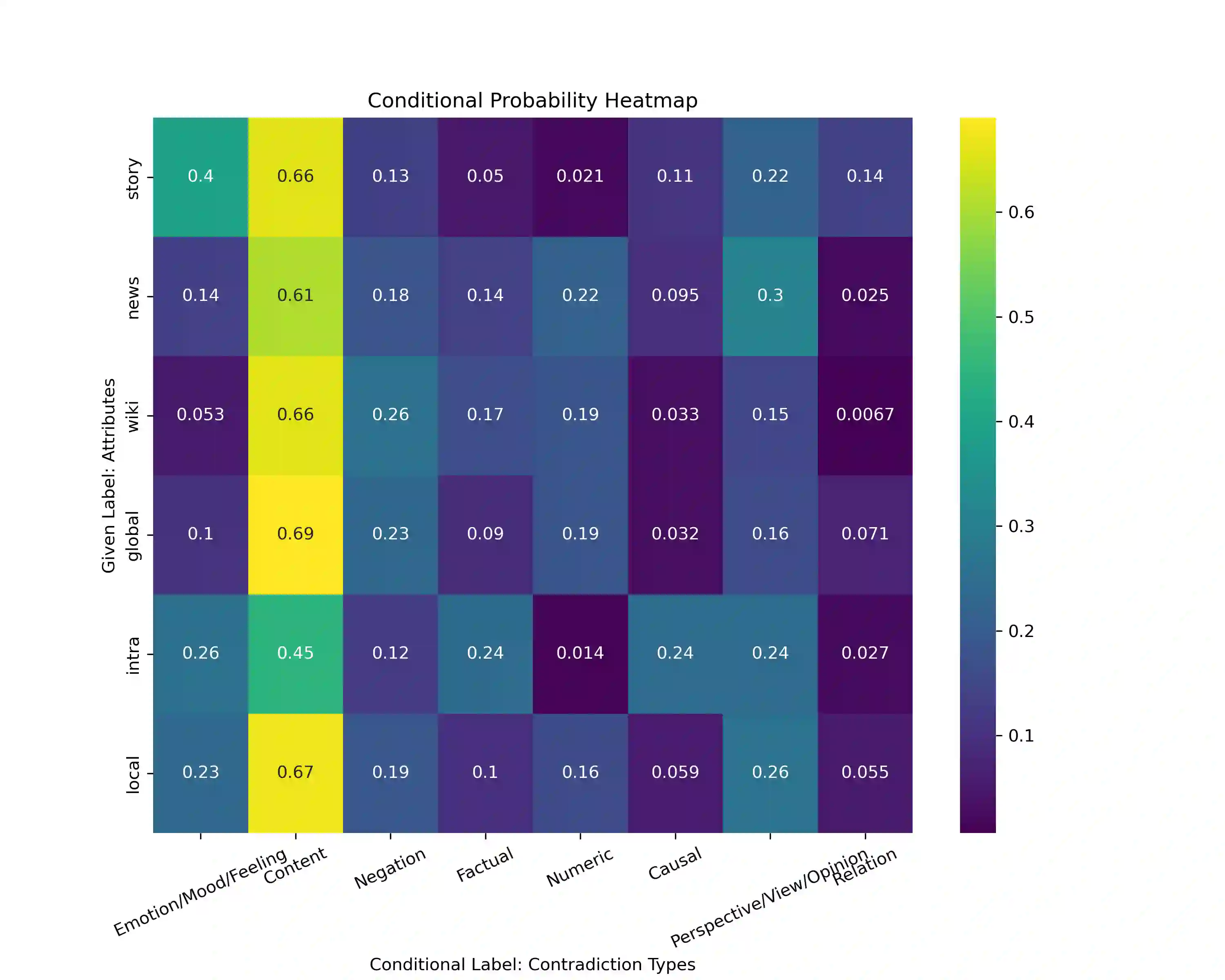
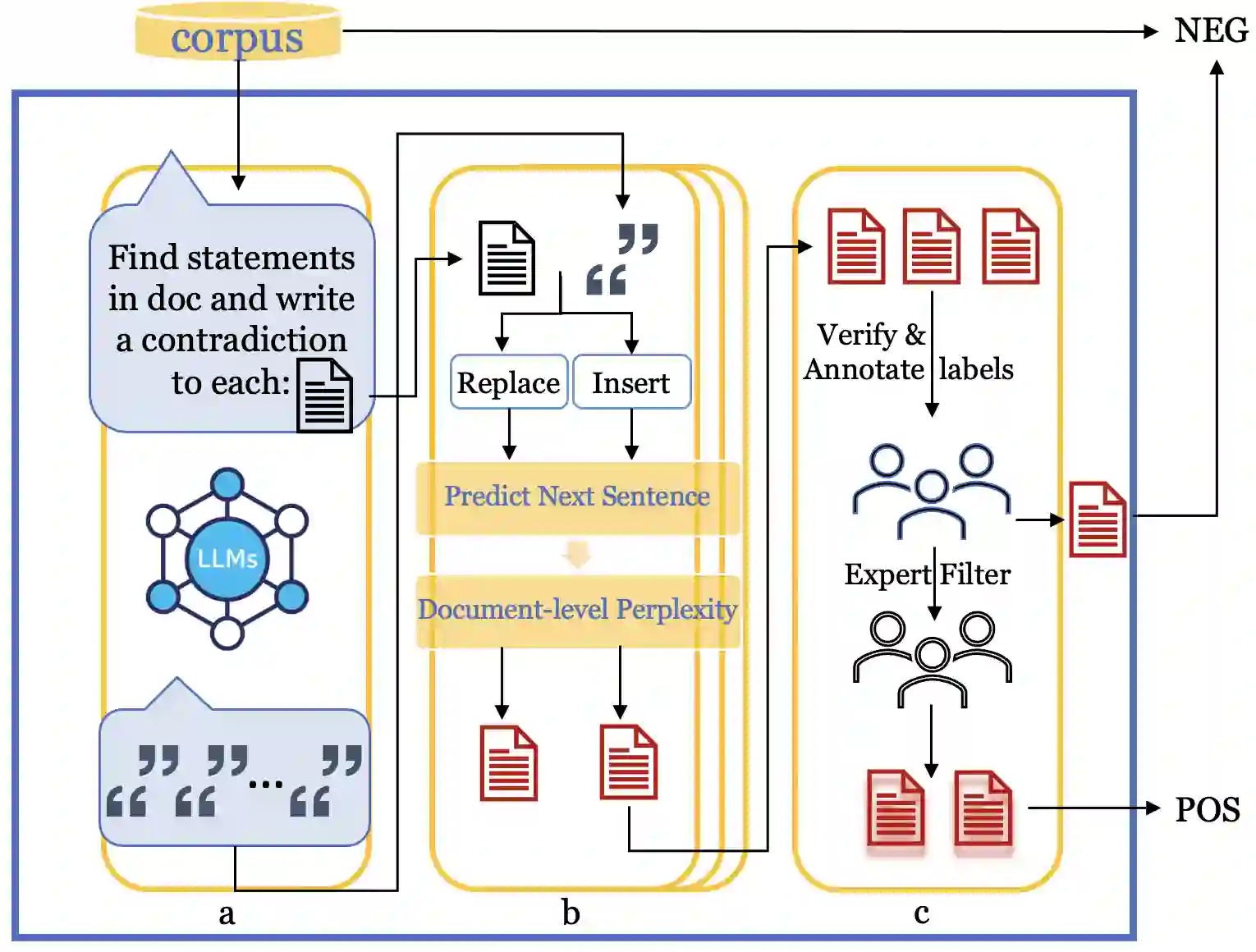
In recent times, large language models (LLMs) have shown impressive performance on various document-level tasks such as document classification, summarization, and question-answering. However, research on understanding their capabilities on the task of self-contradictions in long documents has been very limited. In this work, we introduce ContraDoc, the first human-annotated dataset to study self-contradictions in long documents across multiple domains, varying document lengths, self-contradictions types, and scope. We then analyze the current capabilities of four state-of-the-art open-source and commercially available LLMs: GPT3.5, GPT4, PaLM2, and LLaMAv2 on this dataset. While GPT4 performs the best and can outperform humans on this task, we find that it is still unreliable and struggles with self-contradictions that require more nuance and context. We release the dataset and all the code associated with the experiments.
翻译:近年来,大型语言模型(LLMs)在文档分类、摘要生成和问答等各类文档级任务中展现了卓越性能。然而,针对其在长文档自相矛盾理解任务上的能力研究仍十分有限。本文提出ContraDoc——首个跨多个领域、涵盖不同文档长度、自相矛盾类型与作用范围的人工标注长文档自相矛盾数据集。我们随后分析了四种最先进的开源与商用LLMs(GPT3.5、GPT4、PaLM2和LLaMAv2)在该数据集上的当前能力。尽管GPT4表现最佳且在该任务上可超越人类,但其仍不可靠,且难以处理需要更细致语境理解的矛盾类型。我们已公开发布该数据集及所有实验相关代码。