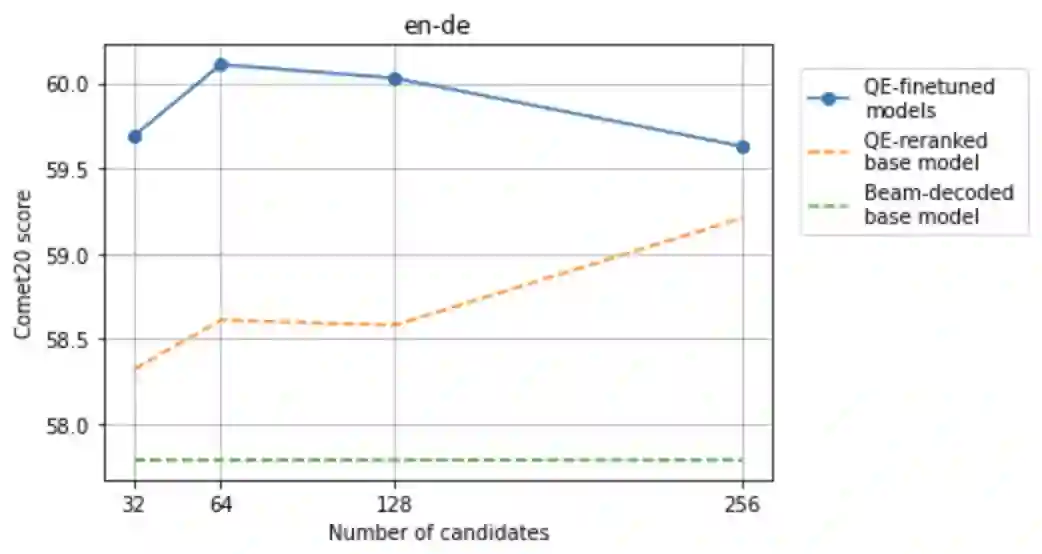
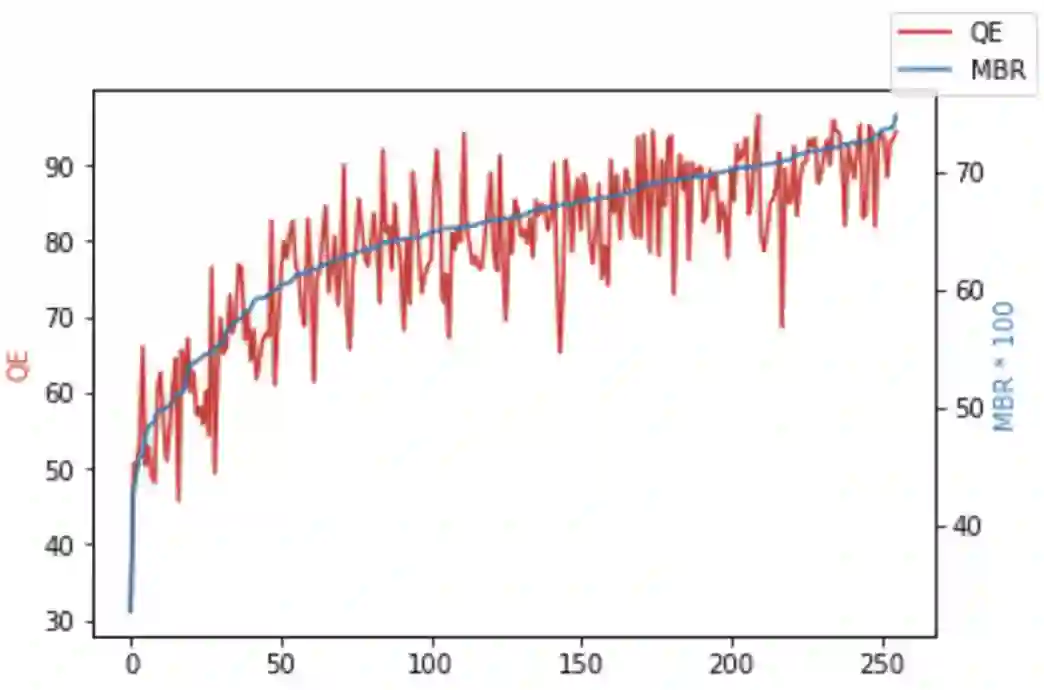
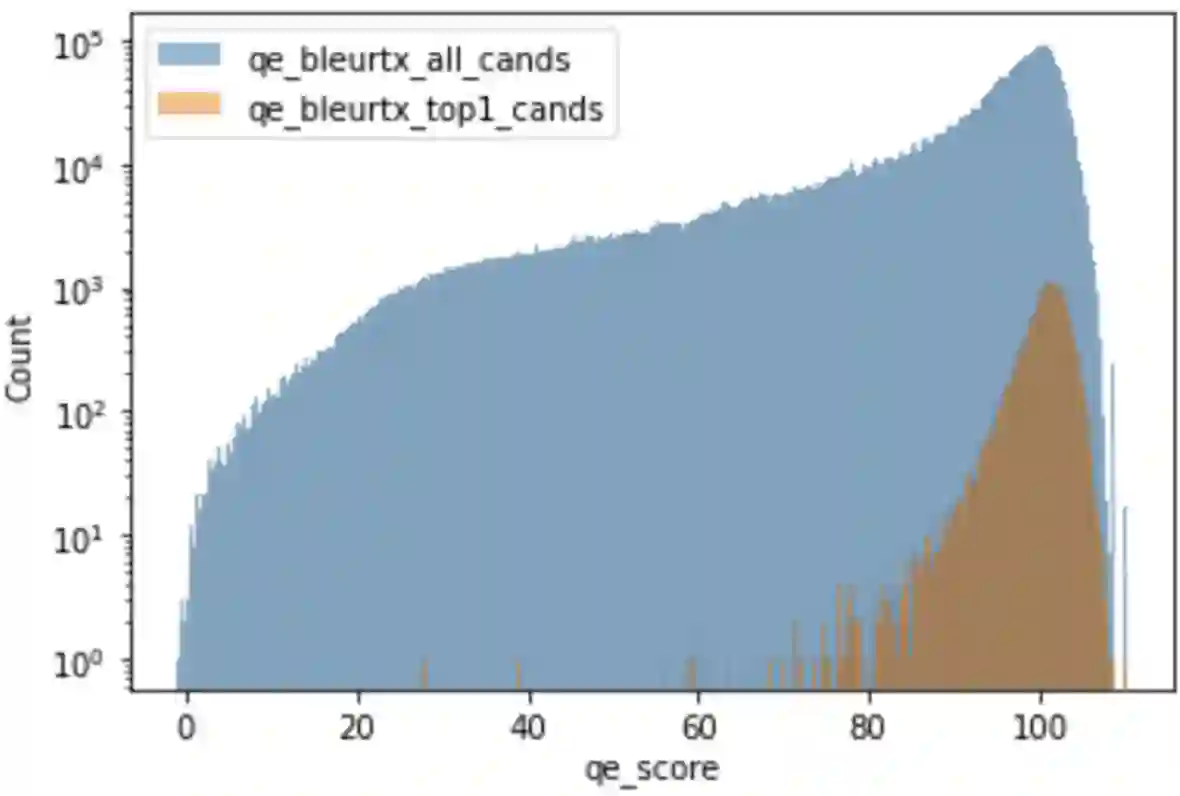
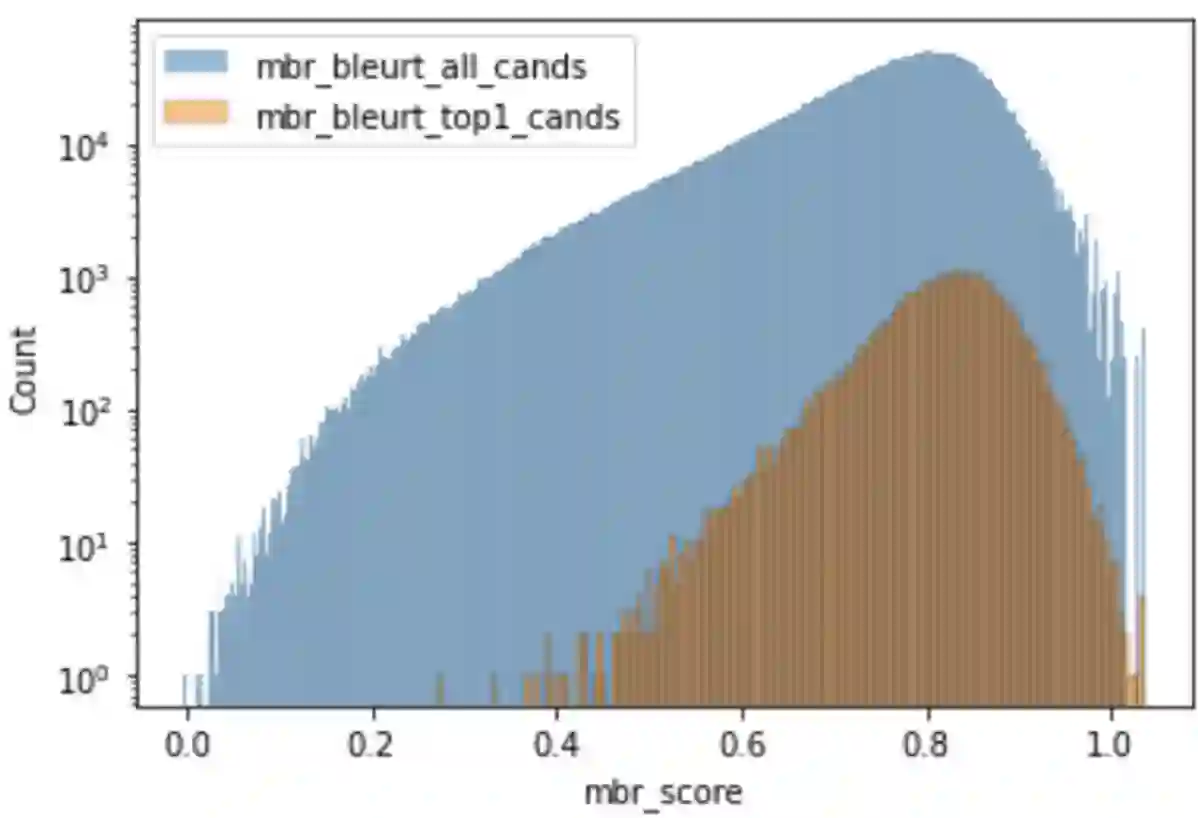
Recent research in decoding methods for Natural Language Generation (NLG) tasks has shown that MAP decoding is not optimal, because model probabilities do not always align with human preferences. Stronger decoding methods, including Quality Estimation (QE) reranking and Minimum Bayes' Risk (MBR) decoding, have since been proposed to mitigate the model-perplexity-vs-quality mismatch. While these decoding methods