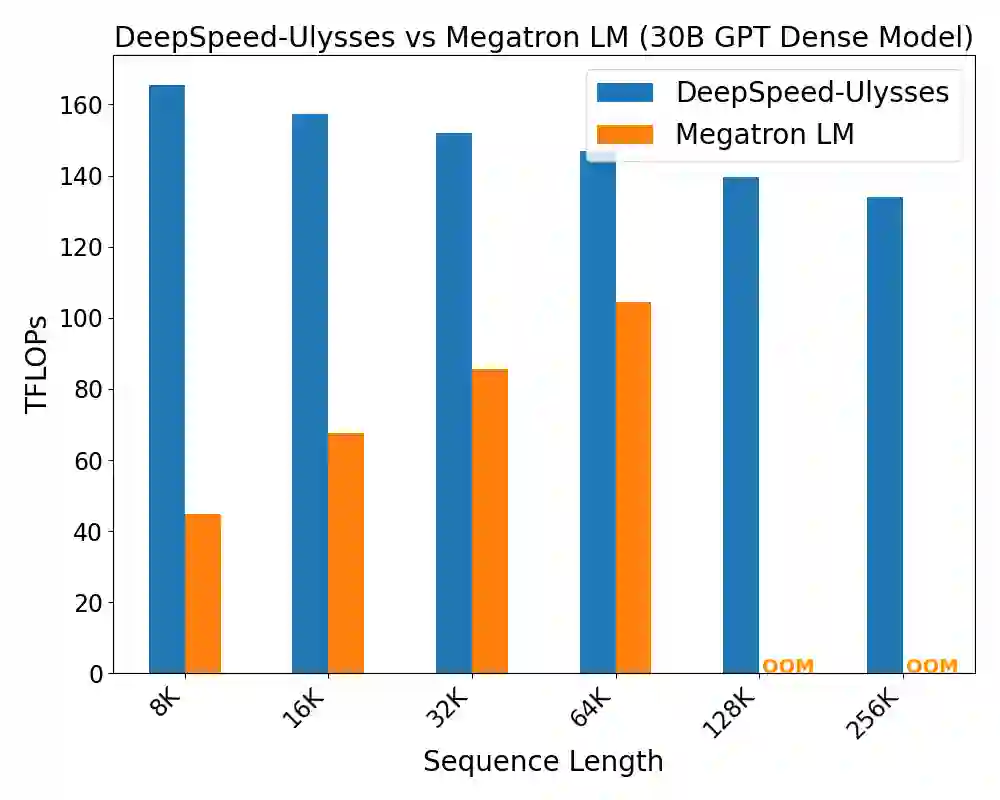
Computation in a typical Transformer-based large language model (LLM) can be characterized by batch size, hidden dimension, number of layers, and sequence length. Until now, system works for accelerating LLM training have focused on the first three dimensions: data parallelism for batch size, tensor parallelism for hidden size and pipeline parallelism for model depth or layers. These widely studied forms of parallelism are not targeted or optimized for long sequence Transformer models. Given practical application needs for long sequence LLM, renewed attentions are being drawn to sequence parallelism. However, existing works in sequence parallelism are constrained by memory-communication inefficiency, limiting their scalability to long sequence large models. In this work, we introduce DeepSpeed-Ulysses, a novel, portable and effective methodology for enabling highly efficient and scalable LLM training with extremely long sequence length. DeepSpeed-Ulysses at its core partitions input data along the sequence dimension and employs an efficient all-to-all collective communication for attention computation. Theoretical communication analysis shows that whereas other methods incur communication overhead as sequence length increases, DeepSpeed-Ulysses maintains constant communication volume when sequence length and compute devices are increased proportionally. Furthermore, experimental evaluations show that DeepSpeed-Ulysses trains 2.5x faster with 4x longer sequence length than the existing method SOTA baseline.
翻译:典型的基于Transformer的大语言模型(LLM)的计算特征可由批次大小、隐藏维度、层数和序列长度刻画。迄今为止,加速LLM训练的系统工作主要聚焦于前三个维度:针对批次大小的数据并行、针对隐藏维度的张量并行,以及针对模型深度或层数的流水线并行。这些广泛研究的并行形式并非针对长序列Transformer模型设计或优化。鉴于长序列LLM的实际应用需求,序列并行性正重新受到关注。然而,现有序列并行工作受限于通信-内存低效问题,限制了其在长序列大模型上的可扩展性。本文提出DeepSpeed-Ulysses——一种新颖、可移植且有效的方法,用于实现超长序列长度下高效可扩展的LLM训练。DeepSpeed-Ulysses的核心思想是沿序列维度划分输入数据,并采用高效的全到全集合通信进行注意力计算。理论通信分析表明,当其他方法因序列长度增加而产生通信开销时,DeepSpeed-Ulysses在序列长度与计算设备成比例增加时仍保持恒定的通信量。此外,实验评估显示,DeepSpeed-Ulysses在序列长度延长4倍的情况下,训练速度比现有SOTA基线方法快2.5倍。