achieve state-of-the-art performance, they are prohibitively expensive to compute. In this work, we propose MBR finetuning and QE finetuning which distill the quality gains from these decoding methods at training time, while using an efficient decoding algorithm at inference time. Using the canonical NLG task of Neural Machine Translation (NMT), we show that even with self-training, these finetuning methods significantly outperform the base model. Moreover, when using an external LLM as a teacher model, these finetuning methods outperform finetuning on human-generated references. These findings suggest new ways to leverage monolingual data to achieve improvements in model quality that are on par with, or even exceed, improvements from human-curated data, while maintaining maximum efficiency during decoding.
翻译:自然语言生成任务的解码方法近期研究表明,最大后验解码并非最优,因为模型概率并不总能与人类偏好对齐。为此,研究者提出了更强解码方法,包括质量估计重排序和最小贝叶斯风险解码,以缓解模型困惑度与生成质量之间的不匹配。尽管这些解码方法取得了最先进性能,但其计算成本过高。本文提出MBR微调和QE微调,在训练时将上述解码方法的质量增益进行蒸馏,同时在推理阶段采用高效解码算法。以神经机器翻译这一经典NLG任务为例,我们证明即使采用自训练,这些微调方法也显著优于基础模型。此外,当使用外部大语言模型作为教师模型时,这些微调方法的性能优于基于人工生成参考数据的微调。这些发现揭示了利用单语数据的新途径,可实现在解码过程中保持最高效率的同时,获得与人工精选数据相当甚至更优的模型质量提升。